/** * get model depend result * * @param currentTime current time * @return DependResult */ public DependResult getModelDependResult(Date currentTime) {
/** * get date interval list by business date and date value. * * @param businessDate business date * @param dateValue date value * @return date interval list by business date and date value. */ publicstatic List<DateInterval> getDateIntervalList(Date businessDate, String dateValue) { List<DateInterval> result = newArrayList<>(); switch (dateValue) { case"currentHour": result = DependentDateUtils.getLastHoursInterval(businessDate, 0); break; case"last1Hour": result = DependentDateUtils.getLastHoursInterval(businessDate, 1); break; ...... case"last3Days": result = DependentDateUtils.getLastDayInterval(businessDate, 3); break; default: break; } return result;
/** * get last day interval list * @param businessDate businessDate * @param someDay someDay * @return DateInterval list */ publicstatic List<DateInterval> getLastDayInterval(Date businessDate, int someDay) {
List<DateInterval> dateIntervals = newArrayList<>(); for (intindex= someDay; index > 0; index--) { DatelastDay= DateUtils.getSomeDay(businessDate, -index);
/** * get interval between monday to businessDate of this week * @param businessDate businessDate * @return DateInterval list */ publicstatic List<DateInterval> getThisWeekInterval(Date businessDate) { DatemondayThisWeek= DateUtils.getMonday(businessDate); return getDateIntervalListBetweenTwoDates(mondayThisWeek, businessDate); }
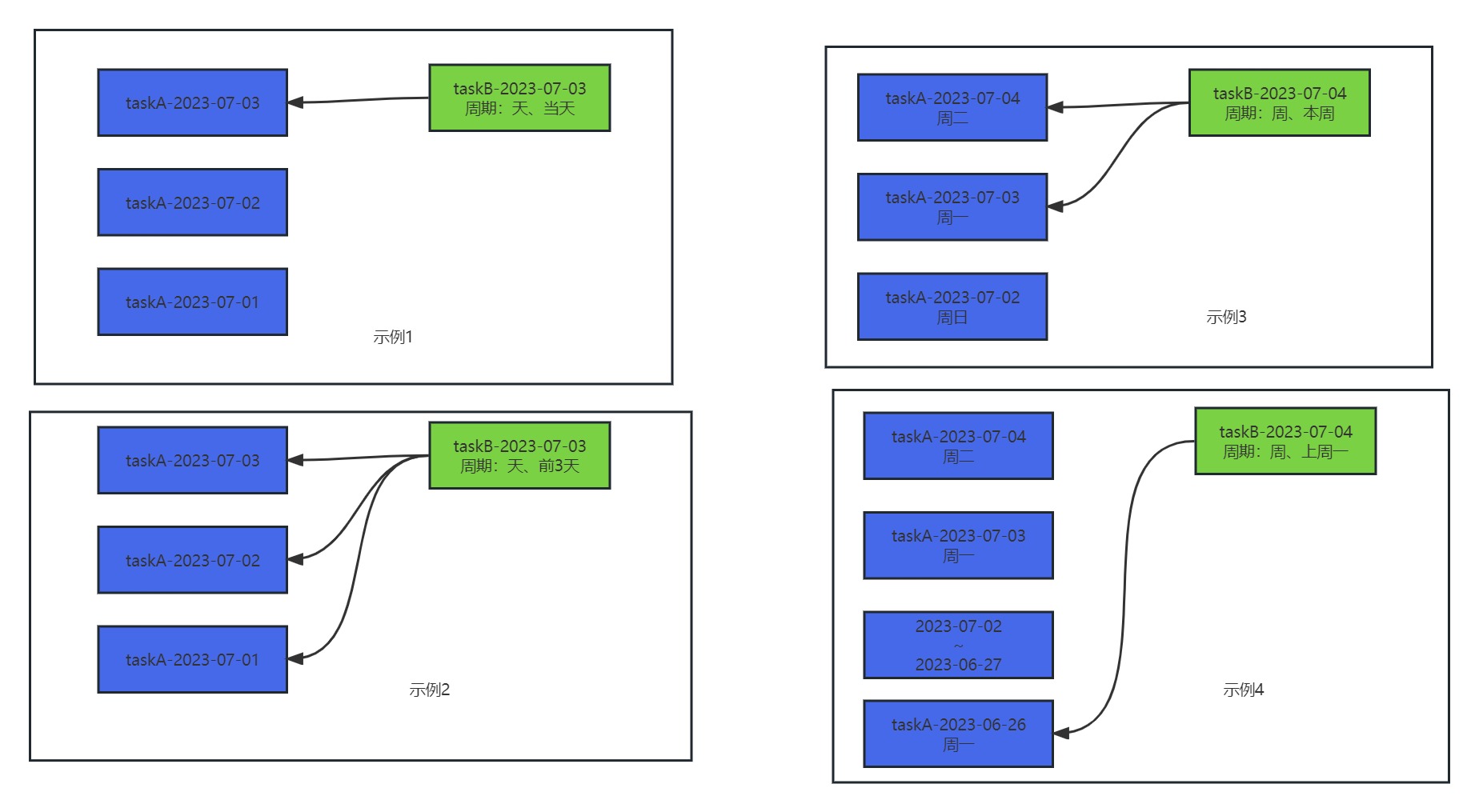
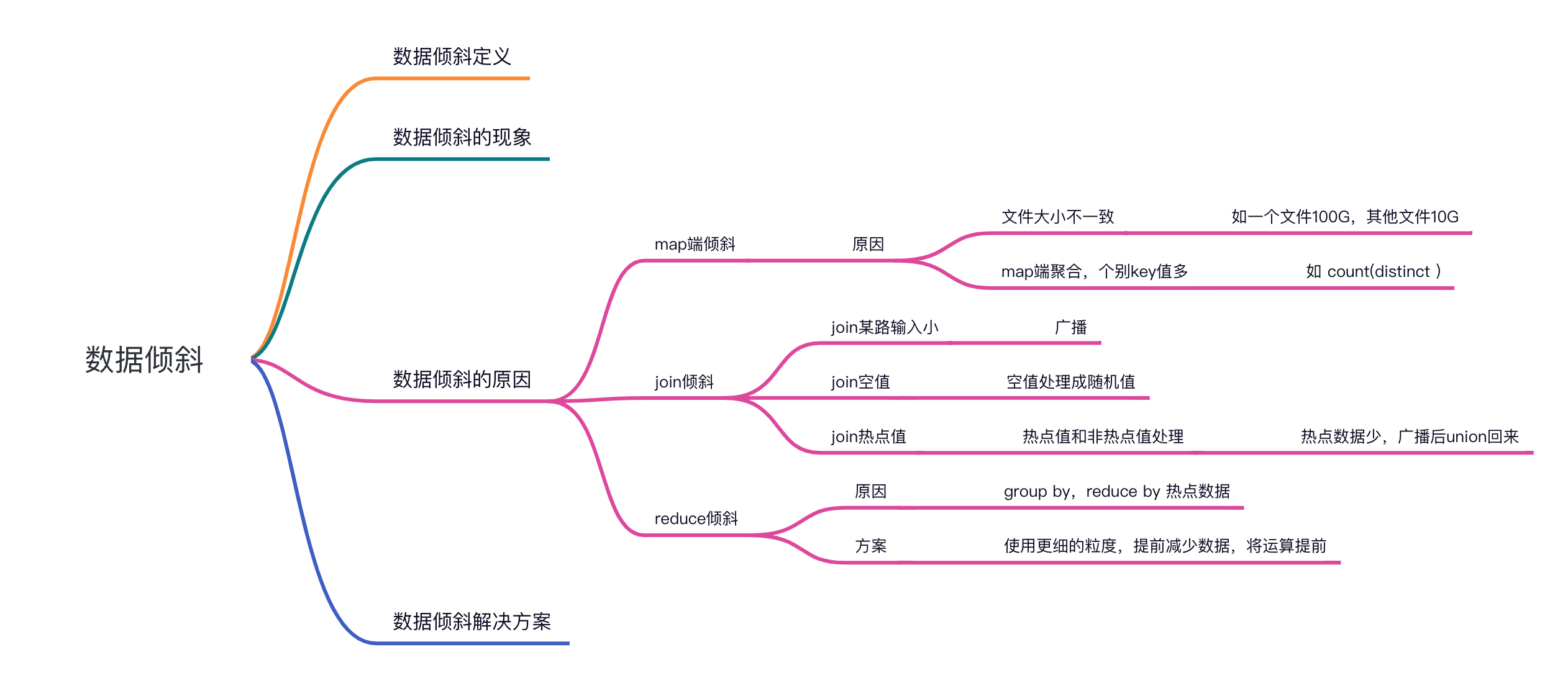
thisWeek获取的则是周一到今天截止的列表 比如”2023-07-03”为周一,获取到的是
2023-07-03 00:00:00 2023-07-03 23:59:59
传入”2023-07-04”为周二,获取到的是
2023-07-03 00:00:00 2023-07-03 23:59:59
2023-07-04 00:00:00 2023-07-04 23:59:59 以此类推
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/** * get interval on the day of last week * default set monday the first day of week * @param businessDate businessDate * @param dayOfWeek monday:1,tuesday:2,wednesday:3,thursday:4,friday:5,saturday:6,sunday:7 * @return DateInterval list */ publicstatic List<DateInterval> getLastWeekOneDayInterval(Date businessDate, int dayOfWeek) { DatemondayThisWeek= DateUtils.getMonday(businessDate); Datesunday= DateUtils.getSomeDay(mondayThisWeek, - 1); Datemonday= DateUtils.getMonday(sunday); DatedestDay= DateUtils.getSomeDay(monday, dayOfWeek - 1); return getDateIntervalListBetweenTwoDates(destDay, destDay); }
/** * calculate dependent result for one dependent item. * * @param dependentItem dependent item * @param dateIntervals date intervals * @return dateIntervals */ private DependResult calculateResultForTasks(DependentItem dependentItem, List<DateInterval> dateIntervals) {
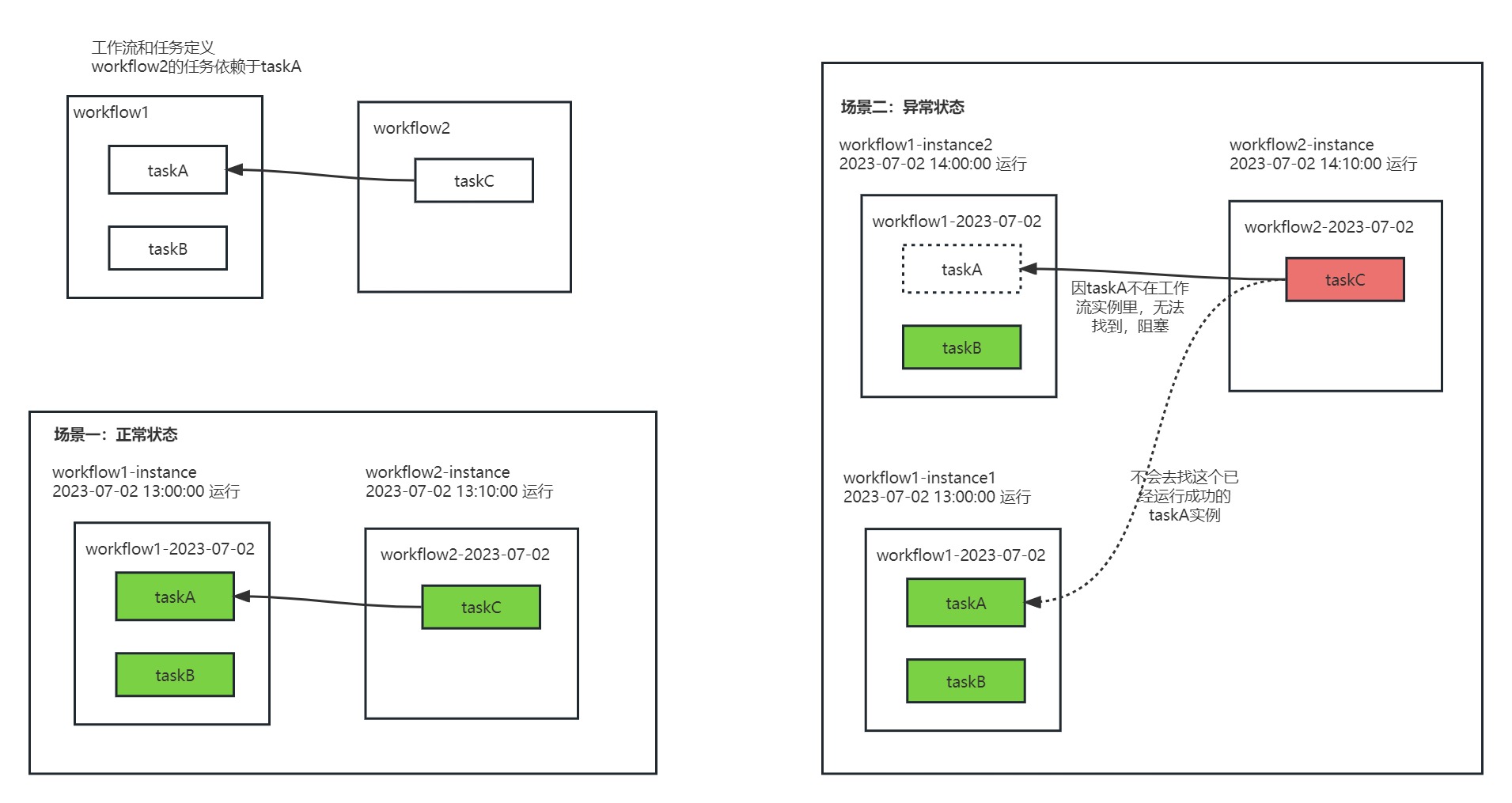
DependResultresult= DependResult.FAILED; for (DateInterval dateInterval : dateIntervals) { ProcessInstanceprocessInstance= findLastProcessInterval(dependentItem.getDefinitionCode(), dateInterval); if (processInstance == null) { return DependResult.WAITING; } // need to check workflow for updates, so get all task and check the task state if (dependentItem.getDepTaskCode() == Constants.DEPENDENT_ALL_TASK_CODE) { result = dependResultByProcessInstance(processInstance); } else { result = getDependTaskResult(dependentItem.getDepTaskCode(), processInstance); } if (result != DependResult.SUCCESS) { break; } } return result; }
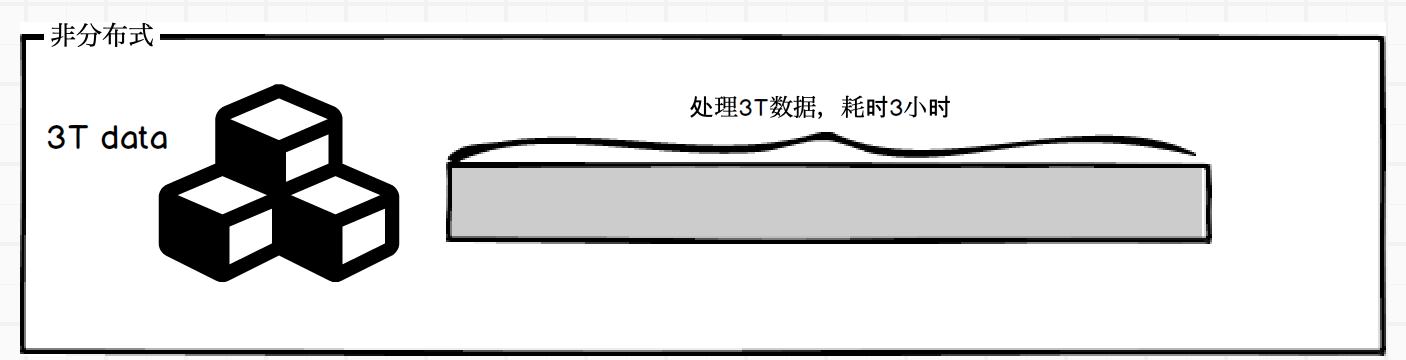
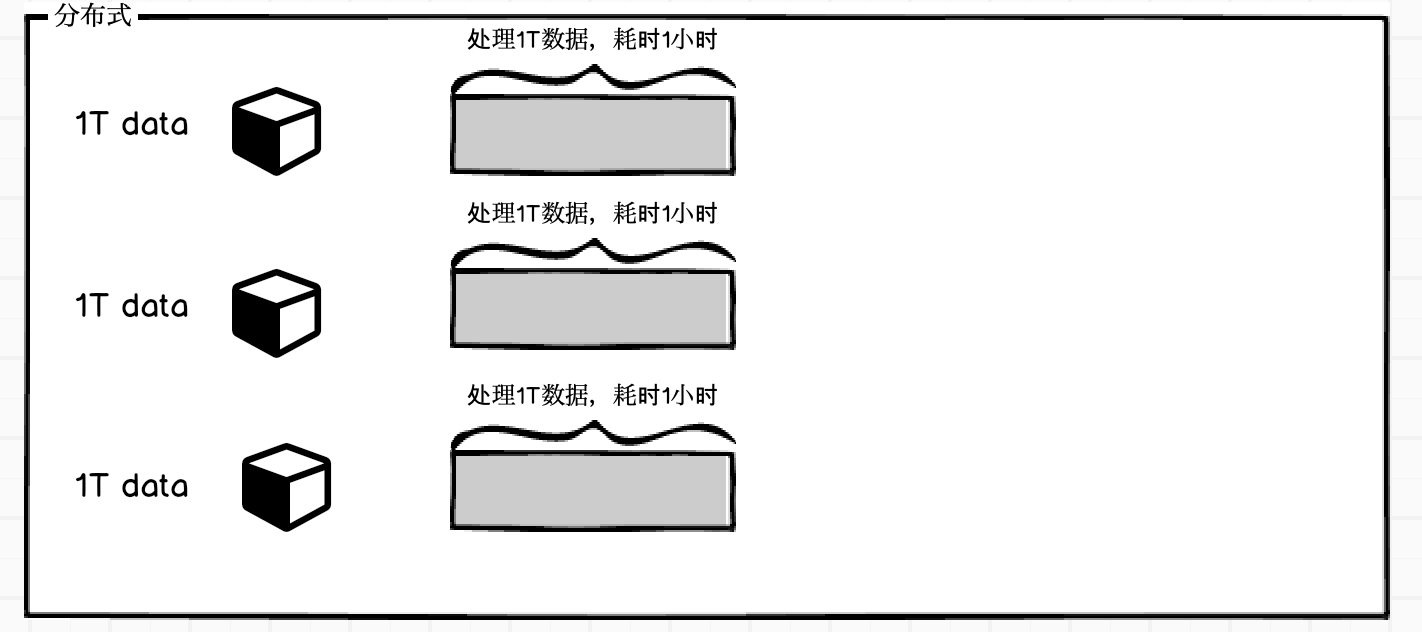
Data skew refers to a phenomenon in distributed systems where the distribution of data across nodes or partitions is uneven. This can result in some nodes having a much larger amount of data to process than others, leading to unequal distribution of workload, longer processing times and reduced performance. 数据偏斜是指分布式系统中数据在节点或分区间分布不均的现象。这可能导致一些节点处理的数据量比其他节点多得多,从而导致工作负载分配不均,处理时间增加以及性能下降。 – by chatGPT
Page segmentation modes: 0 Orientation and script detection (OSD) only. 1 Automatic page segmentation with OSD. 2 Automatic page segmentation, but no OSD, or OCR. (not implemented) 3 Fully automatic page segmentation, but no OSD. (Default) 4 Assume a single column oftextofvariable sizes. 5 Assume a single uniform block of vertically aligned text. 6 Assume a single uniform block oftext. 7 Treat the image asa single textline. 8 Treat the image asa single word. 9 Treat the image asa single wordina circle. 10 Treat the image asa single character. 11 Sparse text. Find as much textas possible in no particular order. 12 Sparse textwith OSD. 13 Raw line. Treat the image asa single textline, bypassing hacks that are Tesseract-specific.
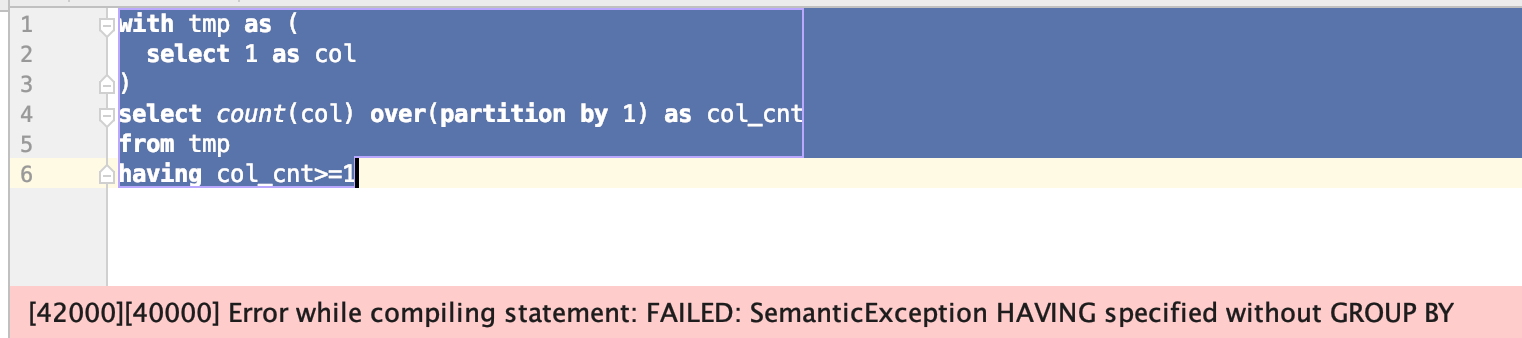
with a as ( select'abc'as a ) ,b as ( select'bdd'as b ) select a.* ,b.* from (select* ,1as col from a )a crossjoin (select* ,1as col from b )b on a.col=b.col
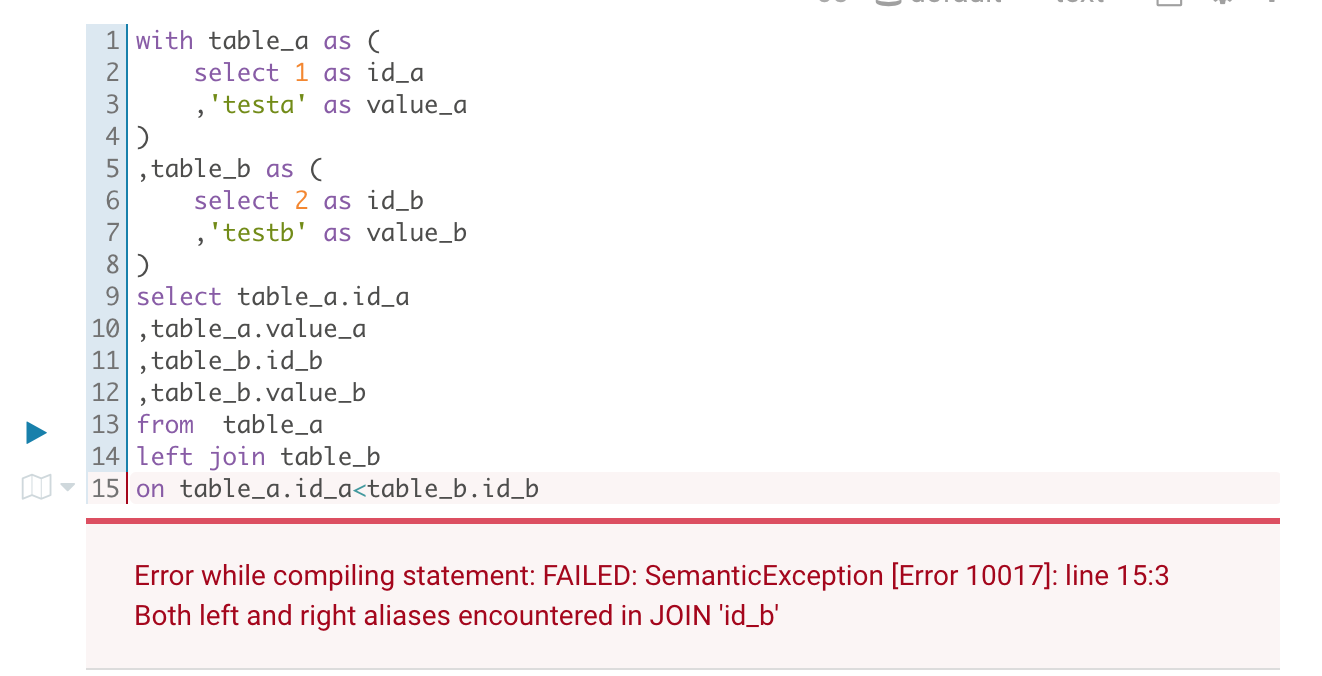
with table_a as ( select1as id_a ,'testa'as value_a ) ,table_b as ( select2as id_b ,'testb'as value_b ) select table_a.id_a ,table_a.value_a ,table_b.id_b ,table_b.value_b from table_a leftjoin table_b on table_a.id_a<table_b.id_b
sql说明 该sql准备了两张表table_a和table_b用于连接测试
使用left join on语法,但是关联关系使用的是 < 不等值关联符号
maxcomputer会报异常:
1
FAILED: ODPS-0130071:[15,4] Semantic analysis exception - expect equality expression(i.e., only use '=' and 'AND')for join condition without mapjoin hint
提示的是期望join的是等值表达式
hive1.2.1运行结果
1
Error while compiling statement: FAILED: SemanticException [Error 10017]: line 15:3 Both left and right aliases encountered in JOIN 'id_b'
提示的是在join中遇到左右别名
不得不说,hive的错误信息有点云里雾里,其实就是不等值join造成的。
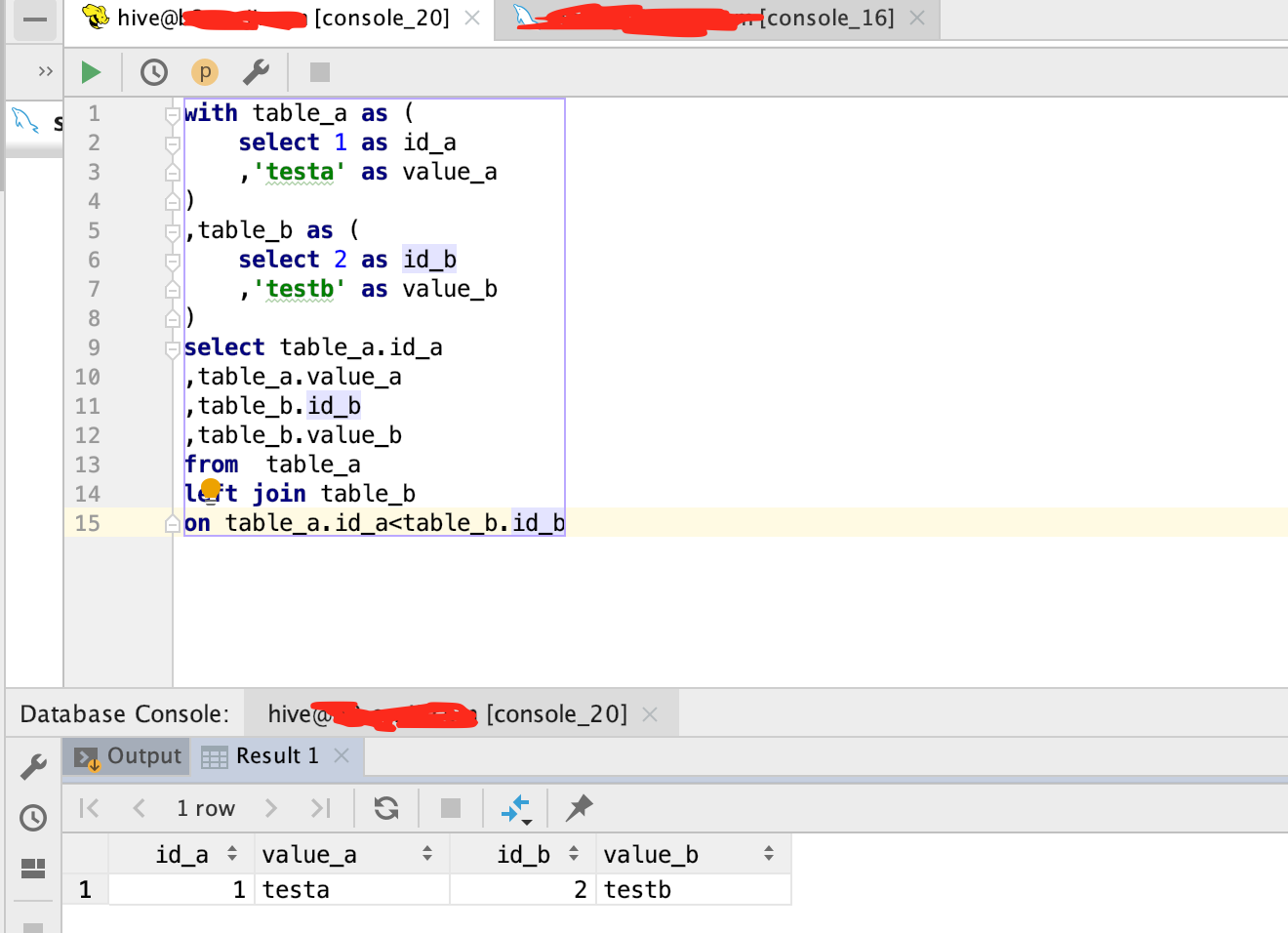
hive2.2.3运行结果
hive 2.2.0+版本顺利得到正确结果
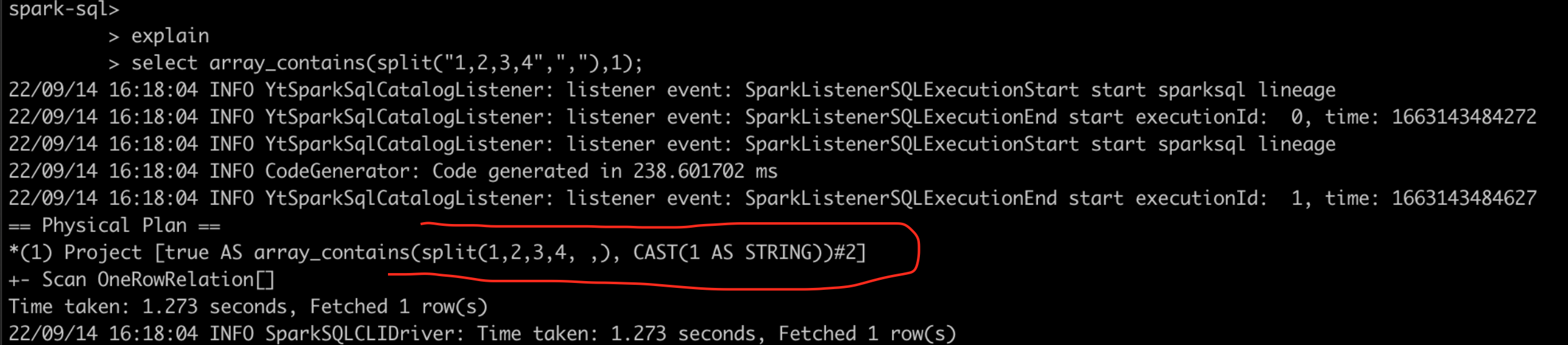
spark运行结果
spark2.3也顺利得到结果
替换方案
针对不等值join的替换方案有两种
1、针对小表,使用mapjoin,避免join操作
针对小表,使用mapjoin,避免join操作 maxcomputer中的mapjoin hint语法为: /*+ mapjoin(<table_name>) */ ,详情请查看mapjoin hint
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
with table_a as ( select1as id_a ,'testa'as value_a ) ,table_b as ( select2as id_b ,'testb'as value_b ) select/*+ mapjoin(table_b) */ table_a.id_a ,table_a.value_a ,table_b.id_b ,table_b.value_b from table_a leftjoin table_b on table_a.id_a<table_b.id_b
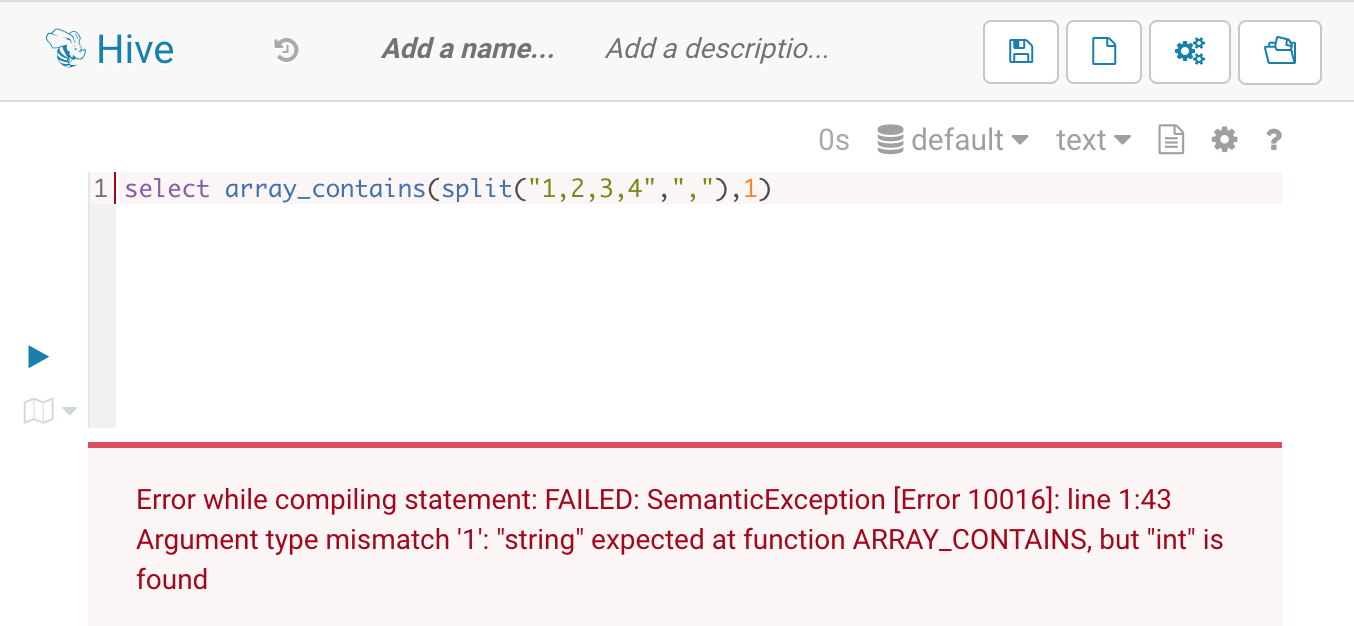
FAILED: ODPS-0130071:[1,44] Semantic analysis exception - invalid type INT of argument 2for function array_contains, expect STRING, implicit conversion is not allowed
Error while compiling statement: FAILED: SemanticException [Error 10016]: line 1:43 Argument type mismatch '1': "string" expected at function ARRAY_CONTAINS, but "int" is found
overridedefeval(input: InternalRow): Any = { val flatInputs = children.flatMap { child => child.eval(input) match { case s: UTF8String => Iterator(s) case arr: ArrayData => arr.toArray[UTF8String](StringType) casenull => Iterator(null.asInstanceOf[UTF8String]) } } UTF8String.concatWs(flatInputs.head, flatInputs.tail : _*) }
可以看到,当传入的是array时,走的是 case arr: ArrayData => arr.toArrayUTF8String ,将原本的array<>转换为array
toArray方法如下:
1 2 3 4 5 6 7 8 9 10 11
deftoArray[T: ClassTag](elementType: DataType): Array[T] = { val size = numElements() val accessor = InternalRow.getAccessor(elementType) val values = newArray[T](size) var i = 0 while (i < size) { values(i) = accessor(this, i).asInstanceOf[T] i += 1 } values }
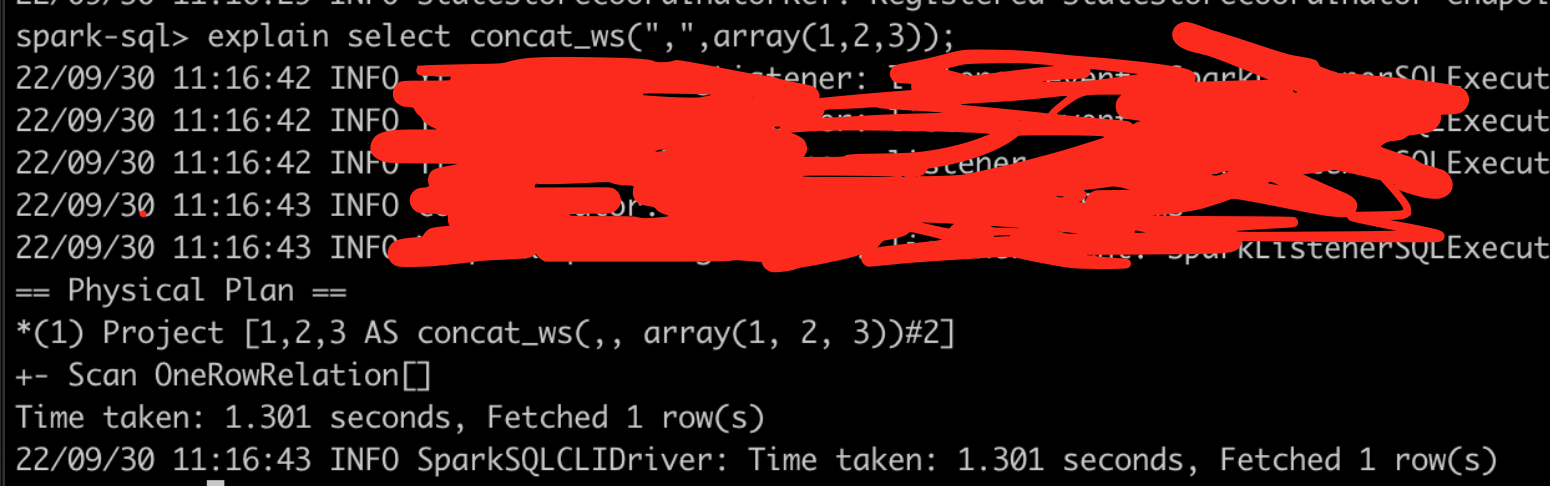
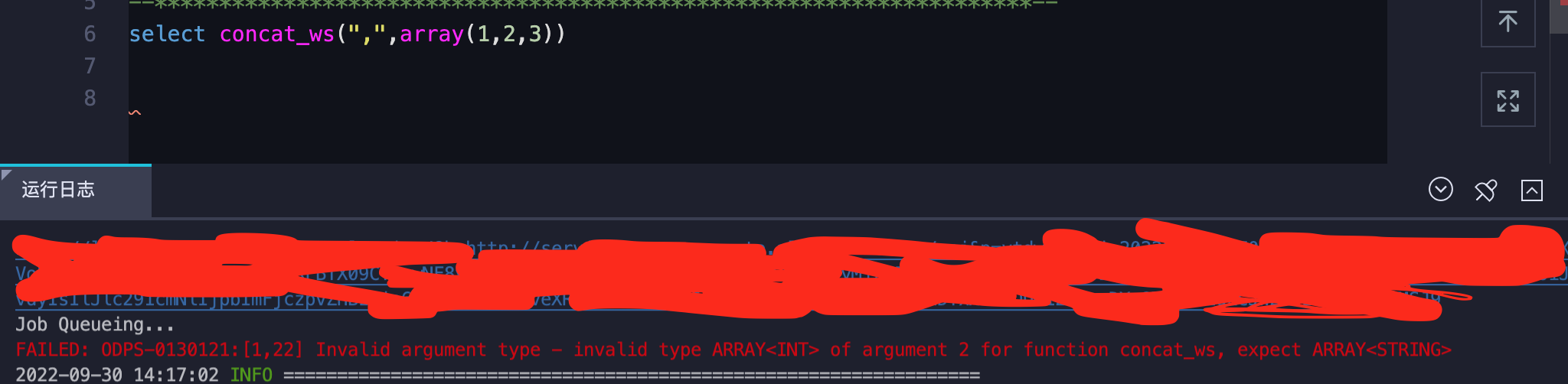
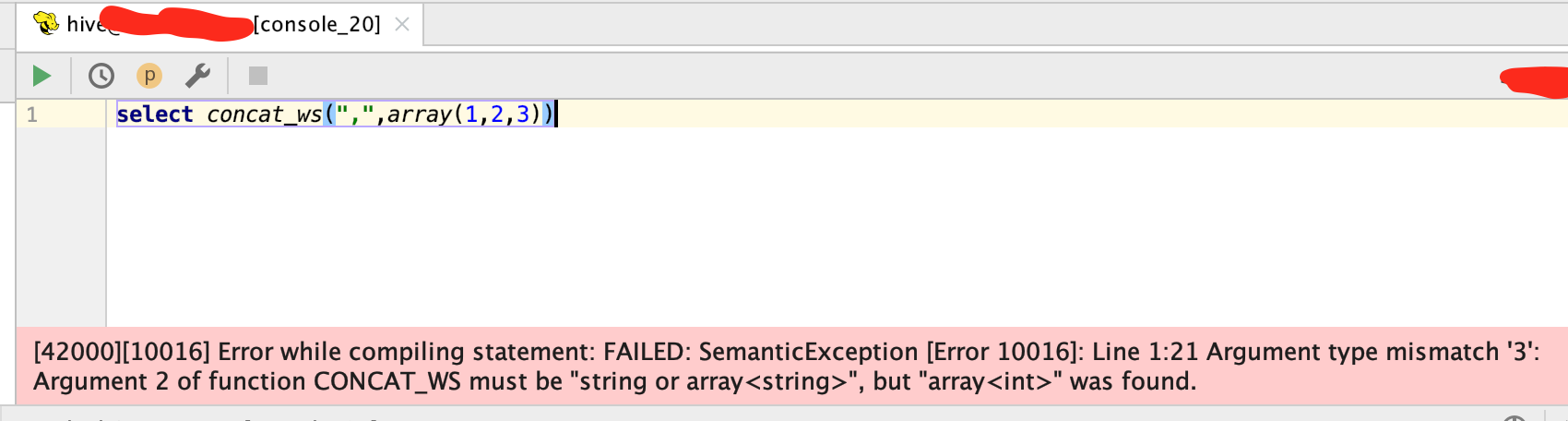
[42000][10016] Error while compiling statement: FAILED: SemanticException [Error 10016]: Line 1:21 Argument type mismatch '3': Argument 2 of function CONCAT_WS must be "string or array<string>", but "array<int>" was found.
select concat_ws(',',collect_list(col_str)) as rs --行转列,并使用concat_ws from (selectcast(col as string) as col_str -- int 转为 string from (select explode(array(1,2,3)) as col -- 列转行 ) t1 ) a
/** * Construct the FSImage. Set the default checkpoint directories. * * Setup storage and initialize the edit log. * * @param conf Configuration * @param imageDirs Directories the image can be stored in. * @param editsDirs Directories the editlog can be stored in. * @throws IOException if directories are invalid. */ protectedFSImage(Configuration conf, Collection<URI> imageDirs, List<URI> editsDirs) throws IOException { this.conf = conf;
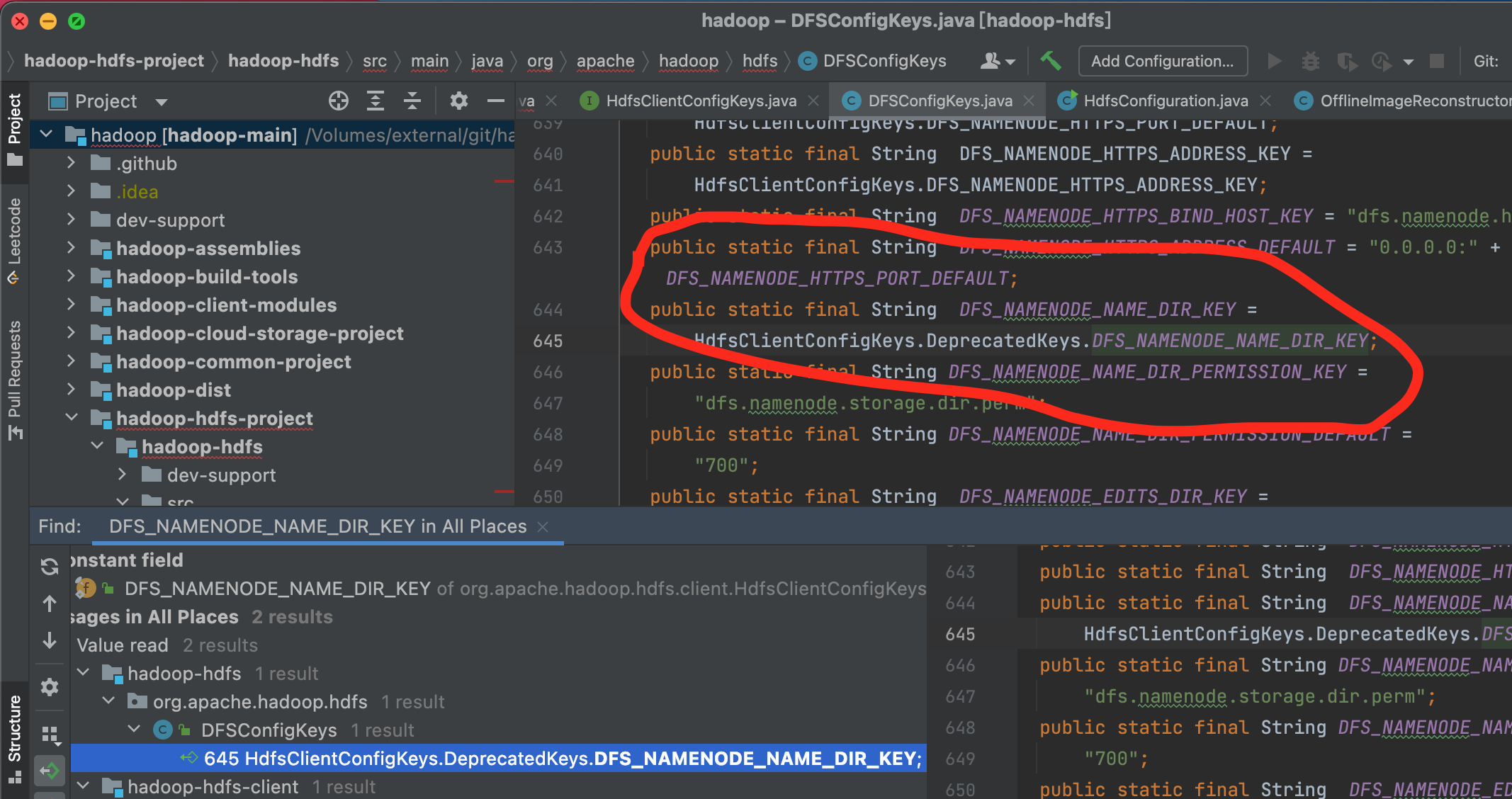
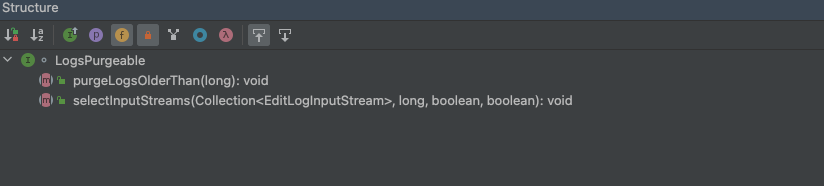
/** * Remove all edit logs with transaction IDs lower than the given transaction * ID. * * @param minTxIdToKeep the lowest transaction ID that should be retained * @throws IOException in the event of error */ publicvoidpurgeLogsOlderThan(long minTxIdToKeep)throws IOException;
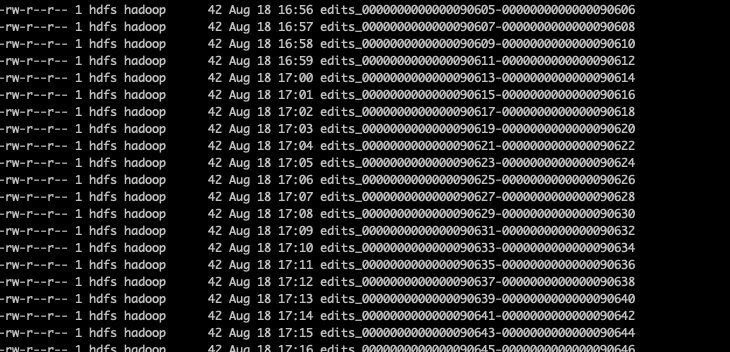
/** * Purges the unnecessary edits and edits_inprogress files. * * Edits files that are ending before the minTxIdToKeep are purged. * Edits in progress files that are starting before minTxIdToKeep are purged. * Edits in progress files that are marked as empty, trash, corrupted or * stale by file extension and starting before minTxIdToKeep are purged. * Edits in progress files that are after minTxIdToKeep, but before the * current edits in progress files are marked as stale for clarity. * * In case file removal or rename is failing a warning is logged, but that * does not fail the operation. * * @param minTxIdToKeep the lowest transaction ID that should be retained * @throws IOException if listing the storage directory fails. */ @Override publicvoidpurgeLogsOlderThan(long minTxIdToKeep) throws IOException { LOG.info("Purging logs older than " + minTxIdToKeep); //获取目录下的所有文件数组 File[] files = FileUtil.listFiles(sd.getCurrentDir()); //从数组中找出属于edit的文件 List<EditLogFile> editLogs = matchEditLogs(files, true); //同步锁 synchronized (this) { //循环遍历 for (EditLogFile log : editLogs) { //如果日志文件的第一个事务txid及最后一个事务txid都比最小保存事务txid小,那么清除该日志 if (log.getFirstTxId() < minTxIdToKeep && log.getLastTxId() < minTxIdToKeep) { //清除日志 purger.purgeLog(log); } elseif (isStaleInProgressLog(minTxIdToKeep, log)) { //不然标记为稳定的日志。 purger.markStale(log); } } } }
privatestaticvoiddeleteOrWarn(File file) { if (!file.delete()) { // It's OK if we fail to delete something -- we'll catch it // next time we swing through this directory. LOG.warn("Could not delete {}", file); } }
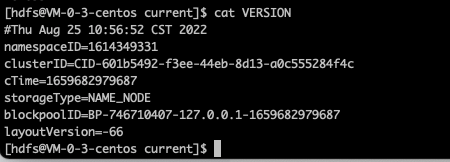
/** * The NNStorageRetentionManager is responsible for inspecting the storage * directories of the NN and enforcing a retention policy on checkpoints * and edit logs. * * It delegates the actual removal of files to a StoragePurger * implementation, which might delete the files or instead copy them to * a filer or HDFS for later analysis. */ publicclassNNStorageRetentionManager {
惯例先看注解
NNStorageRetentionManager 负责检查 NN 的存储目录并对检查点和编辑日志执行保留策略。 它将文件的实际删除委托给 StoragePurger 实现,该实现可能会删除文件或将它们复制到文件管理器或 HDFS 以供以后分析。
longminImageTxId= getImageTxIdToRetain(inspector); purgeCheckpointsOlderThan(inspector, minImageTxId); if (nnf == NameNodeFile.IMAGE_ROLLBACK) { // do not purge edits for IMAGE_ROLLBACK. return; }
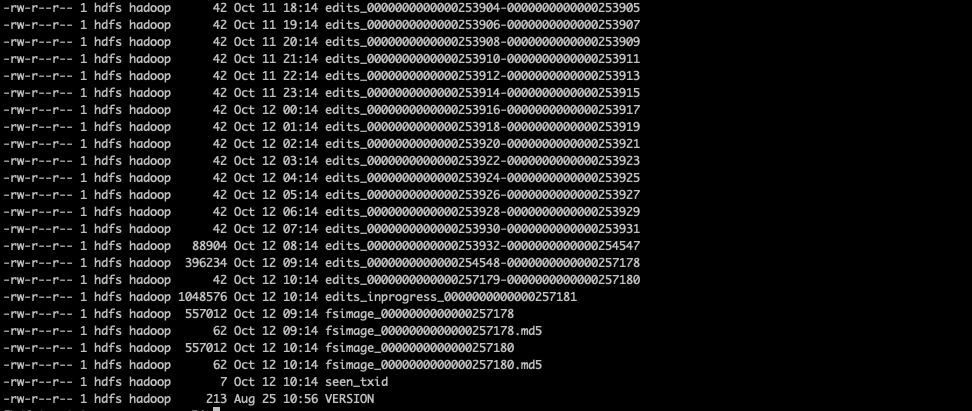
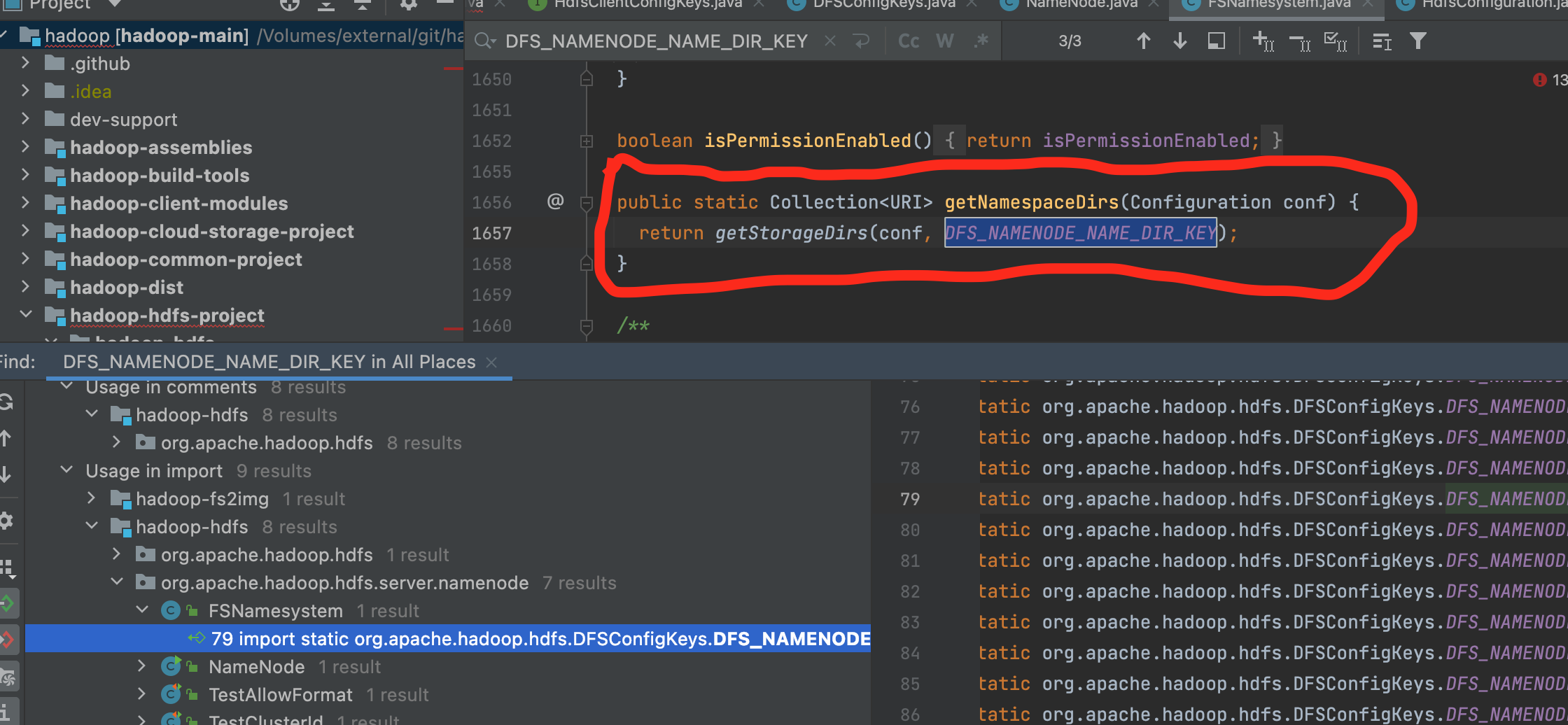
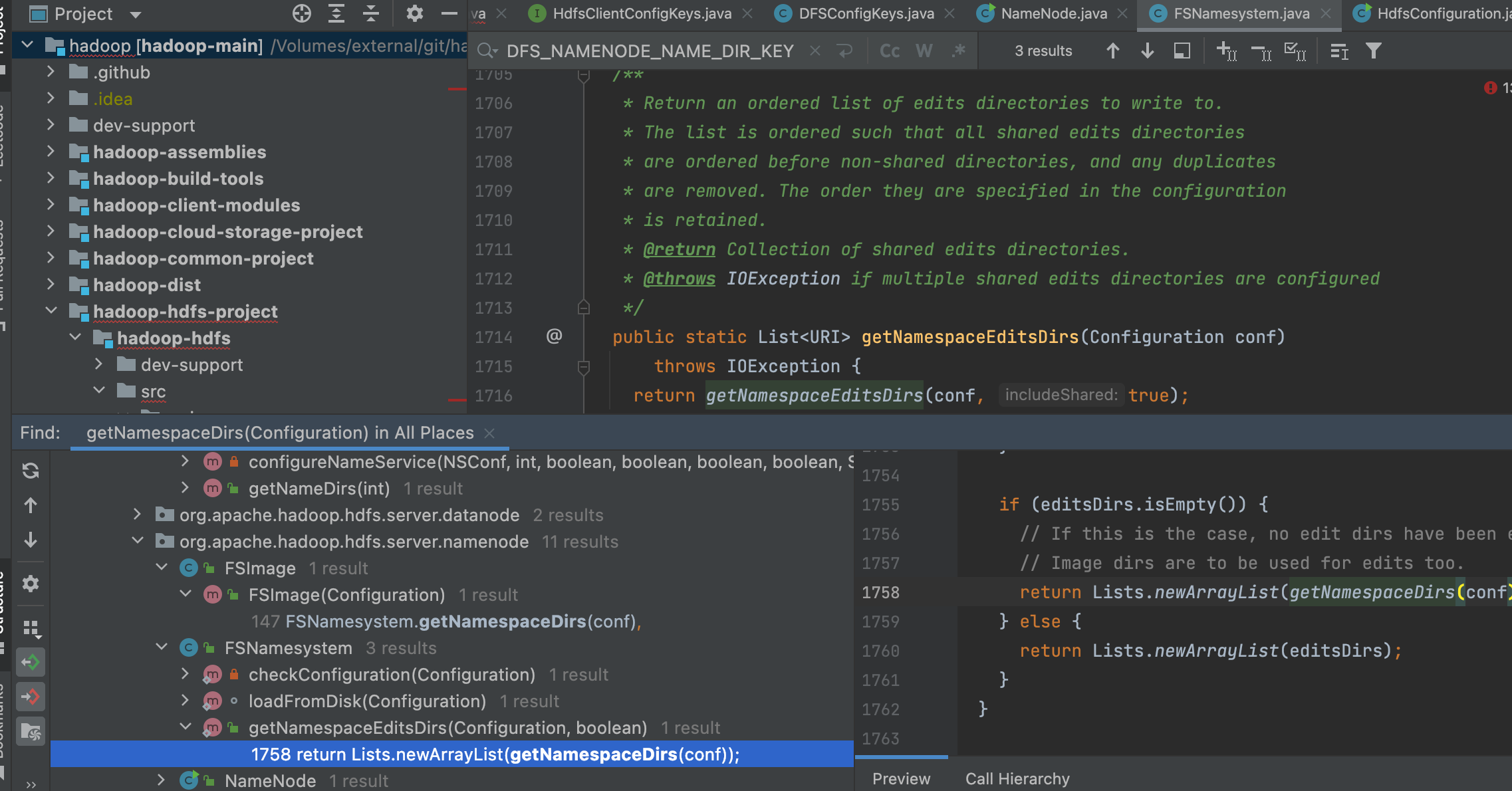
// If fsimage_N is the image we want to keep, then we need to keep // all txns > N. We can remove anything < N+1, since fsimage_N // reflects the state up to and including N. However, we also // provide a "cushion" of older txns that we keep, which is // handy for HA, where a remote node may not have as many // new images. // // First, determine the target number of extra transactions to retain based // on the configured amount. longminimumRequiredTxId= minImageTxId + 1; //最小的日志事务id为: 最小需要保留的事务txid减去需要额外保留的事务id,其中minimumRequiredTxId为检查点镜像文件的最后一条事务id,本质上就是保留numExtraEditsToRetain条事务。 longpurgeLogsFrom= Math.max(0, minimumRequiredTxId - numExtraEditsToRetain); //edit log的文件输入流 ArrayList<EditLogInputStream> editLogs = newArrayList<EditLogInputStream>(); //填充 purgeableLogs.selectInputStreams(editLogs, purgeLogsFrom, false, false); //排序,优先比较第一条事务txid,然后比较最后一条事务txid Collections.sort(editLogs, newComparator<EditLogInputStream>() { @Override publicintcompare(EditLogInputStream a, EditLogInputStream b) { return ComparisonChain.start() .compare(a.getFirstTxId(), b.getFirstTxId()) .compare(a.getLastTxId(), b.getLastTxId()) .result(); } });
// Remove from consideration any edit logs that are in fact required. //如果edit log文件的第一个事务txid比最小需要保留的事务txid大,那么该edit log需要保留,从待editLogs list中移除。 while (editLogs.size() > 0 && editLogs.get(editLogs.size() - 1).getFirstTxId() >= minimumRequiredTxId) { editLogs.remove(editLogs.size() - 1); } // Next, adjust the number of transactions to retain if doing so would mean // keeping too many segments around. //如果editLogs list的条数比需要保留的最大edits文件数多,那么能保留的最小事务id purgeLogsFrom 需要扩大,将purgeLogsFrom 置为该日志的文件事务txid //如果了解前因后果的话,需要清除的日志由两个参数控制,需要保留的事务数量及需要保留的日志文件数,两个是且的关系,只有两个条件都满足的日志才会保留,有一个不满足就会删除,这里其实就是当日志文件数大于需要保留的日志文件数时,多余的日志文件数需要清除。 while (editLogs.size() > maxExtraEditsSegmentsToRetain) { purgeLogsFrom = editLogs.get(0).getLastTxId() + 1; editLogs.remove(0); } // Finally, ensure that we're not trying to purge any transactions that we // actually need. //最后确认下,本次清除的事务id必须比最低要求低,不然抛出异常。 if (purgeLogsFrom > minimumRequiredTxId) { thrownewAssertionError("Should not purge more edits than required to " + "restore: " + purgeLogsFrom + " should be <= " + minimumRequiredTxId); } //调用方法清除,这个前文已经将了 purgeableLogs.purgeLogsOlderThan(purgeLogsFrom); }
The number of extra transactions which should be retained beyond what is minimally necessary for a NN restart. It does not translate directly to file’s age, or the number of files kept, but to the number of transactions (here “edits” means transactions). One edit file may contain several transactions (edits). During checkpoint, NameNode will identify the total number of edits to retain as extra by checking the latest checkpoint transaction value, subtracted by the value of this property. Then, it scans edits files to identify the older ones that don’t include the computed range of retained transactions that are to be kept around, and purges them subsequently. The retainment can be useful for audit purposes or for an HA setup where a remote Standby Node may have been offline for some time and need to have a longer backlog of retained edits in order to start again. Typically each edit is on the order of a few hundred bytes, so the default of 1 million edits should be on the order of hundreds of MBs or low GBs. NOTE: Fewer extra edits may be retained than value specified for this setting if doing so would mean that more segments would be retained than the number configured by dfs.namenode.max.extra.edits.segments.retained.
应该保留的额外事务的数量超出了 NN 重新启动所需的最低限度。它不会直接转换为文件的年龄或保存的文件数量,而是转换为事务的数量(这里“编辑”是指事务)。一个编辑文件可能包含多个事务(编辑)。在检查点期间,NameNode 将通过检查最新的检查点事务值减去此属性的值来确定要保留的编辑总数。然后,它扫描编辑文件以识别不包括计算范围的保留交易的旧文件,并随后清除它们。保留对于审计目的或 HA 设置很有用,其中远程备用节点可能已离线一段时间并且需要保留更长的保留编辑积压才能重新开始。通常,每次编辑大约为几百字节,因此默认的 100 万次编辑应该是数百 MB 或低 GB 的数量级。注意:如果这样做意味着保留的段数多于 dfs.namenode.max.extra.edits.segments.retained 配置的数量,则保留的额外编辑可能少于为此设置指定的值。
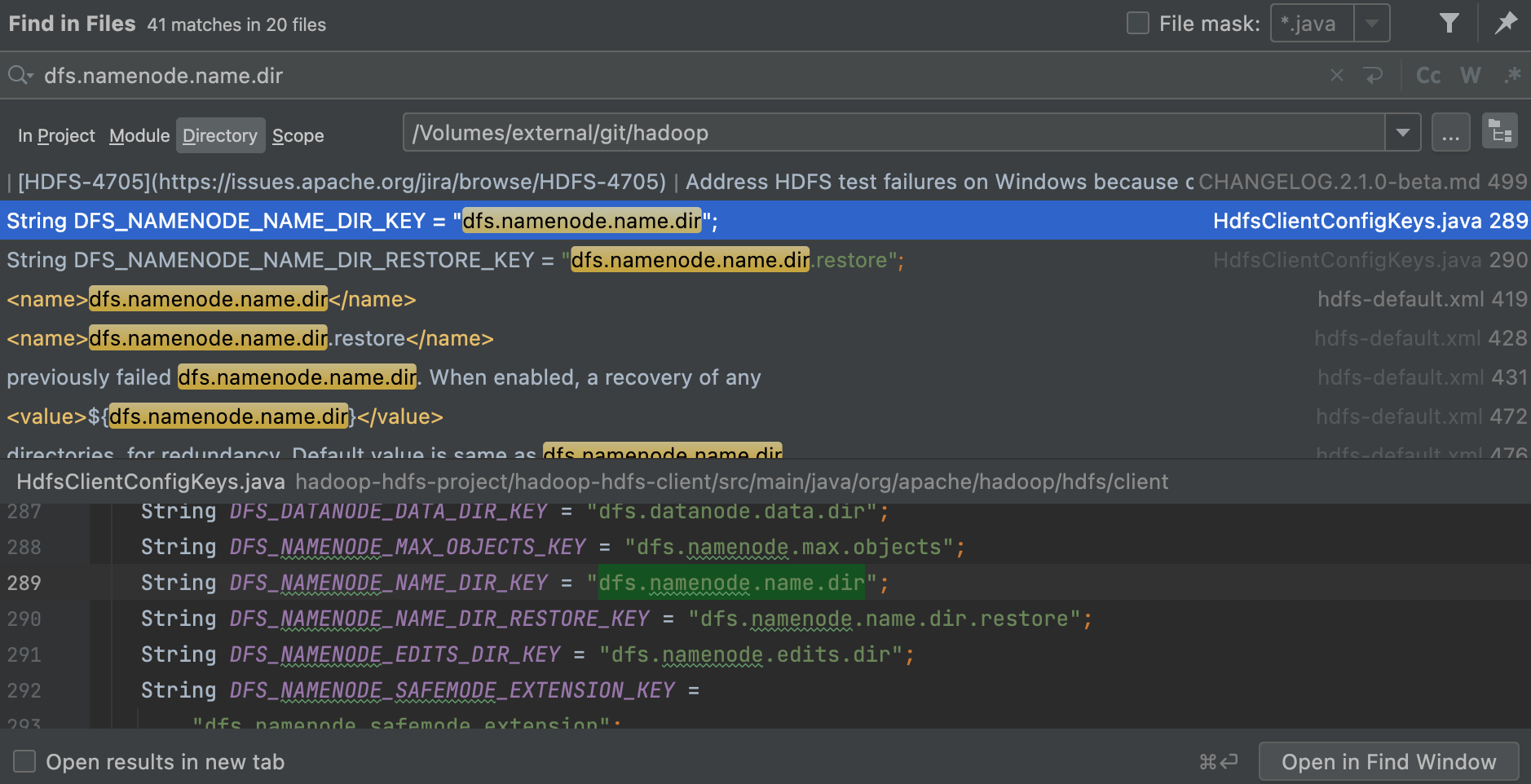
dfs.namenode.max.extra.edits.segments.retained
10000
The maximum number of extra edit log segments which should be retained beyond what is minimally necessary for a NN restart. When used in conjunction with dfs.namenode.num.extra.edits.retained, this configuration property serves to cap the number of extra edits files to a reasonable value.
应该保留的额外编辑日志段的最大数量超出了 NN 重新启动所需的最低限度。 当与 dfs.namenode.num.extra.edits.retained 一起使用时,此配置属性用于将额外编辑文件的数量限制为一个合理的值