dolphinscheduler 中依赖节点 实现天调度任务依赖周任务
背景
最近在使用dolphinscheduler构建数仓的任务流,有一个场景是天周期调度依赖周周期调度任务。
经过一番搜索后,发现dolphinscheduler有一个任务类型叫做依赖节点,但是ds的文档写的较为简略。
不得已翻看源码,最后发现不支持,需要修改源码支持,本文记录留念。
需求
天调度任务依赖周周期调度。
比如,有一个爬虫任务A,每周一10点运行。
后续任务B,每天运行,但是依赖任务A。
基础介绍
dolhpinscheduler简介
参照官网介绍,一句话减少的话,是大数据场景下的任务调度平台。
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
版本
3.1.5
ds 基础相关组件概念介绍
- 任务
ds中运行的最小单元,意义如其名字,任务,主要包含任务的一些定义,路径,参数等。
任务定义: 即任务定义。。。,TaskDefination 对应表 t_ds_task_defination
任务实例: 即运行的任务记录,TaskInstance,对应表 t_ds_task_instance - 工作流
可以理解为可调度的一组任务,包含了一组任务,任务关系,调度配置。
工作流定义: ProcessDefination 对应表 t_ds_process_defination
工作流实例: 即工作流运行记录,ProcessInstance对应 t_ds_process_instance
这里只要重点知道,
1、ds中,任务是不包含具体调度的,具体的调度由工作流维护。
2、一个工作流定义包含多个任务定义
3、一个工作流实例包含多个任务实例
dolphinscheduler中的依赖设计总结。
先说结论
ds中的依赖配置
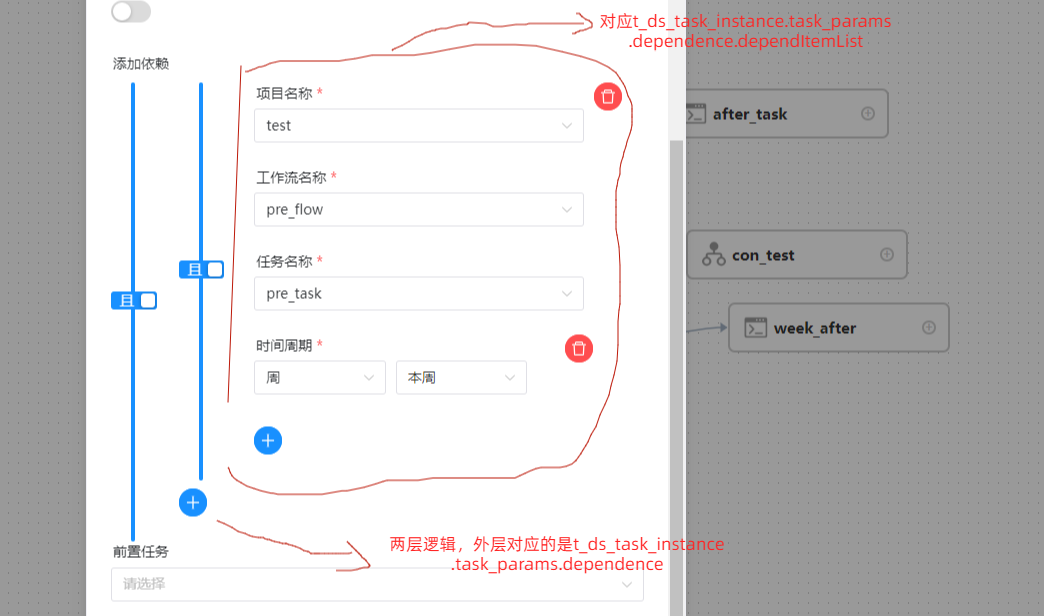
1、ds中的依赖在任务定义中配置,分为两层,每层通过逻辑【且、或】进行连接,整体的一个结构可以理解为
1 | list【 |
通过这种设计,进行复杂的组合,如【A且(B或C)】这种依赖组合。
ds中的依赖选择
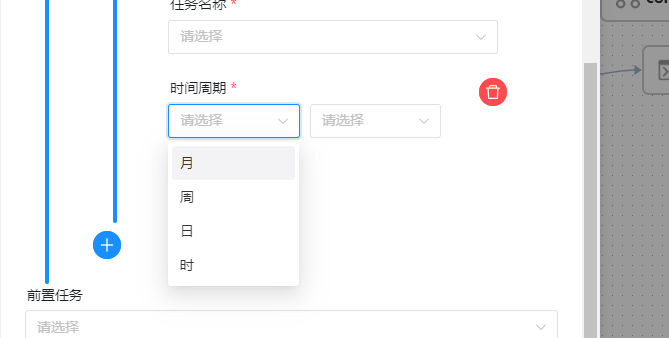
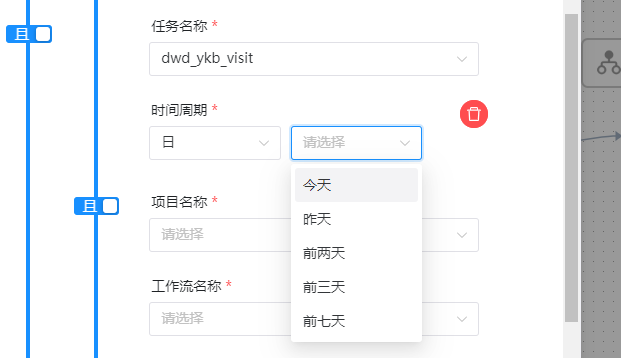
2、ds的时间周期有月、周、日、时,每个周期有不同的选择,几个典型日期为”today”、”last3Days”,”thisWeek”,”lastMonday”,当天,过去三天,本周,上周,当为范围时间时,会将周期拆解到细化度,
如last3Days,则是添加了3天。
比如传入的是”2023-07-03”
那么得到的是
- 2023-07-01 00:00:00 2023-07-01 23:59:59
- 2023-07-02 00:00:00 2023-07-02 23:59:59
- 2023-07-03 00:00:00 2023-07-03 23:59:59
最终的依赖选择如下表格所示
| 周期 | 具体依赖 |
|---|---|
| 月 | 本月 |
| 月 | 本月初 |
| 月 | 上月 |
| 月 | 上月末 |
| 周 | 本周 |
| 周 | 上周 |
| 周 | 上周一~上周日 |
| 日 | 今天 |
| 日 | 昨天 |
| 日 | 前2天~前7天 |
| 时 | 当前小时 |
| 时 | 前1小时~前24小时 |
ds 中的依赖类型
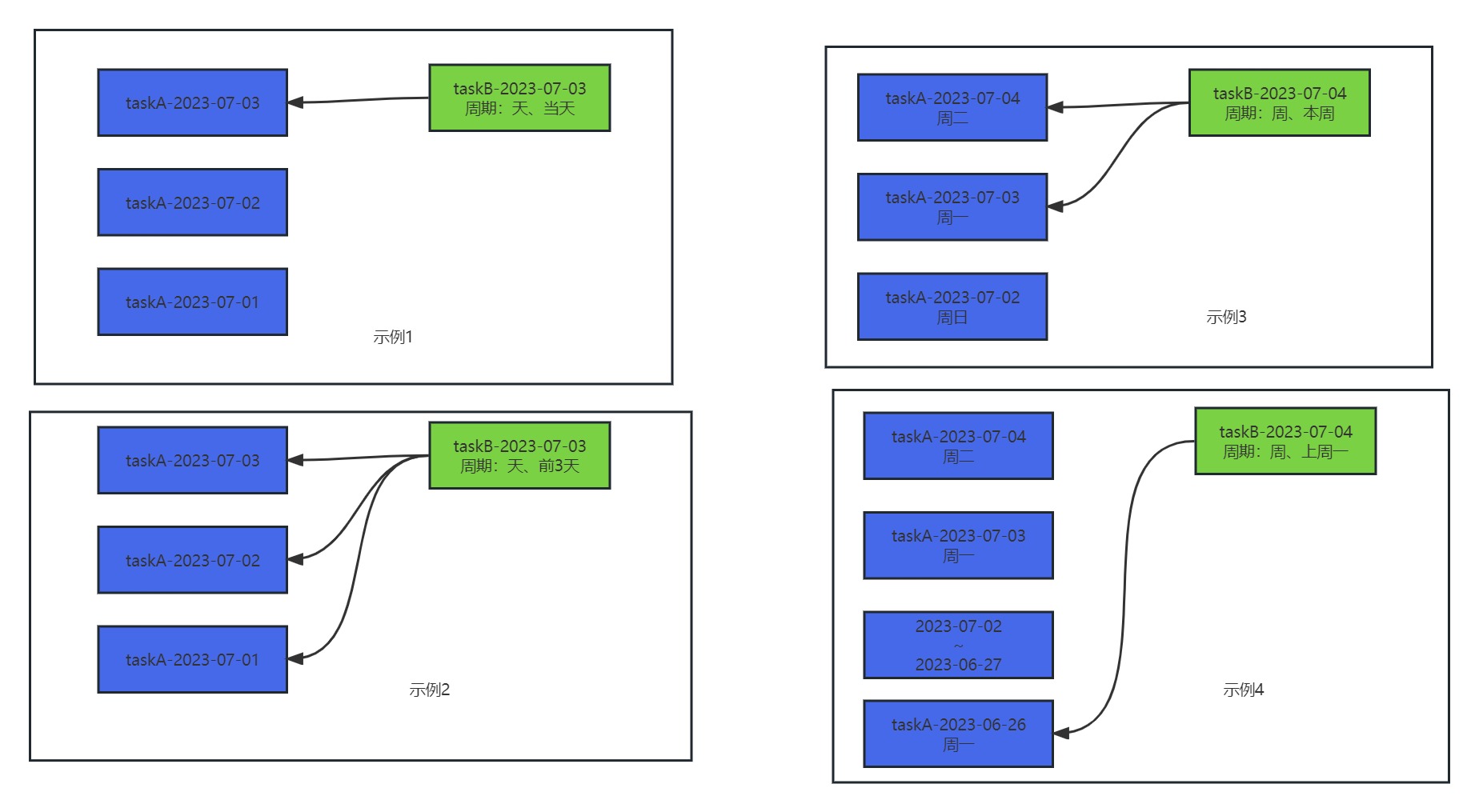
ds中的依赖分为分为两类,一对一依赖和一对多依赖。
- 一对一依赖,指的是只依赖于任务的一个实例
- 一对多依赖,指的是可以依赖于任务的多个实例。
并依托于这两种方式,实现了同周期依赖、跨周期依赖
可以实现天周期任务依赖周周期任务,也可以实现周周期任务依赖天周期任务。
如上图所示
- 示例一为同周期依赖,天的示例
- 示例二为同周期依赖,前三天的示例
- 示例三为本周依赖示例
- 示例4为天周期任务依赖周周期任务,上周一依赖示例。
ds中的依赖判断逻辑
3、ds的依赖判断逻辑主要分为3大步
- 根据时间和工作流code,查询最后一次在业务时间内的工作流实例。
- 根据最后一次工作流实例和依赖任务code,查询对应的任务id。
- 根据运行结果,添加依赖逻辑,判断最后的依赖是否完成。
这里举个例子:
有这样两个任务
workFlow1.A和workFlow2.B
其中workFlow2.B依赖workFlow1.A,周期依赖为过去三天。
比如业务日期为“2023-07-03”这天
这么WorkFlow2.B只有当
workFlow1.2023-07-01,workFlow1.2023-07-02,workFlow1.2023-07-03这三个实例都运行后,且这三个工作流实例都包含A这个任务才会执行
dolphinschduelr中的设计缺陷
这里dolphinschduelr的设计有一个致命缺陷,本人已经验证。因为ds的设计中,调度时间是挂载工作流上的。
而提供的补数功能,支持只运行部分任务。
那么就会导致,部分任务依赖丢失。
举例: 有两个工作流,workFlow1和workFlow2
workFlow1包含A,B两个任务
workFlow2包含一个依赖任务C,该任务依赖workFlow1.A这个任务。
做如下操作:
1、补数workFlow1.A在2023-07-02天的实例,运行workFlow2.C,可以顺利运行
2、补数workFlow1.B在2023-07-02天的实例,运行workFlow2.c,此时workFlow2.C任务会被卡住。
如下图所示。
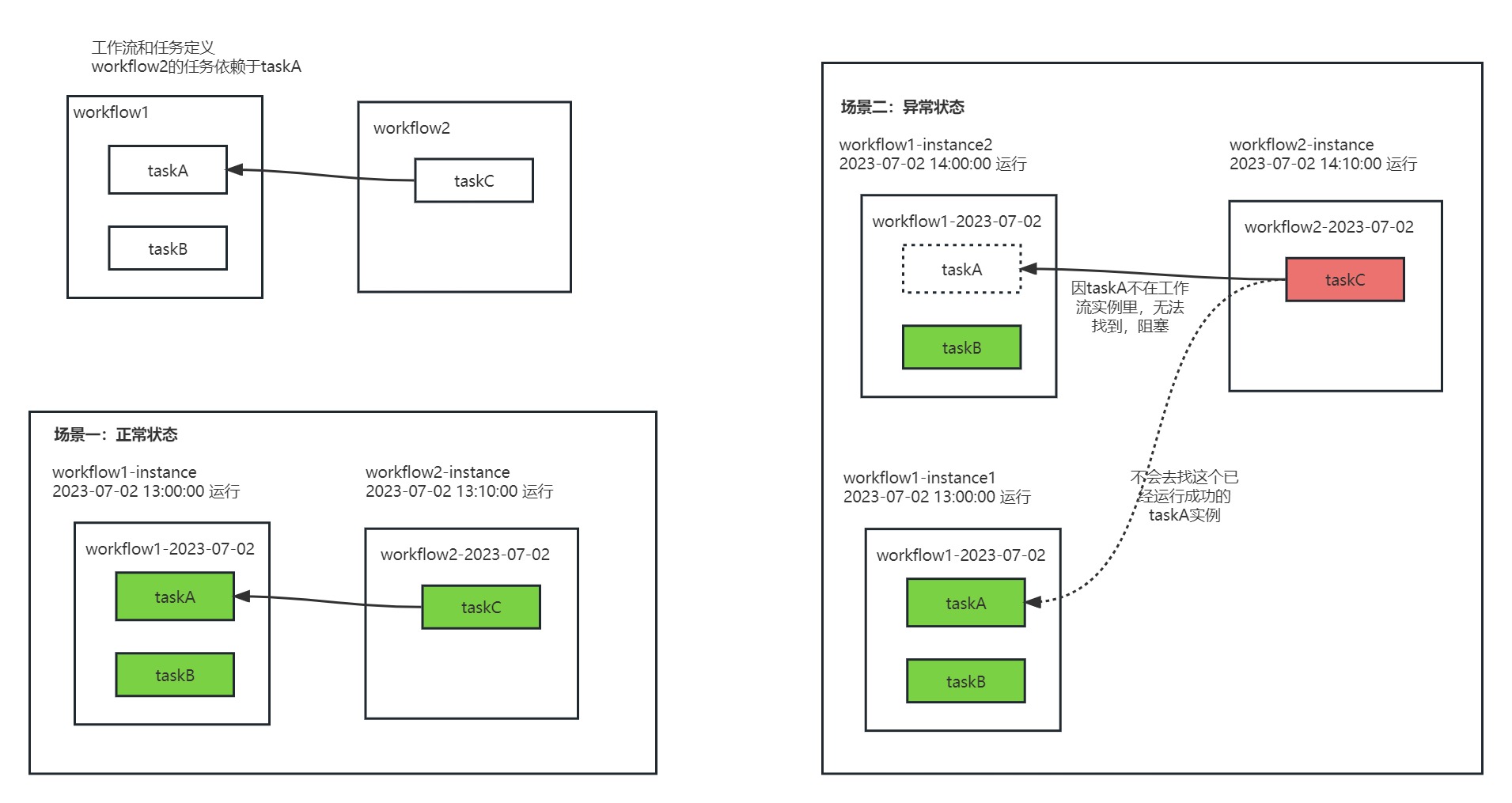
是不是挺无语的,这是因为findLastProcessInterval获取到的是最后一个运行实例,而我们对workFlow1运行了两次,最后以此为操作2,而操作2中不包含任务A的运行实例,最后导致了运行workFlow2.C任务时失败。
你可以说dolphinscheduler在工作流的设计就是需要整个跑的,这样就能避免,但补数一个不相关的任务,导致另一个任务的依赖被无效,就挺无语的。
大家知道就好,避免踩坑。
dolphinscheduler中的依赖任务详解。
那么,ds中依赖具体的逻辑是怎么样的呢?到底支持哪些功能呢?
带着这些疑惑,一起来看代码,最后再来回答这两个问题。
DependentTaskProcessor
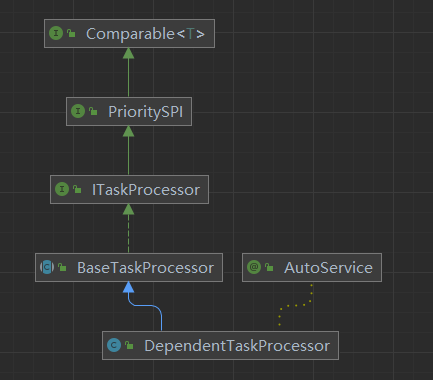
ds中,所有的任务实例都继承自BaseTaskProcessor这个抽象类,该类主要提供了submitTask(),runTask(),killTask()等一系列方法来生产或维护任务运行的实例。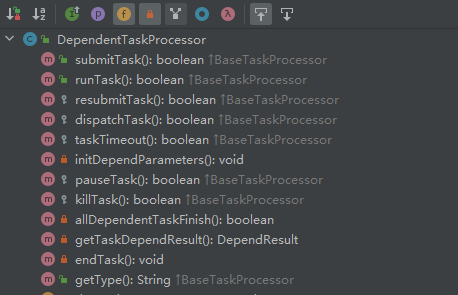
本文的主角,依赖任务DependentTaskProcessor也不例外。
了解ds的依赖逻辑,重点逻辑全在这个DependentTaskProcessor这个类上,看懂了这个类,自然也就了解了ds的依赖逻辑。
DependentTaskProcessor.runTask()
第一站,先来看runTask()是最合适不过的了,了解任务如何运行,自然了解了逻辑
1 |
|
代码比较简单,主要就是三个方法
allDependentTaskFinish() 用于校验所有的依赖任务是否完成,不涉及依赖组合逻辑关系
getTaskDependResult() 用于获取所有的依赖任务结果,涉及依赖组合逻辑关系
endTask() 结束任务,根据任务依赖结果,将状态写入任务实例
allDependentTaskFinish()
首先来看 allDependentTaskFinish() 这个方法
1 | /** |
该方法遍历依赖任务dependentTaskList,将单个任务的依赖结果放入到这个依赖map中,进而判断任务是否完成。
这里看的有点蒙?主要是因为你不了解dependentExecute是什么?dependentTaskList是什么?dependentExecute.getDependResultMap()是什么?让我们结合操作界面,表结构来讲解,看了后自然就理解了。
dependentTaskList和dependentExecute是什么?
dependentTaskList是DependentTaskProcessor的一个属性,该属性是在initDependParameters()初始化依赖节点参数时创建的
1 | this.dependentTaskList.add(new DependentExecute(taskModel.getDependItemList(), taskModel.getRelation())); |
dependentTaskList就是DependentExecute的集合。
DependentExecute则是依赖的抽象,这里传入了taskModel.getDependItemList()进行构造对象,需要理解taskModel.getDependItemList是什么。
1 | for (DependentTaskModel taskModel : dependentParameters.getDependTaskList()) { |
taskModel 是dependentParameters.getDependTaskList(),而dependentParameters对应的则是t_ds_task_instance 这个表的 task_params这个参数。
来看个实例。
1 | { |
看完后,来个对象和字段的对应关系
最重要的dependentItemList对应t_ds_task_instance.task_params.dependence.dependItemList
taskModel对应的则是 t_ds_task_instance.task_params.dependence
再来看下产品截面图进行对应加深印象
可以看到,ds在设计上主要包含两部分,依赖的任务选择,以及逻辑【且、或】的选择。
而逻辑上,设计了两层结构用于复杂逻辑的组合设计,比如【A且B且C】,【A且(B或C)】这样的逻辑。
回到代码,所以本质上,所谓的dependentItem对应的就是选择的一个依赖,外层循环对应的是taskModel,是个list,大概可以表示为list[逻辑,list[depentItem组成]],内层循环对应的则是list[depentItem]。
对应完了,再来回看allDependentTaskFinish方法,dependentExecute.finish(dependentDate),本质就是判断一个一个的所选依赖是否完成。
同时也理解了runTask方法中
allDependentTaskFinish() 用于校验所有的依赖任务是否完成,不涉及依赖组合逻辑关系
getTaskDependResult() 用于获取所有的依赖任务结果,涉及依赖组合逻辑关系
这两个的区别,一个判断只判断结果是否完成,一个结果和逻辑组合是否ok。
dependentExecute.finish(dependentDate)
了解了ds中判断完成的主逻辑,再来进入到细节,了解单个依赖的判断.
1 | /** |
finished方法非常简单,跳getModelDependResult
DependentExecute.getModelDependResult
1 | /** |
也比较简单,遍历DependentExecute.dependItemList,上文中讲过,DependentExecute对应的是内层,即【list[item]】,逻辑,之后通过getDependResultForItem(dependentItem, currentTime)获取单个的运行结果,再结合依赖事项的逻辑关系,返回内层的依赖结果。
DependentExecute.getDependResultForItem
1 | /** |
getDependResultForItem很简单,跳getDependentResultForItem
DependentExecute.getDependentResultForItem
1 | /** |
核心,重点,单个依赖的判断逻辑。
主要分为两步
1、根据传入的业务日期、依赖周期,计算依赖的DateInterval的集合
2、根据获取到的dateInterval的list,查询单个依赖的状态。
DependentUtils.getDateIntervalList(currentTime, dependentItem.getDateValue())
这个方法根据传入的业务日期、依赖周期,计算依赖的DateInterval的集合
要理解如何获取,需要理解两个属性:currentTime和dateValue以及返回DateInterval是什么
currentTime 是什么
在调度上是业务时间,业务时间这里就不展开了,懂得都懂。
对应的字段为t_ds_process_instance.schedule_time
dateValue是什么?
即
上的时间周期,周期可以选择月、周、日、时,对应的期限则可以根据不同的周期选择。
DateInterval 是什么?
1 | /** |
很简单,就两个属性,startTIme和endTime。表示一段时间间隔。
这个会在后面查询工作流实例的时候使用,需要业务时间在表示的时间范围内。
DependentUtils.getDateIntervalList(currentTime, dependentItem.getDateValue())
了解了业务日期、dateValue,dateInterval后,我们再来回到代码
1 | /** |
这里因代码太长,就不写完了,比较简单,根据dateValue,跳转不同逻辑获取List
举几个例子
比如 “today”对应的时间周期选择为:天、当天
“last3Days” 对应的为:天,过去三天
其他以此类推,比较简单,这里我们重点来看下”today”、”last3Days”,”thisWeek”,”lastMonday”这四个来了解ds的依赖周期。
1 | /** |
today非常简单,比如传入”2023-07-03”,那么获取到的为”2023-07-03 00:00:00”到”2023-07-03 23:59:59”这个DateInterval.
1 | /** |
last3Days,则是添加了3天。
比如传入的是”2023-07-03”
那么得到的是
- 2023-07-01 00:00:00 2023-07-01 23:59:59
- 2023-07-02 00:00:00 2023-07-02 23:59:59
- 2023-07-03 00:00:00 2023-07-03 23:59:59
这样一个列表。
1 | /** |
thisWeek获取的则是周一到今天截止的列表
比如”2023-07-03”为周一,获取到的是
- 2023-07-03 00:00:00 2023-07-03 23:59:59
传入”2023-07-04”为周二,获取到的是
- 2023-07-03 00:00:00 2023-07-03 23:59:59
- 2023-07-04 00:00:00 2023-07-04 23:59:59
以此类推
1 | /** |
lastMonday获取的则是本周一一天的数据
比如”2023-07-03”为周一,获取到的是
- 2023-07-03 00:00:00 2023-07-03 23:59:59
传入”2023-07-04”为周二,获取到的是
- 2023-07-03 00:00:00 2023-07-03 23:59:59
以此类推
看到这里,相信大家其实有了自己的猜测,ds根据依赖时间周期,计算出具体的依赖时间,之后查询依赖时间范围内的任务流实例,查看是否有符合的依此来判断是否完成。
calculateResultForTasks
了解了getDateIntervalList,我们再来看下 calculateResultForTasks
1 | /** |
1、遍历前文获取到的dateIntervals,也就是周期对应的具体业务日期。
2、根据definitionCode【工作流定义id】和dateInterval,查询最后一个工作流实例。
3、根据依赖任务code,在第二部获取到的任务实例中查询对应依赖的运行情况
终于来到了最后,这里具体的代码调整就补贴了,直接说最后对应的sql
findLastProcessInterval最后调用ProcessInstanceMapper.queryLastSchedulerProcess()方法,对应的sql为
1 | select |
即根据前文计算的dateInterval,查询schedule_time调度时间在这个周期内的,根据end_tiem倒序。
比如传入”2023-07-03”today,那么运行的则是 scheduler_time>=’2023-07-03 00:00:00’ and scheduler_time<=’2023-07-03 23:59:59’
最后再来看下getDependTaskResult方法,最后核心调用TaskIntanceMapper.findValidTaskListByProcessId方法,对应的sql为
1 | select |
即在上一步获取到的工作流实例中,查看归属于该工作流的任务实例。
至此,所有的判断逻辑已经梳理完毕
dolphinscheduler 支持周周期任务依赖天任务
了解了ds依赖节点的源码,我们知道了ds对周周期任务依赖天周期任务只支持了上周,回到我们一开始的需求
天调度任务依赖周周期调度。
比如,有一个爬虫任务A,每周一10点运行。
后续任务B,每天运行,但是依赖任务A。
在ds中本周为周期依赖本周一。
因此源码改动非常简单。
1、DependentUtils.getDateIntervalList 增加”thisMonday选项”
1 | public static List<DateInterval> getDateIntervalList(Date businessDate, String dateValue) { |
2、1、DependentDateUtils增减getThisWeekInterval
1 | public static List<DateInterval> getThisWeekInterval(Date businessDate, int dayOfWeek) { |
3、在前端项目中增加选项“本周一”,并传值”thisMonday”
总结
总体来说,dolphinscheduler很优秀,大部分的依赖场景基本都支持了,小部分的通过自己修改源码也可以实现,虽然比不上dataworks等成熟的软件,期待后续更加优秀吧。