hadoop edits日志不删除现象排查
背景
最近自己搭建了一套hadoop 3.3.1的集群用于自己的股票指标计算,发现secondary namenode虽然把edits日志合并到了最新的image,但是历史的edits日志并不会删除,导致在元数据目录ls查看文件时,有很多edits文件。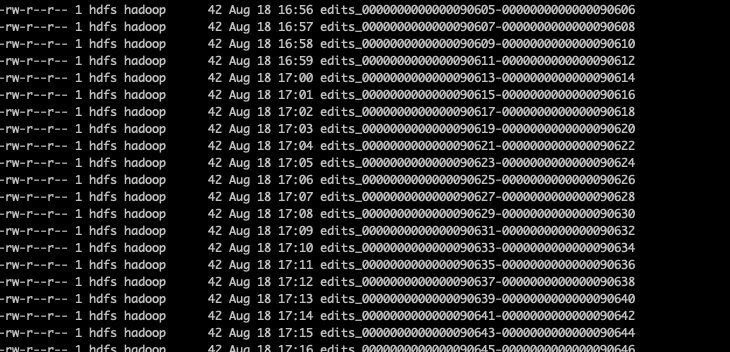
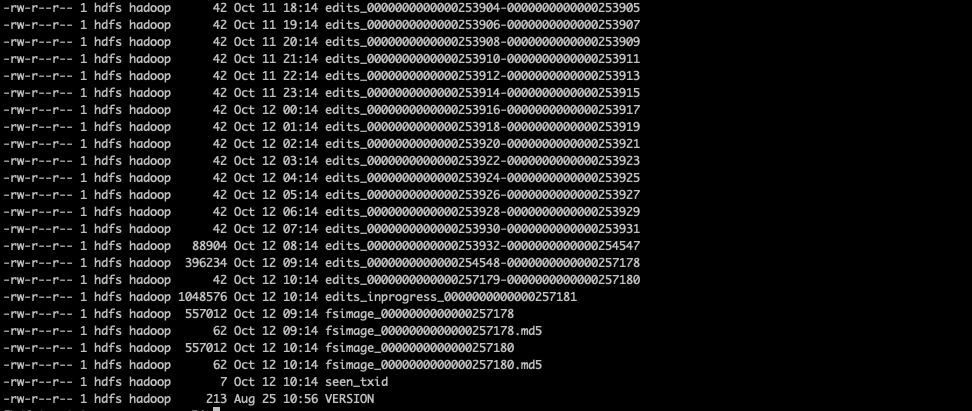
从上图可以看到,当前时间日期为10.8号,但是8.18的edits日志依然没有删除.

通过统计文件数,可以看到一共有10009个文件,扣除VERSION,seen_txid等7个非edits文件,一共有10002个日志文件。
而edits太多,会影响到hadoop的启动。
根据网上相关的文章,在合并完后edits应该会删除,这一现象和了解到的只是相悖,本文为了了解edits啥时候会删除。
元数据各文件详解
从上图的元数据目录查看,可以看到文件分为以下6类
- edits_000xxxx-000xxxx
- edits_inprogress_000xxxx
- fsimage_000xxx
- fsimage_000xxx.md5
- seen.txid
- VERSION
那么,每种文件的作用和功能是什么呢?
具体可以参考本人之前文章: hdfs 中元数据 fsimage,edits详解
edits 文件什么时候删除?
那么,edits文件具体什么时候删除了,这时候就要从源码入手了。
edit log 删除源码探究
1、已知线索: dfs.namenode.name.dir
我们知道,写edits日志需要只要目标文件的目录,而edits日志的存储目录是由hdfs-site.xml文件中的
1 | dfs.namenode.name.dir |
进行指定的,那么这个配置就可以作为线索进行搜索,在hadoop源码中进行搜索dfs.namenode.name.dir
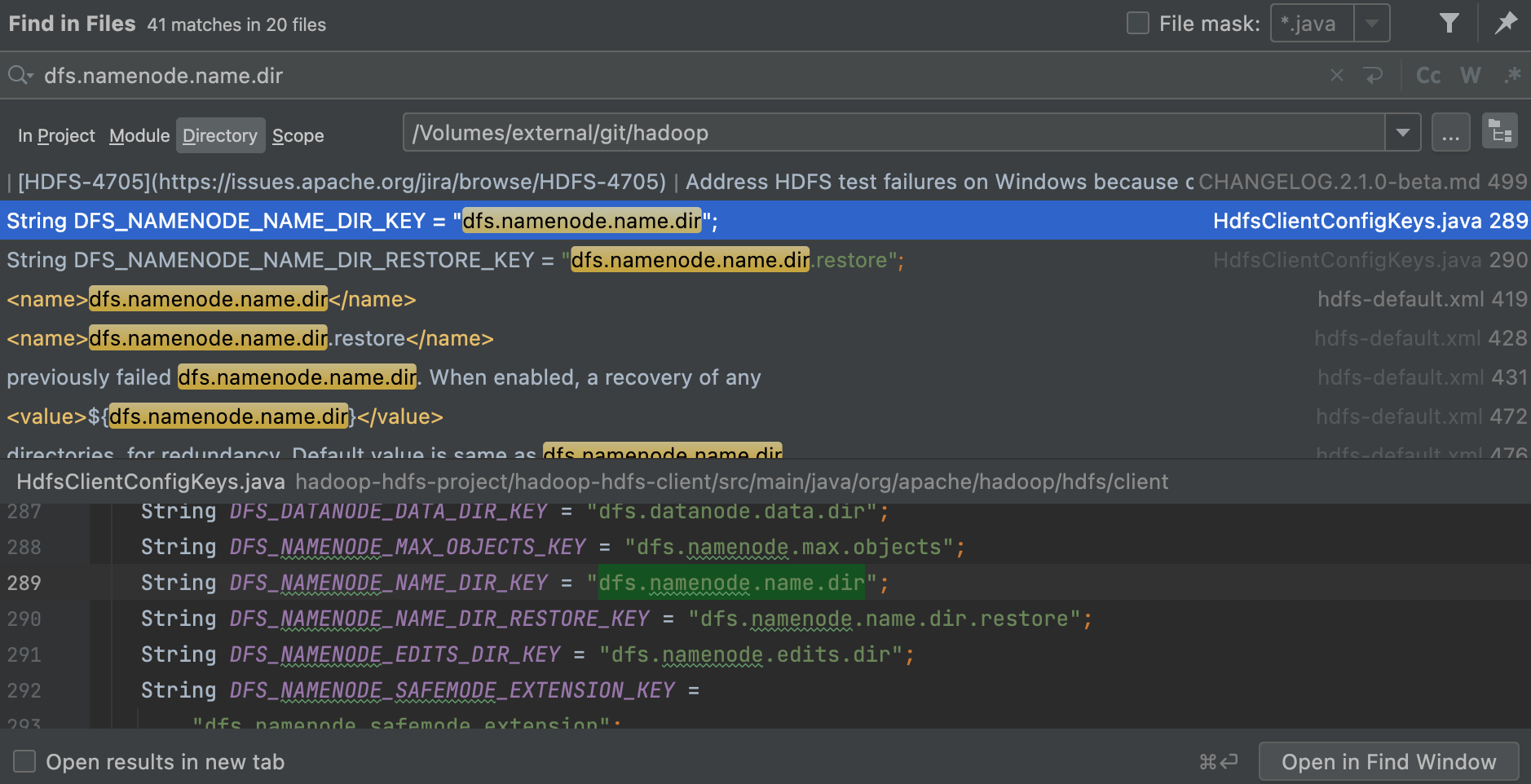
可以看到在HdfsClientConfigKeys类中,使用了变量DFS_NAMENODE_NAME_DIR_KEY来引用dfs.namenode.name.dir
2、查看使用DFS_NAMENODE_NAME_DIR_KEY的代码
使用idea的 find usage功能,来查看 DFS_NAMENODE_NAME_DIR_KEY 被哪些类使用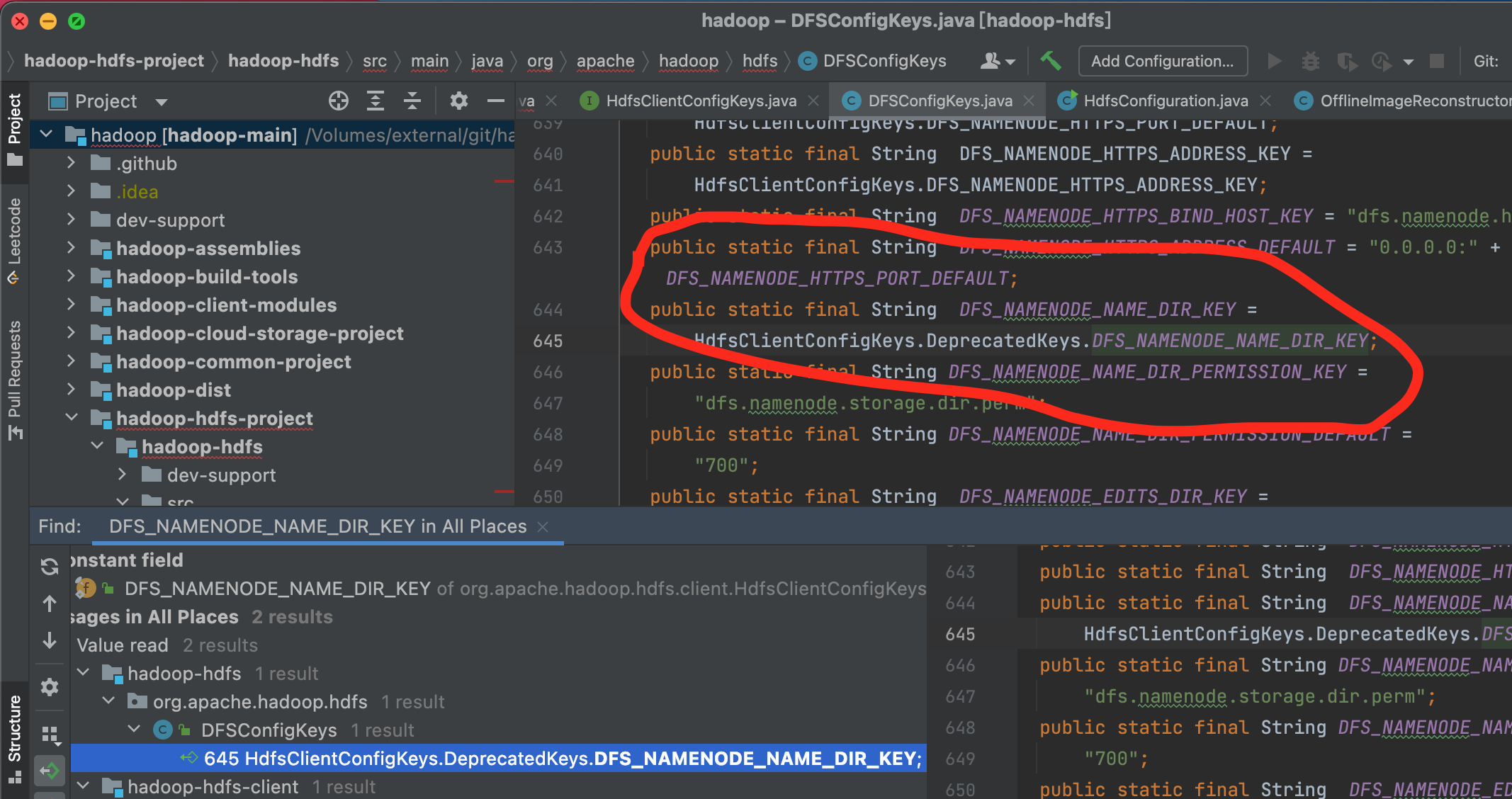
可以看到 在 DfsConfigKeys 中的变量 .DFS_NAMENODE_NAME_DIR_KEY 引用了HdfsClientConfigKeys.DeprecatedKeys.DFS_NAMENODE_NAME_DIR_KEY
3、查看使用DfsConfigKeys.DFS_NAMENODE_NAME_DIR_KEY的代码
使用idea的 find usage功能,来查看 DFS_NAMENODE_NAME_DIR_KEY 被哪些类使用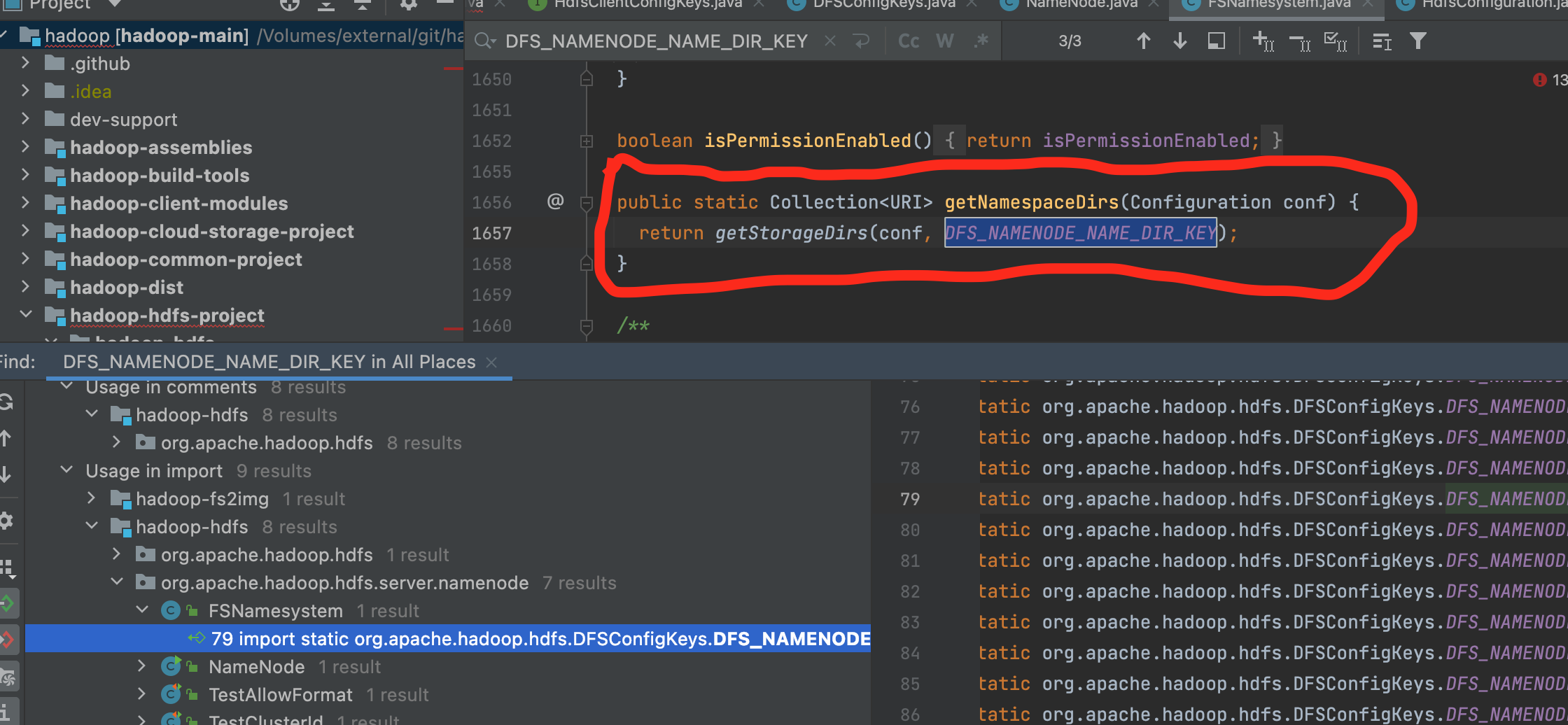
可以看到 在 FSNamesystem类中,提供了一个静态方法
1 | public static Collection<URI> getNamespaceDirs(Configuration conf) { |
返回元数据的目录。
4、查看使用getNamespaceDirs的代码
继续使用idea的 find usage功能,来查看 getNamespaceDirs 被哪些类使用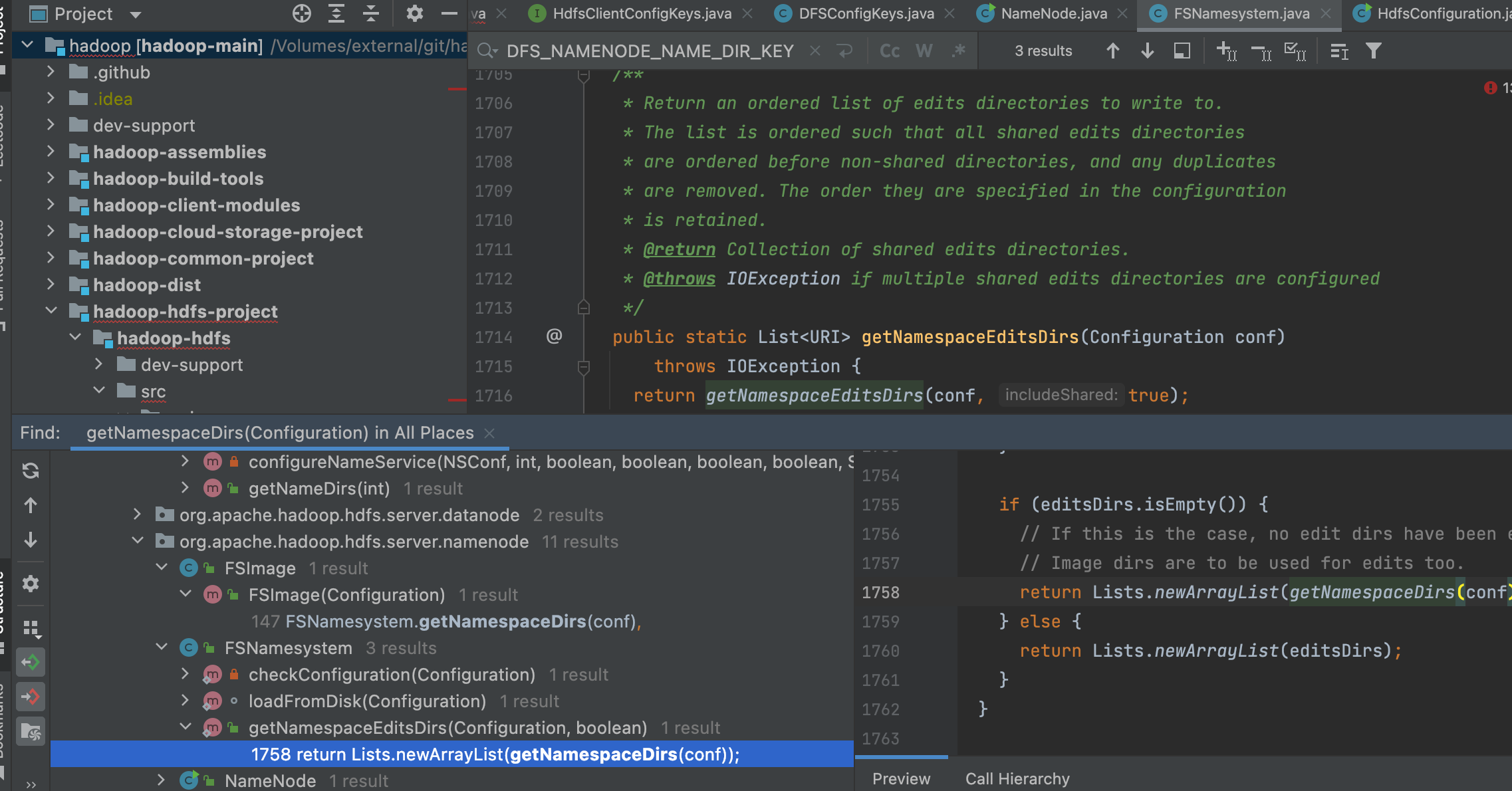
可以看到 在 FSNamesystem类中,有一个方法getNamespaceEditsDirs使用了,而这个方法名称看着就像是我们要找的,通过阅读方法注释,了解到这个方法是返回一个排序的日志目录list用于写入。
5、查看使用getNamespaceEditsDirs的代码
继续使用idea的 find usage功能,来查看 getNamespaceEditsDirs 被哪些类使用
可以看到 在 FSImage 类中,构造方法使用了该方法
继续点击this
1 | /** |
可以看到this.editLog = FSEditLog.newInstance(conf, storage, editsDirs);使用传入的editsDirs构建了FSEditLog对象。
FSEditLog,文件系统的edit log,这不正是我们想要删除的文件对应的对象吗?
FSImage,文件系统的镜像,包含了FSEditLog。
想要找删除的方法有极大的概率就包含在这两个类中。
6、查看FSEditLog类
1 | /** |
看类先看注解,FSEditLog的注解为,FSEditLog 维护命名空间修改的日志。
再看继承和接口,只有一个接口,LogsPurgeable
1 | /** |
该接口是对可能需要被清除的edit log日志的管理的抽象。
说人话就是用于清除edit log日志,这不就是本次要找的删除文件操作码。
查看LogsPurgeable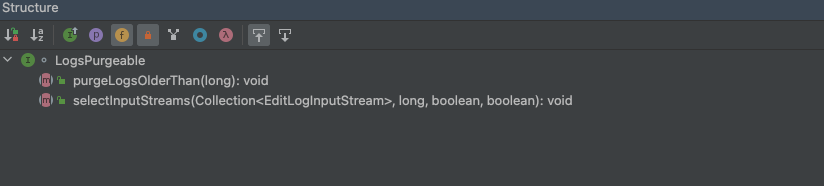
改接口非常简单,之定义了两个方法。
重点来看 purgeLogsOlderThan
1 | /** |
清除所有比传入事务txid低的edit logs 文件。
可以基本确认这就是删除edit log文件的入口了。
接着查看该方法的实现类有哪些。
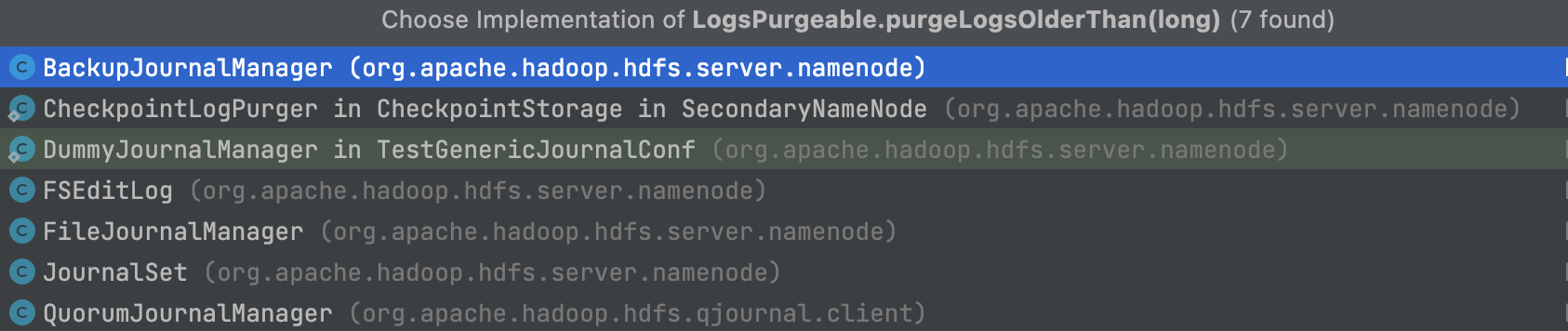
由于我们要删除的是文件,重点关注 FileJournalManager
7、查看FileJournalManager
1 | /** |
该方法比较简单易懂,继续点击查看purger.purgeLog
1 | static class DeletionStoragePurger implements StoragePurger { |
非常简单,通过获取EditLogFile的file对象,最后调用file.delete()实现文件删除,如果无法删除,那么告警。
至此,底层的文件删除我们已经找到了,但是上游最小事务txid是如何获取的还未知道。
回到FSEditLog.purgeLogsOlderThan 方法中,通过idea的find useage方法查看该类被哪些类使用
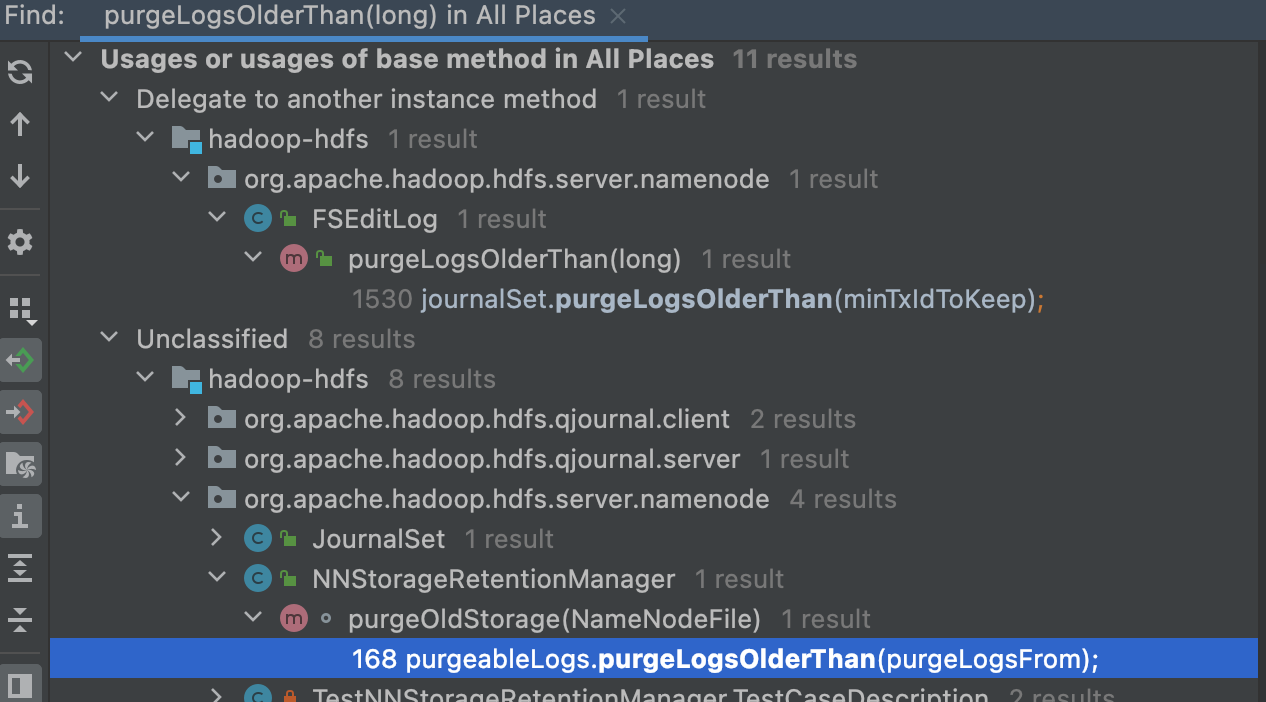
大部分方法都是purgeLogsOlderThan调用purgeLogsOlderThan,只有 NNStorageRetentionManager.purgeLogsOlderThan不是。
8、查看NNStorageRetentionManager
1 | /** |
惯例先看注解
NNStorageRetentionManager 负责检查 NN 的存储目录并对检查点和编辑日志执行保留策略。 它将文件的实际删除委托给 StoragePurger 实现,该实现可能会删除文件或将它们复制到文件管理器或 HDFS 以供以后分析。
日志执行保留策略,看来快到终点了。
查看purgeOldStorage方法
1 | void purgeOldStorage(NameNodeFile nnf) throws IOException { |
该方法比较长,本人都在关键部位注释。
方法基本就是根据一些逻辑计算出需要保留的最小事务txid,最后调用purgeableLogs.purgeLogsOlderThan清除小于该事务的log文件,如何清除的上文已经讲解。
那么计算逻辑是什么呢?有两点
- 保留 numExtraEditsToRetain 条事务
- 保留 maxExtraEditsSegmentsToRetain 个edit log日志文件
两个策略独立运行,只要有一个条件不满足,日志就会被删除。
至此,我们已经知道了edit log日志文件的删除逻辑。
9、查看numExtraEditsToRetain和maxExtraEditsSegmentsToRetain对应的配置参数
最后,查看源码,获得numExtraEditsToRetain和maxExtraEditsSegmentsToRetain对应的配置参数。
numExtraEditsToRetain对应的参数为 dfs.namenode.num.extra.edits.retained
1 | this.numExtraEditsToRetain = conf.getLong( |
maxExtraEditsSegmentsToRetain对应的参数为 dfs.namenode.max.extra.edits.segments.retained
1 | this.maxExtraEditsSegmentsToRetain = conf.getInt( |
在查看hadoop的官方hdfs-default.xml文档获得相关配置的解释。
| name | value | description | 翻译 |
|---|---|---|---|
| dfs.namenode.num.extra.edits.retained | 1000000 | The number of extra transactions which should be retained beyond what is minimally necessary for a NN restart. It does not translate directly to file’s age, or the number of files kept, but to the number of transactions (here “edits” means transactions). One edit file may contain several transactions (edits). During checkpoint, NameNode will identify the total number of edits to retain as extra by checking the latest checkpoint transaction value, subtracted by the value of this property. Then, it scans edits files to identify the older ones that don’t include the computed range of retained transactions that are to be kept around, and purges them subsequently. The retainment can be useful for audit purposes or for an HA setup where a remote Standby Node may have been offline for some time and need to have a longer backlog of retained edits in order to start again. Typically each edit is on the order of a few hundred bytes, so the default of 1 million edits should be on the order of hundreds of MBs or low GBs. NOTE: Fewer extra edits may be retained than value specified for this setting if doing so would mean that more segments would be retained than the number configured by dfs.namenode.max.extra.edits.segments.retained. | 应该保留的额外事务的数量超出了 NN 重新启动所需的最低限度。它不会直接转换为文件的年龄或保存的文件数量,而是转换为事务的数量(这里“编辑”是指事务)。一个编辑文件可能包含多个事务(编辑)。在检查点期间,NameNode 将通过检查最新的检查点事务值减去此属性的值来确定要保留的编辑总数。然后,它扫描编辑文件以识别不包括计算范围的保留交易的旧文件,并随后清除它们。保留对于审计目的或 HA 设置很有用,其中远程备用节点可能已离线一段时间并且需要保留更长的保留编辑积压才能重新开始。通常,每次编辑大约为几百字节,因此默认的 100 万次编辑应该是数百 MB 或低 GB 的数量级。注意:如果这样做意味着保留的段数多于 dfs.namenode.max.extra.edits.segments.retained 配置的数量,则保留的额外编辑可能少于为此设置指定的值。 |
| dfs.namenode.max.extra.edits.segments.retained | 10000 | The maximum number of extra edit log segments which should be retained beyond what is minimally necessary for a NN restart. When used in conjunction with dfs.namenode.num.extra.edits.retained, this configuration property serves to cap the number of extra edits files to a reasonable value. | 应该保留的额外编辑日志段的最大数量超出了 NN 重新启动所需的最低限度。 当与 dfs.namenode.num.extra.edits.retained 一起使用时,此配置属性用于将额外编辑文件的数量限制为一个合理的值 |
可以看到,文档和我们源码看到的一致,至此,已完全弄清楚hadoop的元数据是如何删除edit log日志的。
log是 10002个?
通过上节的源码及配置参数,我们再来解释下元数据目录下edit log为什么是10002个。
首先,namenode元数据目录下的文件数一共是10009个
扣除VERSION,edits_ingrogress等非历史edits log文件7个,还剩余10002个日志。
由于本人的hadoop集群事务较少,因此dfs.namenode.num.extra.edits.retained这个1000000保留事务条件未触发,该条件不会进行删除。
dfs.namenode.max.extra.edits.segments.retained 这个10000个保留日志文件数条件达到,因此会进行日志删除。
但是10002个好像比参数的10000个多2个?
注意看下镜像文件
fsimage_0000000000000257178
fsimage_0000000000000257180
可以看到镜像文件的保留策略为2个,第一个镜像的合并截止事务为0000000000000257178,也就是上文源码说的最小事务id为0000000000000257178,也就是说 0000000000000257178 这个文件不在五行中。edits_0000000000000254548-0000000000000257178
edits_0000000000000257179-0000000000000257180
属于必须得日志文件,不能删除,否则无法根据日志还原镜像。
修改保留策略
1、修改hdfs-site.xml,添加
1 | <property> |
2、动态刷新hdfs配置。
1 | hdfs dfsadmin hdfs://nn1:9000 -refreshSuperUserGroupsConfiguration |