数据倾斜简述
引言
本文为本人参考资料及自己日常经验总结的数据倾斜相关的知识,主要是利用输出查漏补缺,加深自己的印象。文章脑图如下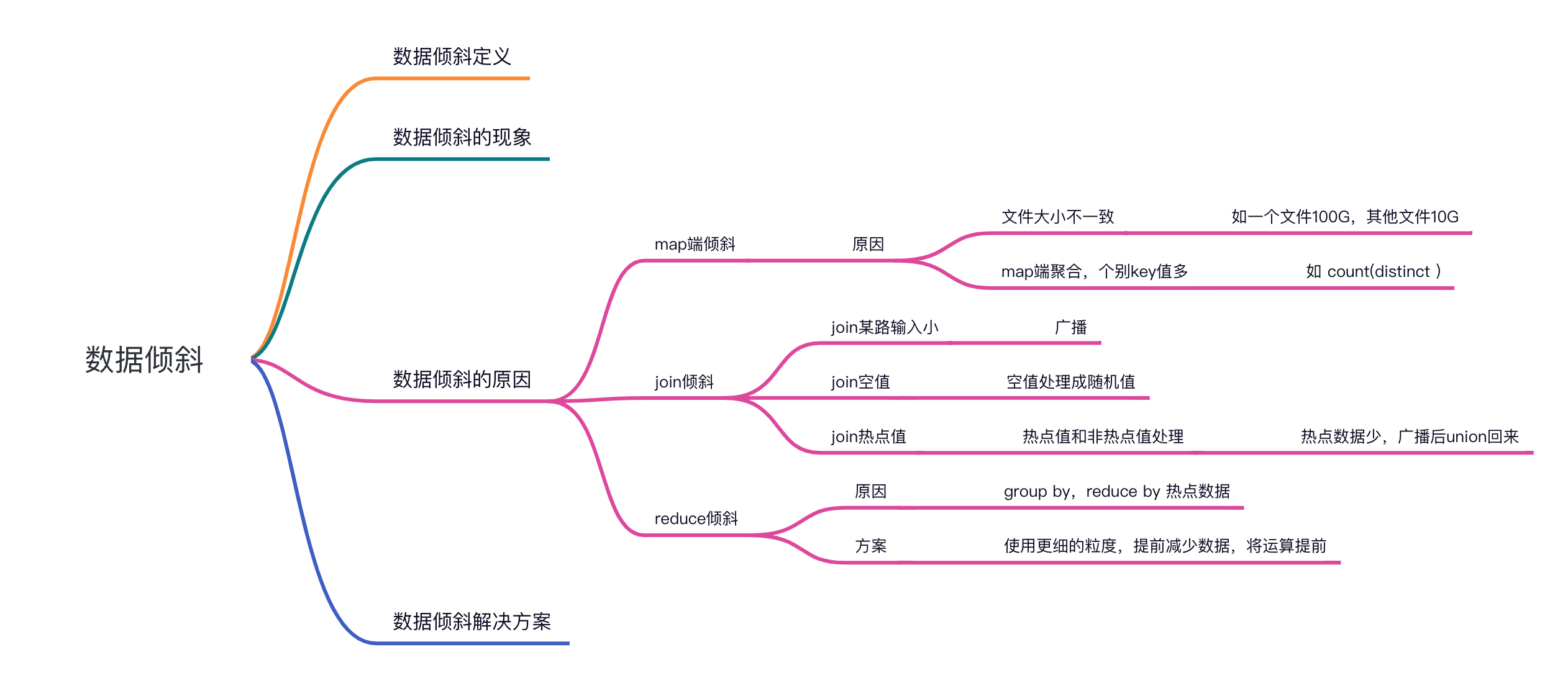
数据倾斜的定义
Data skew refers to a phenomenon in distributed systems where the distribution of data across nodes or partitions is uneven. This can result in some nodes having a much larger amount of data to process than others, leading to unequal distribution of workload, longer processing times and reduced performance.
数据偏斜是指分布式系统中数据在节点或分区间分布不均的现象。这可能导致一些节点处理的数据量比其他节点多得多,从而导致工作负载分配不均,处理时间增加以及性能下降。
– by chatGPT
这是以上chatGPT对于数据倾斜的解释,解释的还是非常到位的。
大数据体系下的分布式系统核心理念是分治。
举例来说,如果使用一台服务器处理3T数据,那么耗时是3小时。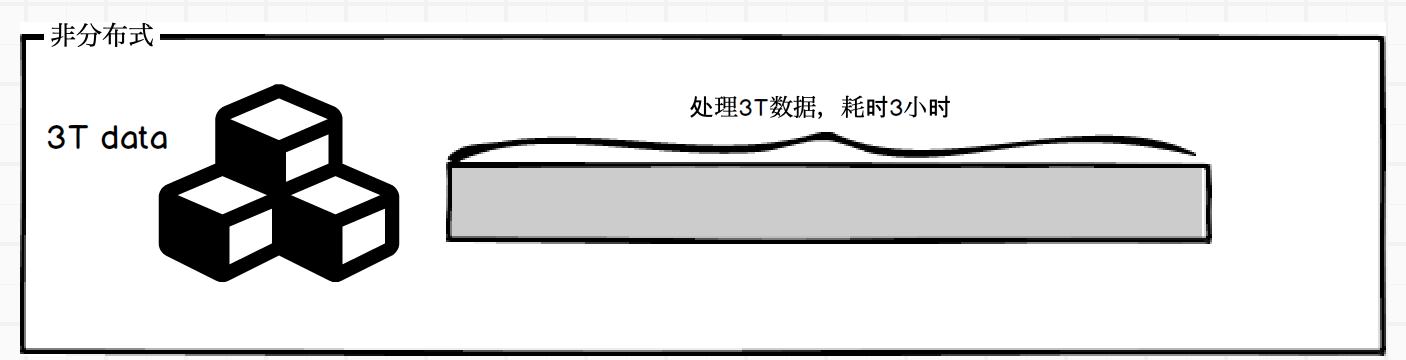
那么将3T数据,拆分成3份,没份1T,交由3台服务器去处理,那么理想情况下耗时为1小时,效率大大提高,这便是分布式。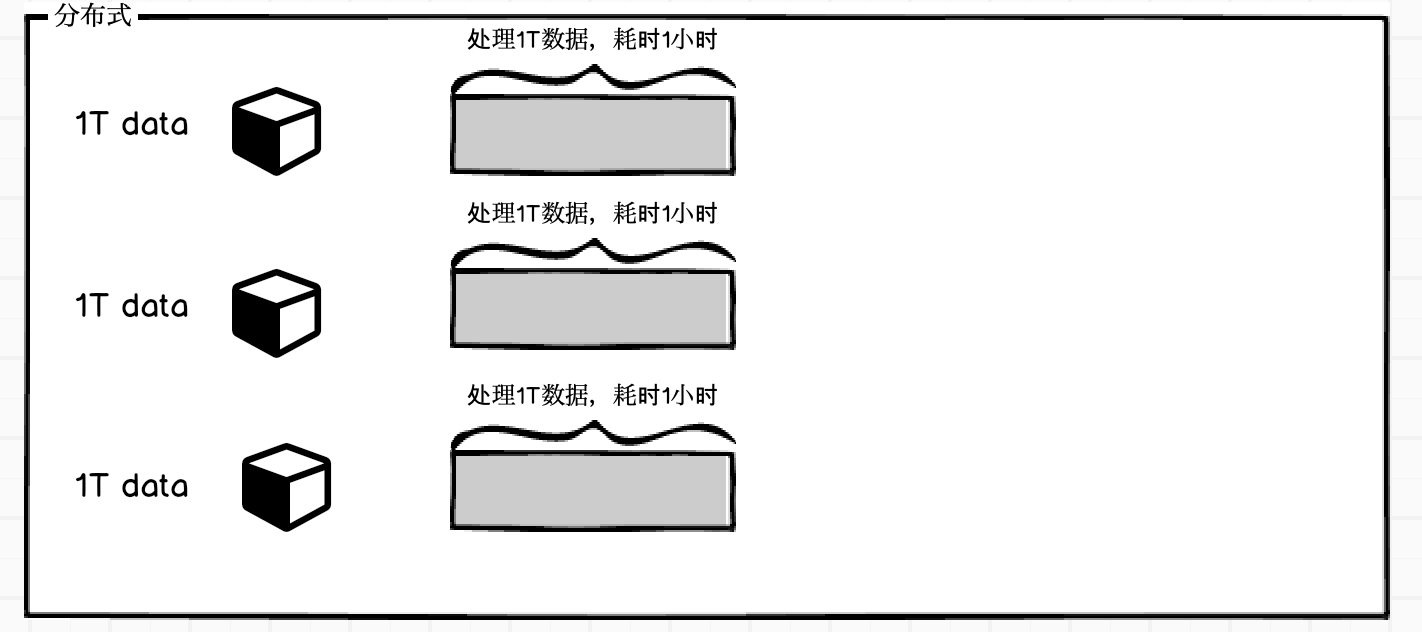
数据倾斜的原因
shuffle操作
了解数据倾斜的原因前,我们需要了解下shuffle操作,这在mapreduce计算框架及spark中都涉及的操作。
//TODO 完善 shuffle概念
了解了shuffle后,我们可以将数据倾斜的原因归为3类
- map端倾斜
- 双端倾斜(join倾斜)
- reduce段倾斜
map端倾斜
map端倾斜的原因是主要就是上游的文件大小不均匀,存在特别极大的文件。
比如有以下五个文件
| 文件名 | 文件大小 |
|---|---|
| file1 | 100M |
| file2 | 100M |
| file3 | 100M |
| file4 | 100M |
| file5 | 1G |
假如起的是5个map任务,那么file5对应的那个map任务理论上耗时是其他4个的10倍。
该类的解决方法比较简单。
如果文件是可分割的,那么设定单个文件读入的上限,以便将单个文件切割成多个任务。
或者直接混洗数据,将数据重新分布,方便后续使用。
join倾斜
reduce倾斜
数据倾斜的现象
数据倾斜的解决方案
参考
./change-scala-version.sh 2.12
mvn -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package -Dmaven.test.skip=true
mvn -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package
mvn -e -X -Pscala-2.12 -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package
mvn -e -X -Pscala-2.12 -Pyarn -Phadoop-3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package
mvn -pl sql/catalyst -e -X -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package
mvn -pl common/tags -e -X -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests install
[INFO] Spark Project Parent POM ……………………… SUCCESS [ 16.689 s]
[INFO] Spark Project Tags …………………………… SUCCESS [ 1.551 s]
[INFO] Spark Project Sketch …………………………. SUCCESS [ 1.460 s]
[INFO] Spark Project Local DB ……………………….. SUCCESS [ 2.367 s]
[INFO] Spark Project Networking ……………………… SUCCESS [ 2.333 s]
[INFO] Spark Project Shuffle Streaming Service ………… FAILURE [ 3.062 s]
[INFO] Spark Project Unsafe …………………………. SKIPPED
[INFO] Spark Project Launcher ……………………….. SKIPPED
[INFO] Spark Project Core …………………………… SKIPPED
[INFO] Spark Project ML Local Library ………………… SKIPPED
[INFO] Spark Project GraphX …………………………. SKIPPED
[INFO] Spark Project Streaming ………………………. SKIPPED
[INFO] Spark Project Catalyst ……………………….. SKIPPED
[INFO] Spark Project SQL ……………………………. SKIPPED
[INFO] Spark Project ML Library ……………………… SKIPPED
[INFO] Spark Project Tools ………………………….. SKIPPED
[INFO] Spark Project Hive …………………………… SKIPPED
[INFO] Spark Project REPL …………………………… SKIPPED
[INFO] Spark Project Assembly ……………………….. SKIPPED
[INFO] Kafka 0.10+ Token Provider for Streaming ……….. SKIPPED
[INFO] Spark Integration for Kafka 0.10 ………………. SKIPPED
[INFO] Kafka 0.10+ Source for Structured Streaming …….. SKIPPED
[INFO] Spark Project Examples ……………………….. SKIPPED
[INFO] Ivan Spark Project Examples …………………… SKIPPED
[INFO] Spark Integration for Kafka 0.10 Assembly ………. SKIPPED
[INFO] Spark Avro ………………………………….. SKIPPED
mvn -rf :spark-catalyst_2.12 -e -X -Pyarn -Phadoop-3.3 -Dhadoop.version=3.3.1 -Phive -Phive-thriftserver -DskipTests clean package
[ERROR] mvn
mvn dependency:get -Dartifact=org.eclipse.m2e:lifecycle-mapping:1.0.0:jar:sources
mvn dependency:get -Dartifact=org.apache.maven.plugins:maven-downloader-plugin:1.0:jar:sources
1) org.apache.maven.plugins:maven-downloader-plugin:jar:1.0
[ERROR] 2) org.eclipse.m2e:lifecycle-mapping:jar:1.0.0
mvn -e -X idea:module