基于 tesseract 和 JtessBoxEditor 实现 东方财富登录验证码破解
引言
最近打算给自己的量化交易实现全自动,交易的api本人是通过easytrader这个开源项目实现的,这个项目通过自动化控制客户端进而实现交易的程序控制。
但比较可以的是,easytrader在21年3月14日后这个开源软件就不再更新了,而且本人的券商账户使用的是东方财富,该项目尚未支持。
作为一个程序员,项目不支持,当然是自己实现了。由于东方财富支持web端交易,因此可以通过selenium 实现web端的自动化,其他关于下单、撤单、持仓、当日成交等自动化本人均已顺利实现,然而东方财富的登录有验证码,自动登录暂时遇到困难。
东方财富的验证码样例如下:
由于数字倾斜和横线干扰,直接使用tesseract进行识别准确率低。
本文就是记录解决这一问题的方案及过程,烂笔头胜过好记性吗。
解决方案
问题已经抛出,现在轮到说解决方案了。
验证码破解,可以说是爬虫技术中比较平常遇到的问题了,上网搜了下,个人理解的解决方案有两种
- 找到第三方现成的识别技术进行识别
- 自己训练识别
方案的比较
第三方现成技术
关于第三方现成的识别,其识别技术叫做OCR (Optical Character Recognition) 是一种技术,用于从图像或扫描的文档中识别文本。它通过分析图像中的字符形状和比例,将其转换为可编辑的电子文本。
这里本人不是此方向的,感兴趣的可以自己搜索,常见的比如百度的通用文字识别。
第三方现成技术其有点自然是省心省力,直接调用api即可。
缺点吗,费钱,同时只支持通用场景,如果是非常特殊的可能无法支持。
自己训练识别
这里,本人直接使用的是tesseract识别验证码,而tesseract自带模型训练,同时还有jTessBoxEditor辅助训练工作,因此就直接使用了该模型训练。
至于其他的模型训练,大家可以自行搜索。
自己训练的有点自然是定制化,可以识别各种场景,准确率高。
缺点则是耗时,毕竟要自行训练,自己准备数据,同时对于技术存在要求,新手小白可能无法实现。
比较结论
作为一穷二白的程序员,咱除了没钱,时间有的是,生命在于折腾,因此本人选择自己训练。
具体操作
好了,来到了具体操作环节,模型训练的基本流程为:
环境准备–>测试数据准备–>模型训练–>模型使用。
简单来说就是使用tesseract自带的模型训练,同时使用jTessBoxEditor可视化调整错误数据训练验证码识别,最后进行识别,下面就开始。
工具基础介绍
tesseract
Tesseract 是一个开源的OCR(光学字符识别)引擎,用于从图像和PDF文件中识别文本。它是Google开发的,是目前功能最强大的OCR引擎之一,支持多种语言。它可以运行在多种操作系统上,并且可以被集成到各种应用程序中,以实现文本识别功能。
详细信息大家可以上Tesseract的github的readme进行查看
jTessBoxEditor
jTessBoxEditor 是一个开源的OCR工具,用于创建和编辑Tesseract字符识别引擎的语言训练数据。它允许用户创建语言模型,以便Tesseract引擎能够识别特定语言的文本。它还提供了一种方便的图形界面,可以编辑语言模型的数据,如字符定义和字符图像。
详细信息可以上jTessBoxEditor的github进行查看
环境准备
- python 3.7.9
- tesseract 5.3.0
jTessBoxEdit自带了tesseract,直接使用自带的,否则可能存在不兼容异常的情况。 - jTessBoxEditor 2.4.0
下载地址: https://github.com/nguyenq/jTessBoxEditor/releases
环境变量啥的大家自己配置
测试数据准备
验证码下载
本次的目标是东方财富的登录验证码,测试数据咱也不需要多,100张即可,因此也就不自动化了,直接登录网站 https://jywg.18.cn/ 手动下载100张验证码。
本人存入的目录为org_imgs,如下图。
验证码的降噪处理
验证码的颜色,干扰线等特征会增加训练复杂度,因此需要将这些特征去除
本人只是简单的将颜色去除,具体代码如下:
1 | from PIL import Image |
处理好的图片效果如下所示。
合并数据准备
打开jTessBoxEditor,双击train.bat即可,界面如下:
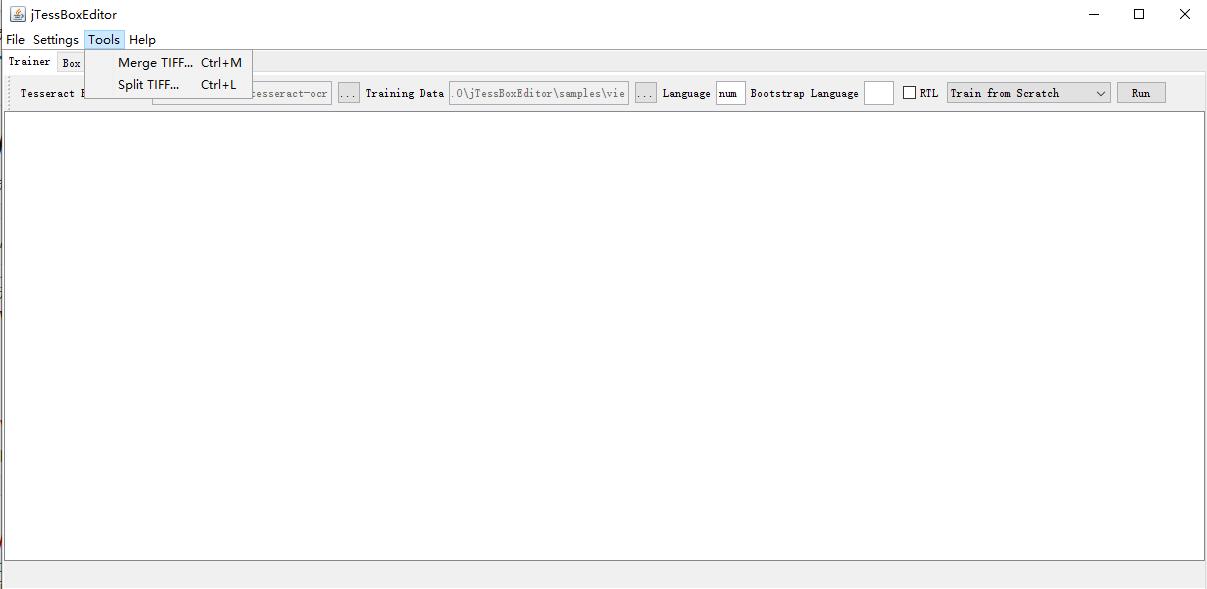
选择【tools】->【merge tiff】,打开合并成tiff界面,文件类型根据自己图片类型选择,本人为tif,文件按住shift合并选择或crl健多个选择,选择需要合并的原始图片,本人为所有。
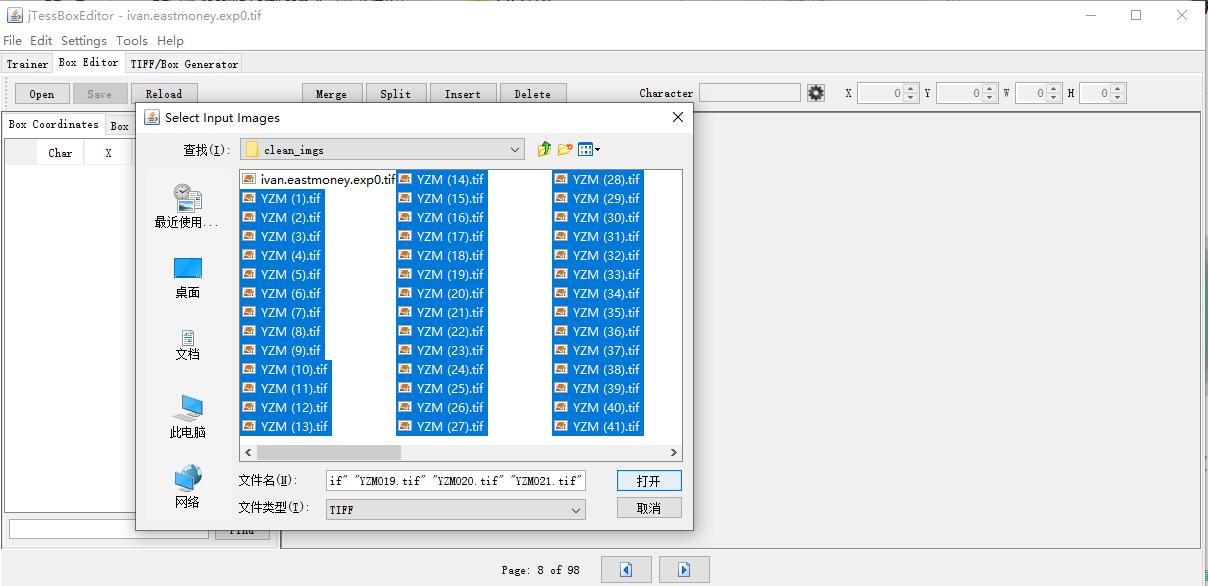
点击打开,进入保存选项,文件名有具体格式,具体为[lang].[fontname].exp[num].tif,其中
- lang表示语言名称;指的是使用tesseract指定的语言,由于我们的语言是自己训练的,因此命名需要我们取。
- fontname表示字体名称;
- num表示序号
本人的保存文件命名为
ivan.eastmoney.exp0.tif
点击保存即可,此时即可生成 ivan.eastmoeny.exp0.tif。
- 生成tif图片的box文件。
输入如下命令,生成tif对应的box文件。该命令会生成box文件,本人生成的文件为 ivan.eastmoeny.exp0.box1
tesseract ivan.eastmoeny.exp0.tif ivan.eastmoeny.exp0 batch.nochop makebox
box文件和tif是一对的,可以简单理解成标注了tif图片位置和解析结果的文件,命名也需要一致,且在同一个文件夹下。
命令的结果如下
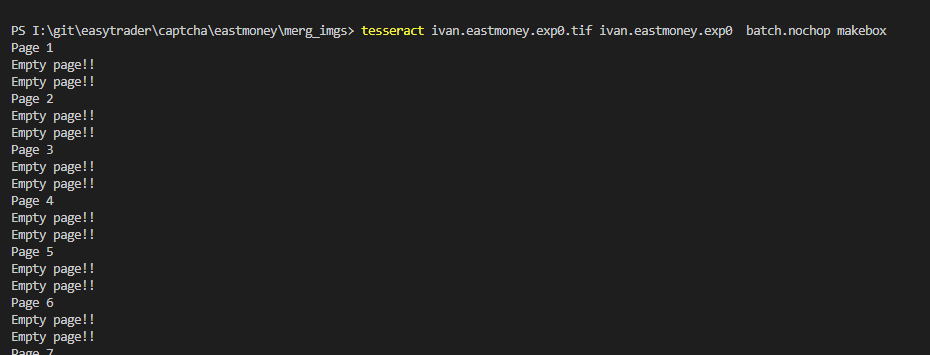
enptyPage 表示没有解析结果,这是因为tesseract默认使用的psm为3,表示的是全自动页面分割,但没有 OSD。
这里没有结果方便后面我们重构box位置,如果想要有结果,可以加上 –psm 6 参数,解析文本。
1 | Page segmentation modes: |
测试数据调整
打开之前的jTessBoxEditor软件,选择【box editor】->【open】,然后选择直接合并好的tif文件。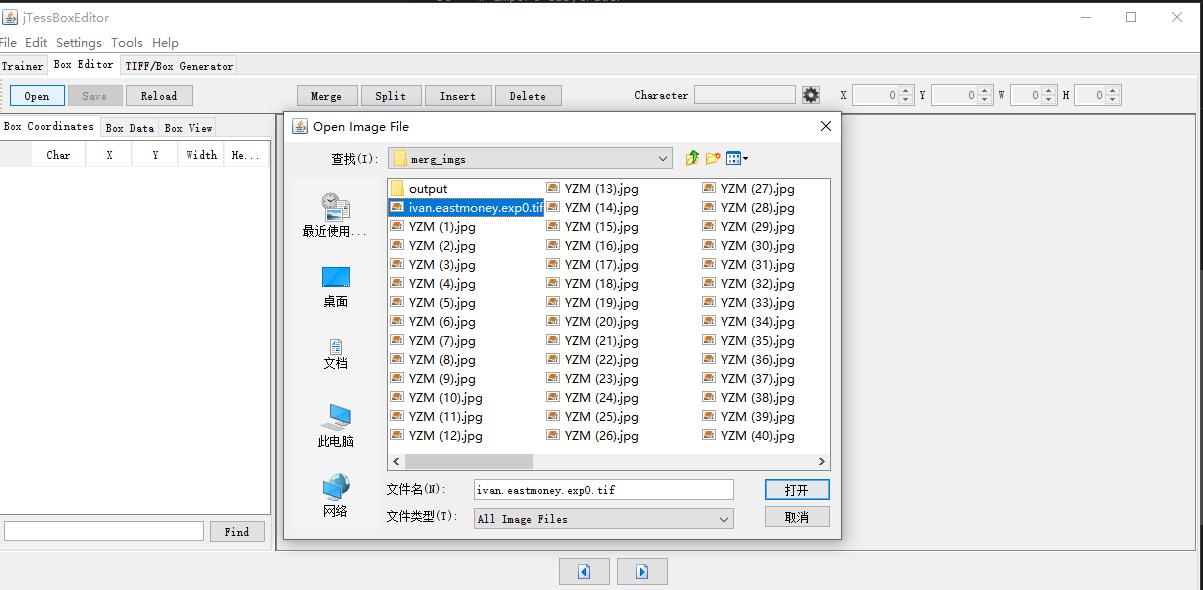
打开后的一个图片如下所示,此时完全没有识别,同时可以看到一共有98个图片。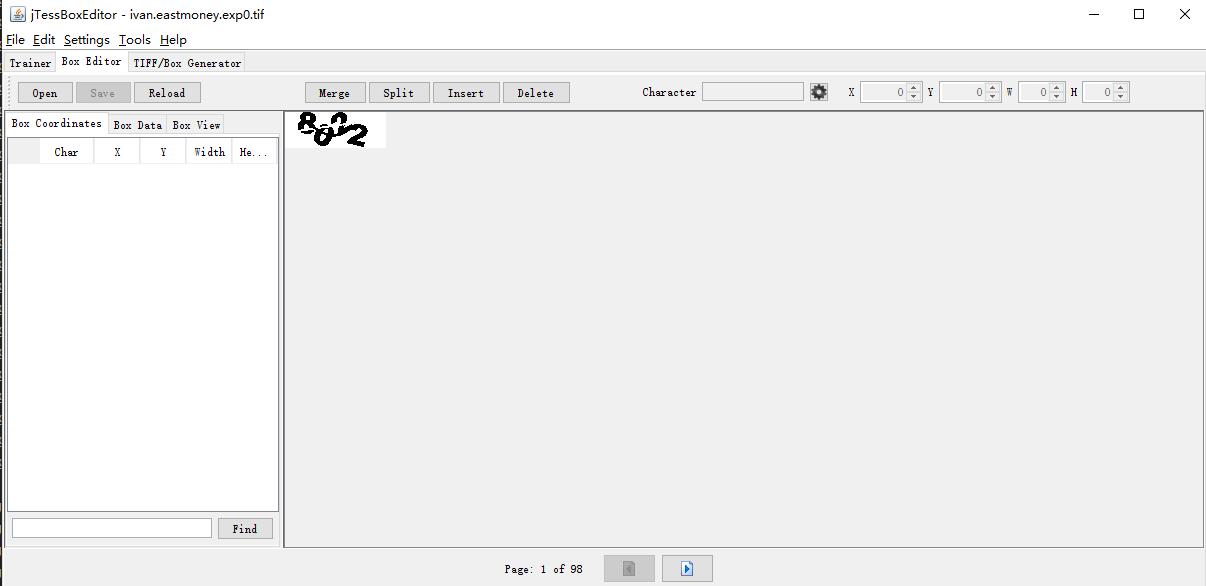
我们点击insert插入四个box。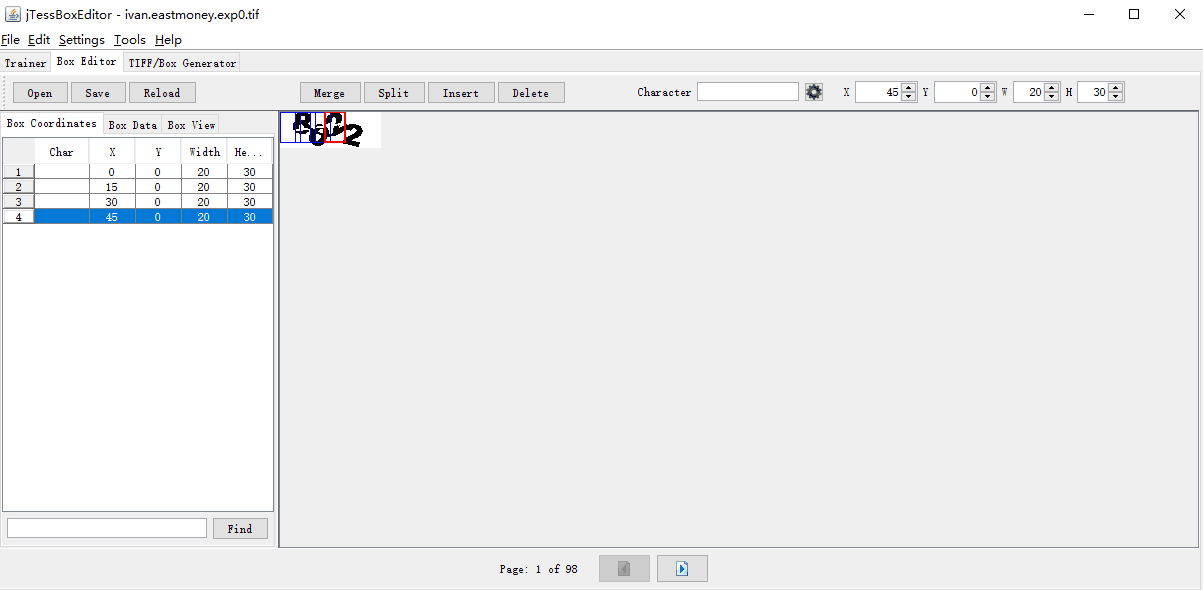
然后通过选中左边的1,2,3,4编号box,再通过右边的x,y调整box将box覆盖到我们需要识别的数字上,最后在char中填入正确的结果,选择完成后点击保存按钮。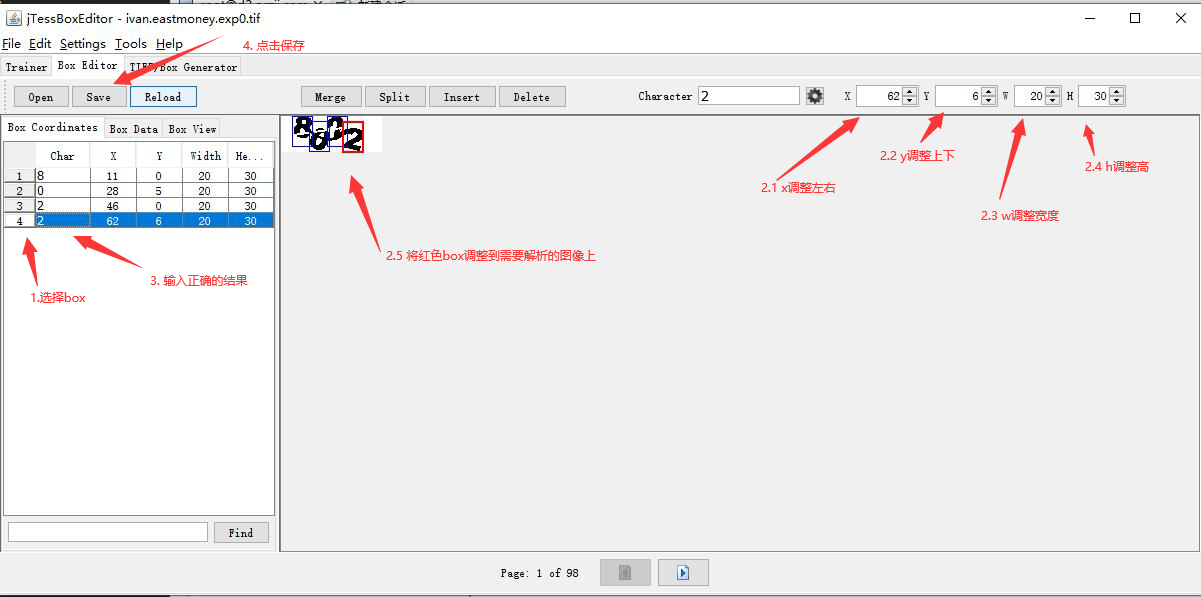
之后重新打开tif文件,此时点击下一页,会发现box已经选好,只需要填入正确结果即可,此时会有一些工作量,将98个图片正确结果都填入,最后保存。
这样,我们的测试数据就准备好了。
模型训练
生成lstmf文件
这一步,我们通过TIF图像文件和box盒子文件生成进行LSTM训练所需的lstmf文件,使用到的命令如下所示:1
tesseract ivan.eastmoney.exp0.tif ivan.eastmoney -l eng --psm 6 lstm.train
运行结果如下
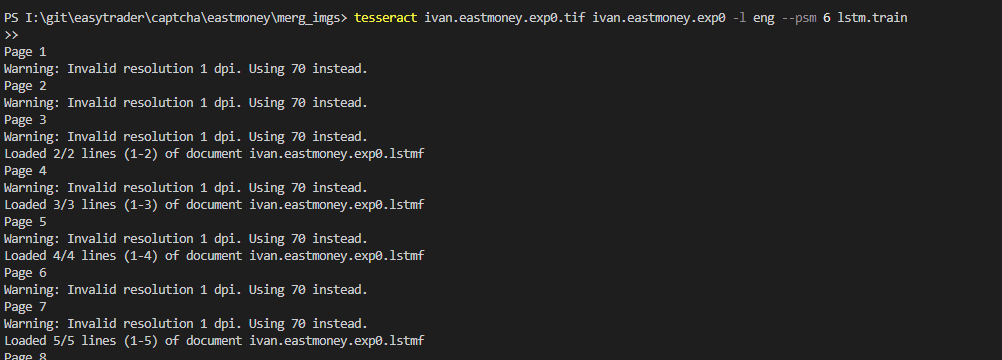
运行之后,我们的文件夹下会生成一个名为ivan.eastmoney.exp0.lstmf的文件。提取语言的LSTM文件
我们接着从tesseract_best(链接:https://github.com/tesseract-ocr/tessdata_best)下载相应语言的traineddata文件。
在前面几步,我们选用的语言是英文,所以在这里选择eng.traineddata文件。
下载好之后,我们需要从中提取中它的LSTM文件,使用的命令如下所示:1
combine_tessdata -e eng.traineddata eng.lstm
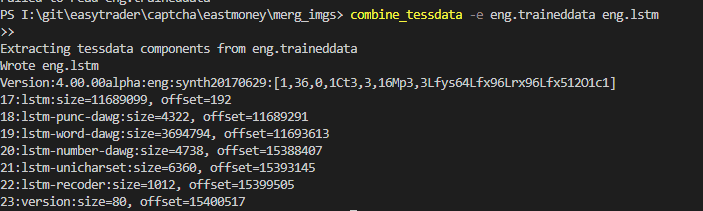
运行上述命令,我们的文件夹下会生成一个名为eng.lstm的文件。
新增 eng.training_files.txt文件。
新建eng.training_files.txt的文本文件,在里面填入第1步生成的lstmf文件的绝对路径。训练
在完成了上述步骤之后,我们基本上可以开始LSTM的训练了。使用下面的命令就可以开始训练了:1
2
3
4
5
6
7lstmtraining \
--model_output="output\output" \
--continue_from="eng.lstm" \
--train_listfile="eng.training_files.txt" \
--traineddata="eng.traineddata" \
--debug_interval -1 \
--max_iterations 4000各个参数具体的含义,可以参考Tesseract官方对于如何进行训练的说明(链接:https://tesseract-ocr.github.io/tessdoc/)
运行训练不到10分钟就完成了(具体的训练时间要视训练集的大小和训练次数决定)。待Tesseract训练完成之后,在output文件夹下会有很多checkpoint记录文件。
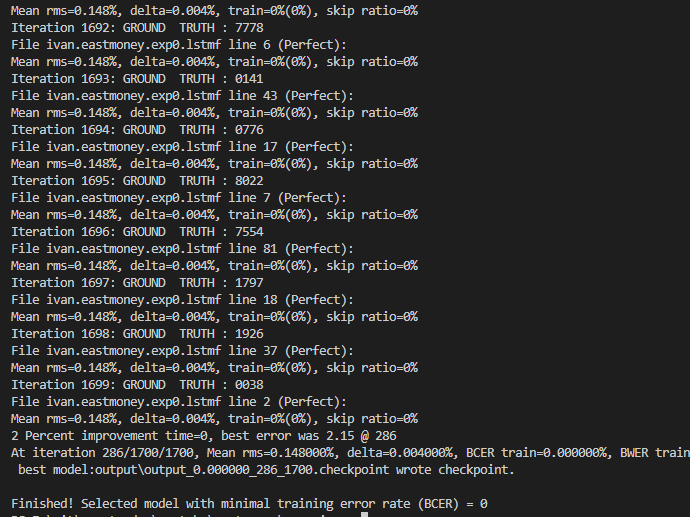
生成 traindata
们接着使用命令把这些文件和之前的eng.traineddata合成为新的traineddata文件,使用命令如下:1
2
3
4
5lstmtraining \
--stop_training \
--continue_from="output\output_checkpoint" \
--traineddata="eng.traineddata" \
--model_output="output\ivan.traineddata"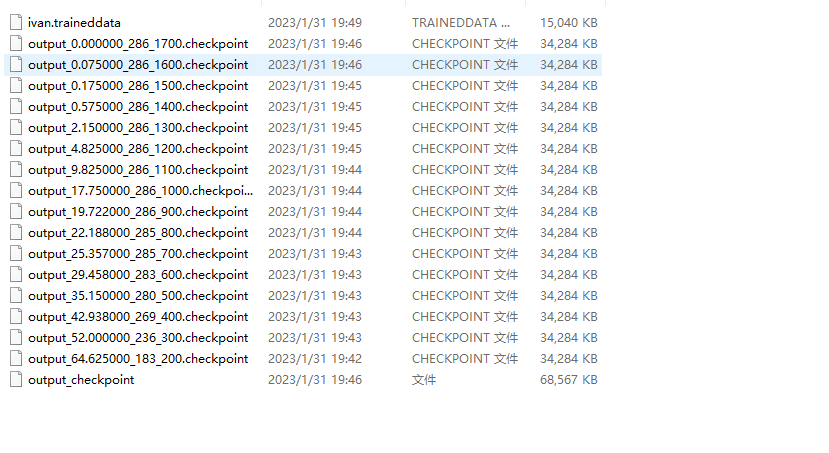
这一步过后,就会生成我们梦寐以求的triandata.
模型使用。
将生成的traindata文件,本人的为ivan.traineddata放到tesseract安装目录下的tessdata目录下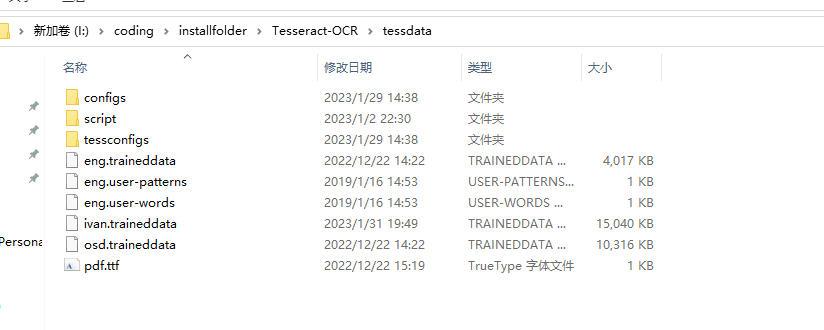
重新下载一个验证码进行测试,本次的验证码如下
之后使用命令进行验证
1 | tessseract --psm 6 yzm_test.jpg stdout -l ivan |
其中
- –psm 6 表示 tesseract以文本块进行解析
- stdout 表示在控制台输出
- -l ivan 表示解析的语言为ivan,即之前放入tessdata虾的ivan.traineddata文件
最终结果如下
可以看到,结果正确
遇到问题
Class->NumConfigs == this->fontset_table_.at(Class->font_set_id).size():Error:Assert failed:in file
这个问题查了半天也没搞定,最后将tessract换成jTessBoxEditor自带的tesseract就可以了,估计是啥兼容的问题。
使用 box.train 无效
网上很多教程是使用box.train的,如这篇用jTessBoxEditor训练tesseract模型,本人测试下来无效,估计是训练方式的问题,反正使用lstm训练有效,就不纠结了。
总结
前前后后花了整整3天搞定了验证码识别,从一开始什么都不知道,到后面不断查看文章,操作,查看文档,到最后对tesseract,jTessBoxEdotr是什么及如何操作有所了解,感谢互联网,感谢开源软件,让我这么一个小白都可以搞定验证码的识别。
当人,本人只是从应用层面有所了解,对tesseract整体的设计、源码、lstm模型了解是不深入的,此处就不卷了,能用就行了。
总的来说,使用tesseract训练数据定制化识别一些简单的文字及数字是一个可能及方便的方案。