maxcomputer 和 hive sql、spark sql 语法异常点 踩坑汇总
背景
处于降本增效的良好目标,最近公司在将数仓平台从自建的cdh底层往阿里云上的dataworks迁。
在迁移sql脚本时,踩了很多坑,发现阿里云的maxcomputer的sql语法和hive及spark的有很多区别,本文用于汇总所有踩坑记录
硬件&版本
- maxcomputer
2.0引擎,hive兼容模式 - spark sql
spark 2.3 - hive sql
hive 1.2
阿里云中关于maxcomputer和hive的语法差异文档
参考 与其他SQL语法的差异
支持标准差异
hive
在hive的官方文档Home中,对于sql的支持标准如下。
Hive provides standard SQL functionality, including many of the later SQL:2003, SQL:2011, and SQL:2016 features for analytics.
Hive 提供标准 SQL 功能,包括许多后来的 SQL:2003、SQL:2011 和 SQL:2016 分析功能。
该支持的标准sql功能都支持了,还支持了很多2003、2011、2016中的分析功能
maxcomputer
在阿里云官方文档SQL概述中,有这样一段话
MaxCompute SQL采用的是类似于SQL的语法。它的语法是标准语法ANSI SQL92的一个子集,并有自己的扩展。
虽然说的比较委婉,意思就是标准语法大部分我都支持了,但是有一小部分我魔改了,另外实现了很多独创的牛逼功能。
总结
- spark sql支持的标准文档暂未找到
- 从规范性上来说,hive更胜一筹
1、having 差异
差异点
spark sql 支持窗口函数后带having
hive和maxcomputer 的having语法不支持,只支持 在 group 和 distinct 后使用
举例
1 | with tmp as ( |
以上sql在spark sql中可以运行
在hive中会得到以下错误: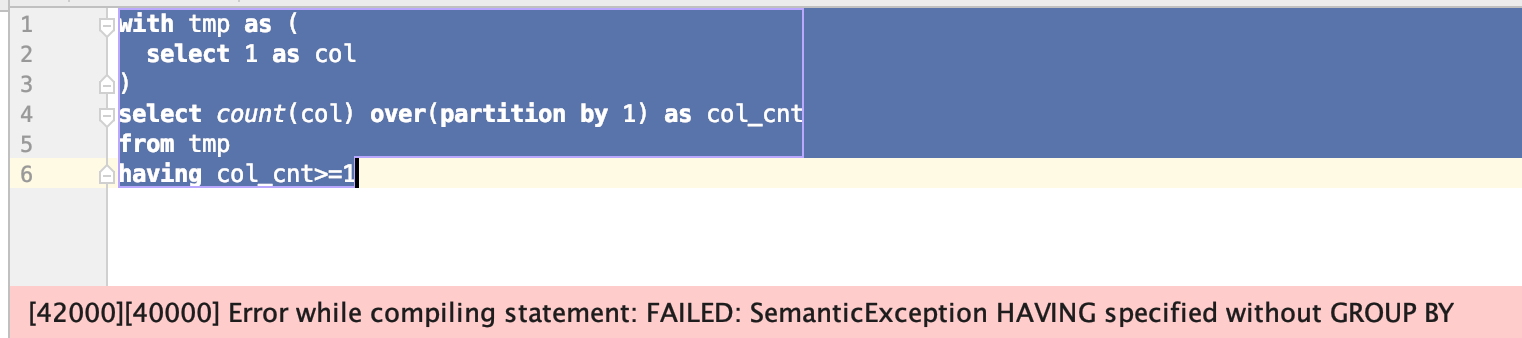
在maxcomputer中会提示错误,错误如下
1 | FAILED: ODPS-0130071:[4,8] Semantic analysis exception - window function cannot be used in HAVING clause |
解决方案
在语句中使用子查询,将having替换为where
1 | with tmp as ( |
2、maxcomputer cross join 超过一定条数后,依然会提示笛卡尔积风险
差异点
spark sql,hive可以使用 cross join语法来表示笛卡尔积关联
maxcomputer 的cross join,在条数超过一定数据量后,会提示笛卡尔积风险
举例
1 | with a as ( |
以上sql在hive和spark中都可以正常运行
但是在maxcomputer中会提示错误,错误如下
1 | FAILED: ODPS-0130252:[10,1] Cartesian product is not allowed - cartesian product is not allowed without mapjoin |
意思就是笛卡尔积在没有指定mapjoin的场景下不被允许。
在阿里云官方文档JOIN也有如下一段话告知不支持cross join
这里就不知道阿里云是出于性能还是其他考虑了,违反了sql标准不支持cross join,道理上来说cross join就是显示申明笛卡尔积关联,完全可以支持。
替换方案
参考官方文档,有两种方案
1、对于小表,可以使用sql MAPJOIN HINT语法申明mapjoin,实现cross join
1 | with a as ( |
2、如果数据量较大,则只能显示的在查询子表中申明常量列,再使用cross join 和on实现
1 | with a as ( |
3、不等值join 差异
差异点
- spark 支持不等值join语法
- hive 2.2.0版本之前不支持不等值语法
- 2.2.0及以后支持不等值join语法

- maxcomputer不支持不等值语法
举例
测试sql
1 | with table_a as ( |
sql说明
该sql准备了两张表table_a和table_b用于连接测试
使用left join on语法,但是关联关系使用的是 < 不等值关联符号
maxcomputer会报异常:
1 | FAILED: ODPS-0130071:[15,4] Semantic analysis exception - expect equality expression (i.e., only use '=' and 'AND') for join condition without mapjoin hint |
提示的是期望join的是等值表达式
hive1.2.1运行结果
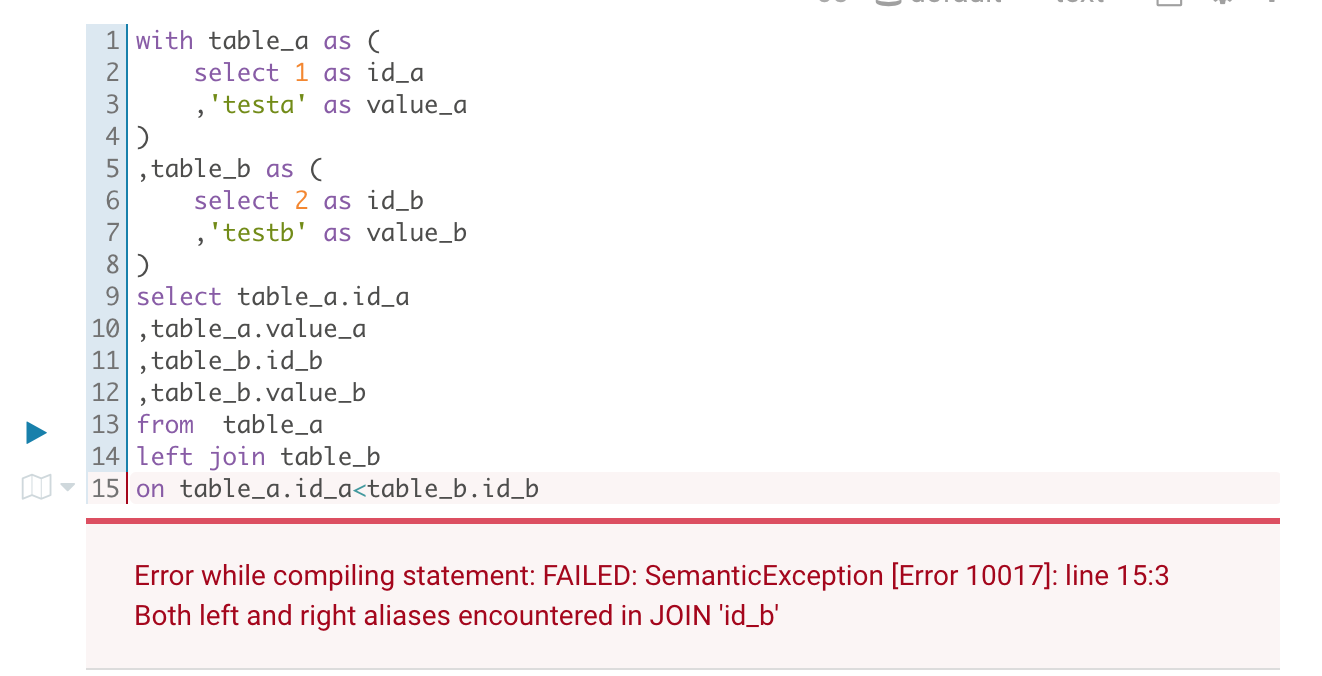
1 | Error while compiling statement: FAILED: SemanticException [Error 10017]: line 15:3 Both left and right aliases encountered in JOIN 'id_b' |
提示的是在join中遇到左右别名
不得不说,hive的错误信息有点云里雾里,其实就是不等值join造成的。
hive2.2.3运行结果
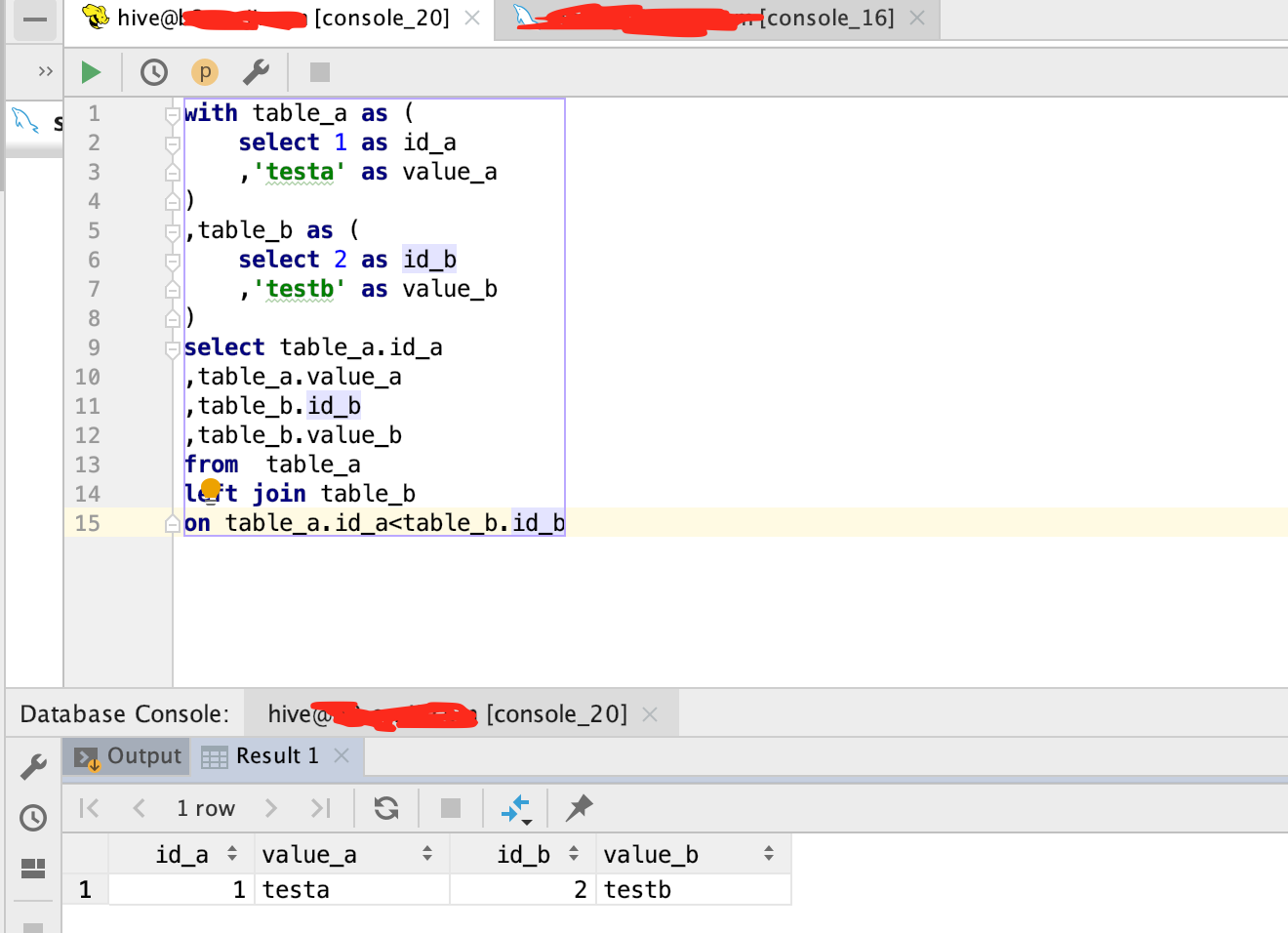
hive 2.2.0+版本顺利得到正确结果
spark运行结果
spark2.3也顺利得到结果
替换方案
针对不等值join的替换方案有两种
1、针对小表,使用mapjoin,避免join操作
针对小表,使用mapjoin,避免join操作
maxcomputer中的mapjoin hint语法为: /*+ mapjoin(<table_name>) */ ,详情请查看mapjoin hint
1 | with table_a as ( |
可以看到,使用mapjoin hint语法后,sql在maxcomputer中运行正确,顺利拿到了预期结果
由于mapjoin避免shuffle,性能较好,再可以的情况下,优先使用方案1
2、将on的不等值关联语句放入where语句中
inner join的实现方式较为简单
1 | with table_a as ( |
可以看到,将<判断语句放入where后,sql在maxcomputer运行正确,顺利拿到了预期结果
left join的实现方式非常复杂,不到万不得已不建议使用此方案,建议优先使用 map join hint
1 | with table_a as ( |
4、array_contains 差异
差异点
spark的array_contains支持类型的隐式转换
hive和maxcomputer array_contains不支持,只支持同类型使用
举例
测试sql
1 | select array_contains(split("1,2,3,4",","),1) |
sql说明
该sql首先使用split一个字符串获取一个array对象用于测试,之后使用array_contains函数进行判断
split后的array对象为一个string数组,而判断被包含的数字【1】为一个int 对象
maxcomputer运行结果
maxcomputer会报异常:
1 | FAILED: ODPS-0130071:[1,44] Semantic analysis exception - invalid type INT of argument 2 for function array_contains, expect STRING, implicit conversion is not allowed |
提示的是array_contains第二个参数期望的是string,但是传入的是int,隐式类型转换不支持
hive运行结果
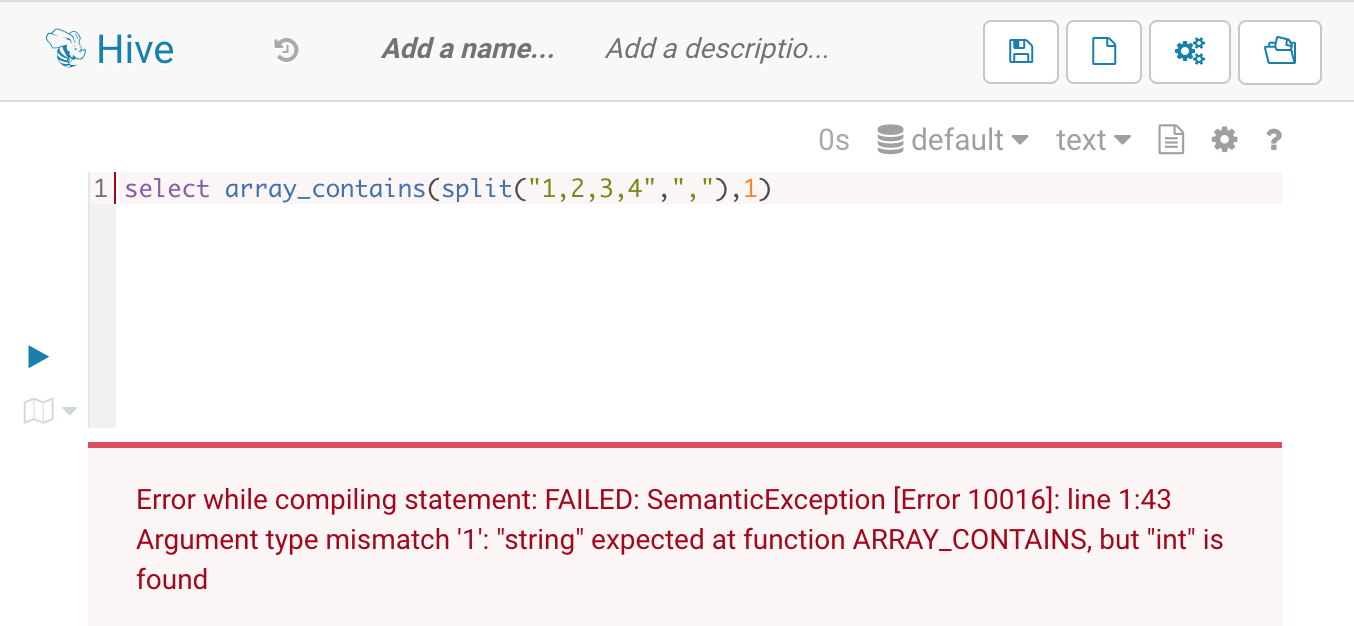
hive会报错:
1 | Error while compiling statement: FAILED: SemanticException [Error 10016]: line 1:43 Argument type mismatch '1': "string" expected at function ARRAY_CONTAINS, but "int" is found |
提示的是array_contains函数期望的是string,但是传入的是int,类型不匹配
spark运行结果
spark能顺利产出结果,结果为true,那么为什么spark可以成功呢?
大概率是spark智能的将1从int转换为了string类型,使得类型得以匹配,通过explain查看物理执行计划来验证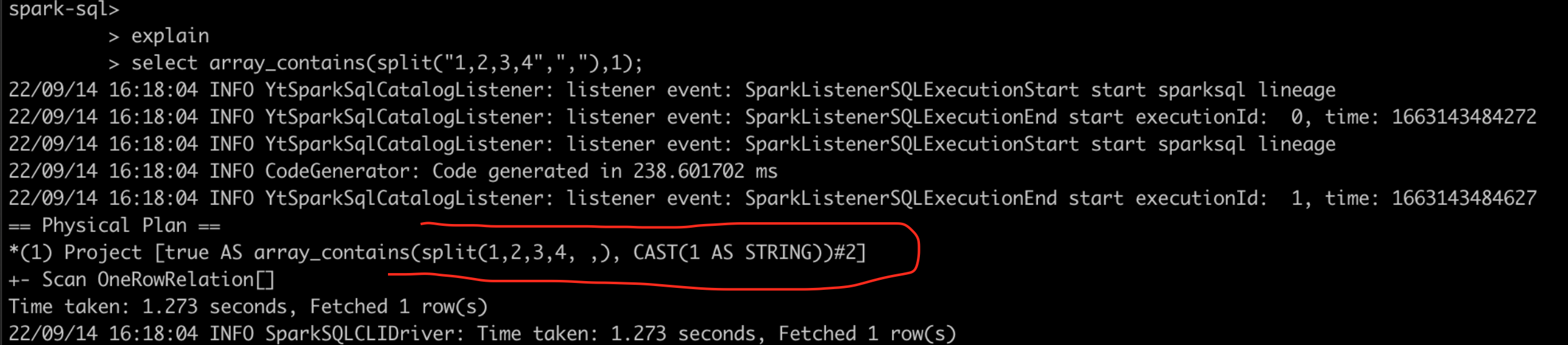
在上图标红的地方可以看到,spark在物理执行计划层面,将int的1隐式的转换为了string类型,验证了我们一开始的猜想。
替换方案
既然知道了在hive和maxcomputer中是类型不匹配导致的array_contains函数报错,那么只需要显示的将类型进行转换即可
1 | select array_contains(split("1,2,3,4",","),cast(1 as string)) |
5、 concat_ws 差异
差异点
spark的concat_ws会支持类型的隐式转换
hive和maxcomputer concat_ws不支持,只支持同类型使用
举例
测试sql
1 | select concat_ws(",",array(1,2,3)) |
sql说明
该sql首先使用array函数构建一个array<int>对象用于测试,之后使用concat_ws函数进行array的拼接
spark 运行结果正确
spark为何可以运行正确?是优化器做得好,有隐式转换?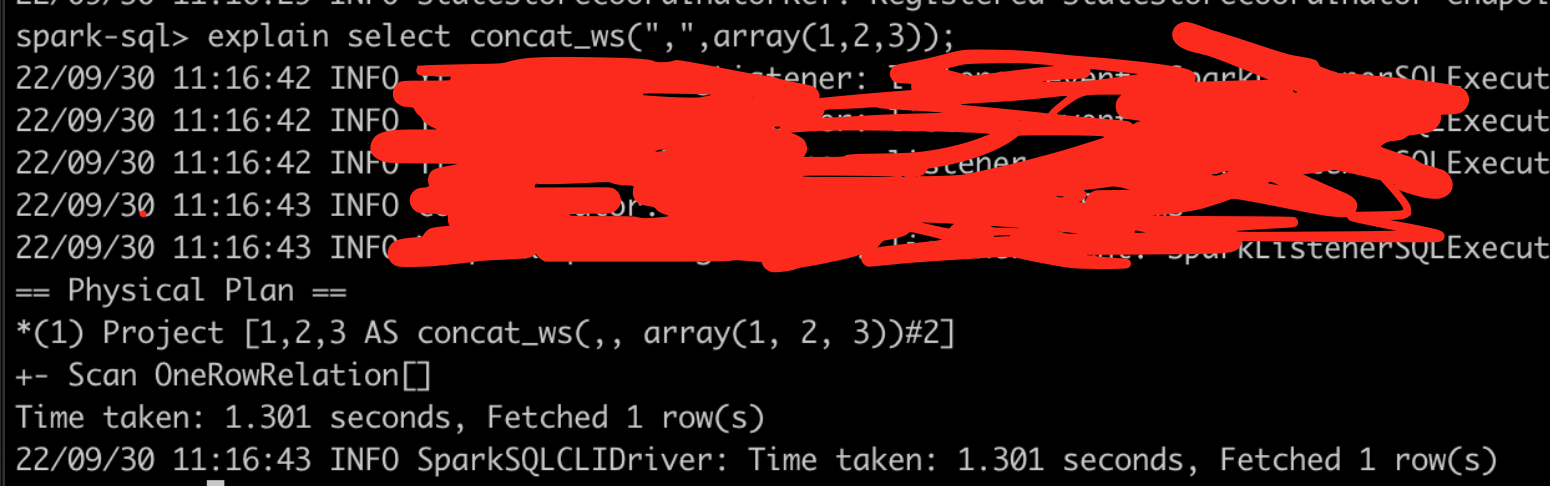
通过查看物理执行计划,并非如此,那么大概率是spark的concat_ws函数做了处理。
先来看一下concat_ws的源码。
1 | /** |
自spark1.5版本开始就支持concat_ws函数了。
可以看到传入的array<int> 在代码里被抽象成了Column[]数组。
该函数通过ConcatWs类处理传入Column[]的每条记录,再通过Literal.create创建回数据返回
接着再来看ConcatWs类
1 | override def eval(input: InternalRow): Any = { |
可以看到,当传入的是array时,走的是 case arr: ArrayData => arr.toArrayUTF8String ,将原本的array<>转换为array
toArray方法如下:
1 | def toArray[T: ClassTag](elementType: DataType): Array[T] = { |
将数据转换为传入类型的array,而传入类型为StringType,这就是spark的concat_ws函数能处理array<int>的原因,函数内部将array<int>转换为了array<string>进行处理。
maxcomputer运行结果
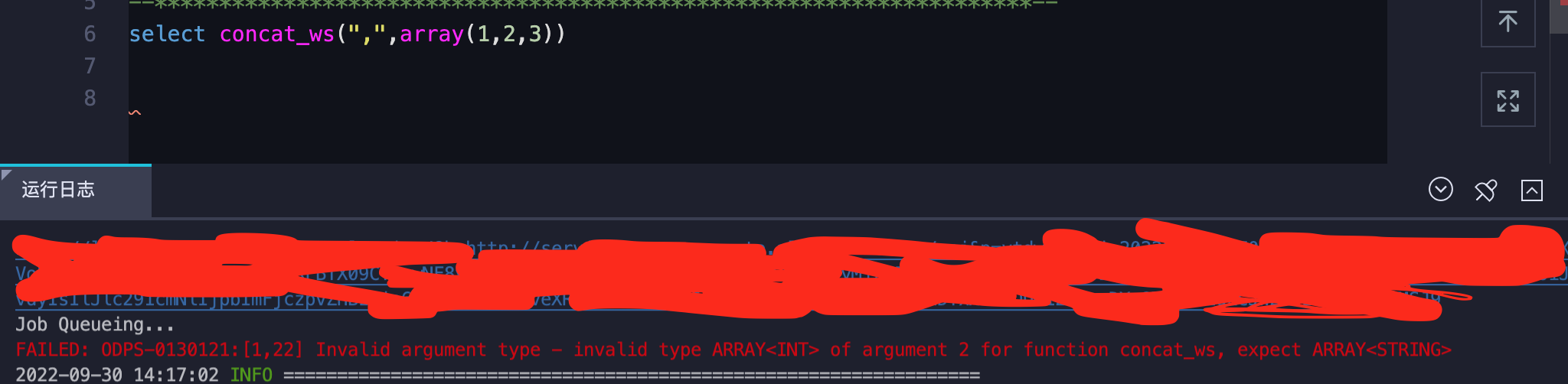
maxcomputer会报异常:
1 | FAILED: ODPS-0130121:[1,22] Invalid argument type - invalid type ARRAY<INT> of argument 2 for function concat_ws, expect ARRAY<STRING> |
提示的是concat_ws只支持ARRAY<STRING>格式,不支持array<int>,这个在阿里云的官方文档函数CONCAT_WS中有说明
hive运行结果
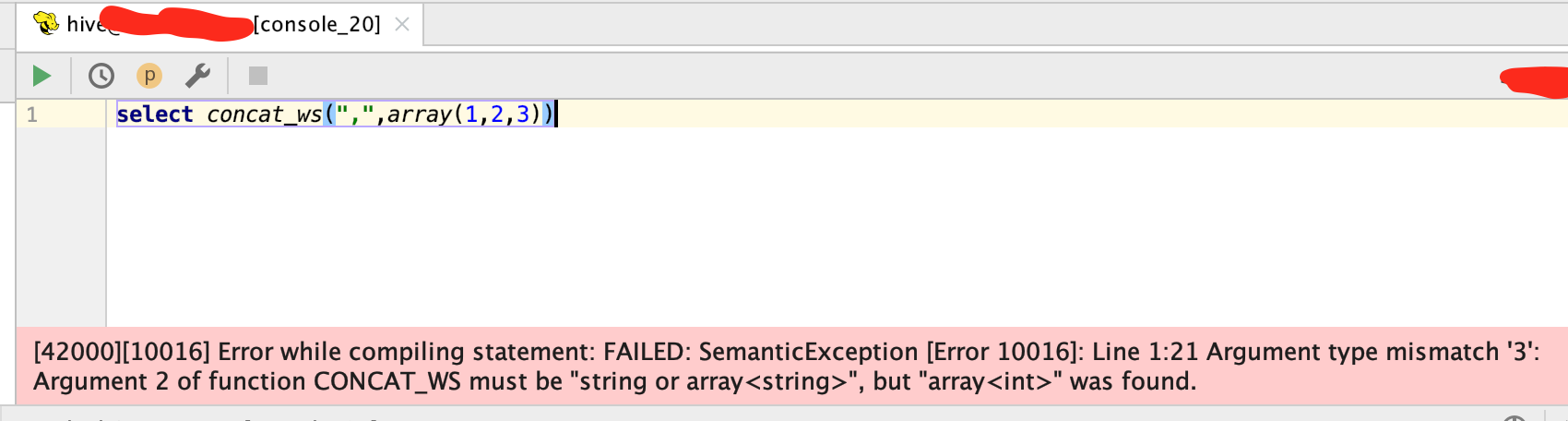
hive会报错:
1 | [42000][10016] Error while compiling statement: FAILED: SemanticException [Error 10016]: Line 1:21 Argument type mismatch '3': Argument 2 of function CONCAT_WS must be "string or array<string>", but "array<int>" was found. |
提示的是concat_ws传入的array必须是array<string>,不能是其他类型
替换方案
maxcomputer 替换方案
有两种,一种为使用cast函数,将array<int> 显示转换为array
1 | select array_contains(split("1,2,3,4",","),cast(1 as string)) |
一种为使用阿里提供的增强函数:array_join函数
1 | select array_join(array(1,2,3),",") |
本人推荐使用第二种
hive 替换方案
当array类型不为string时,目前hive没有函数可以支持此类需求,一个较复杂的方式为将array
1 | select concat_ws(',',collect_list(col_str)) as rs --行转列,并使用concat_ws |
上述方案太绕,万不得已的情况下,也只能如此了。
另一种方法,可以使用自定义udf解决。