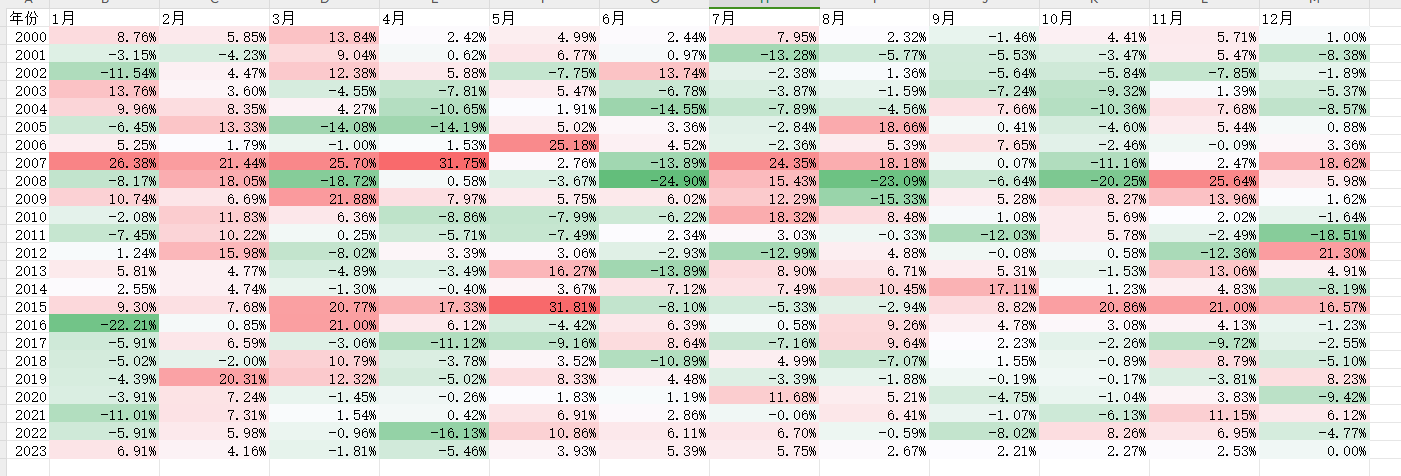
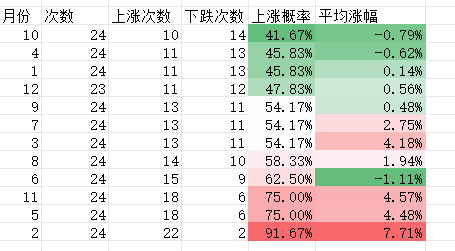
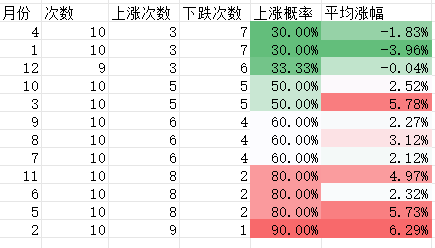
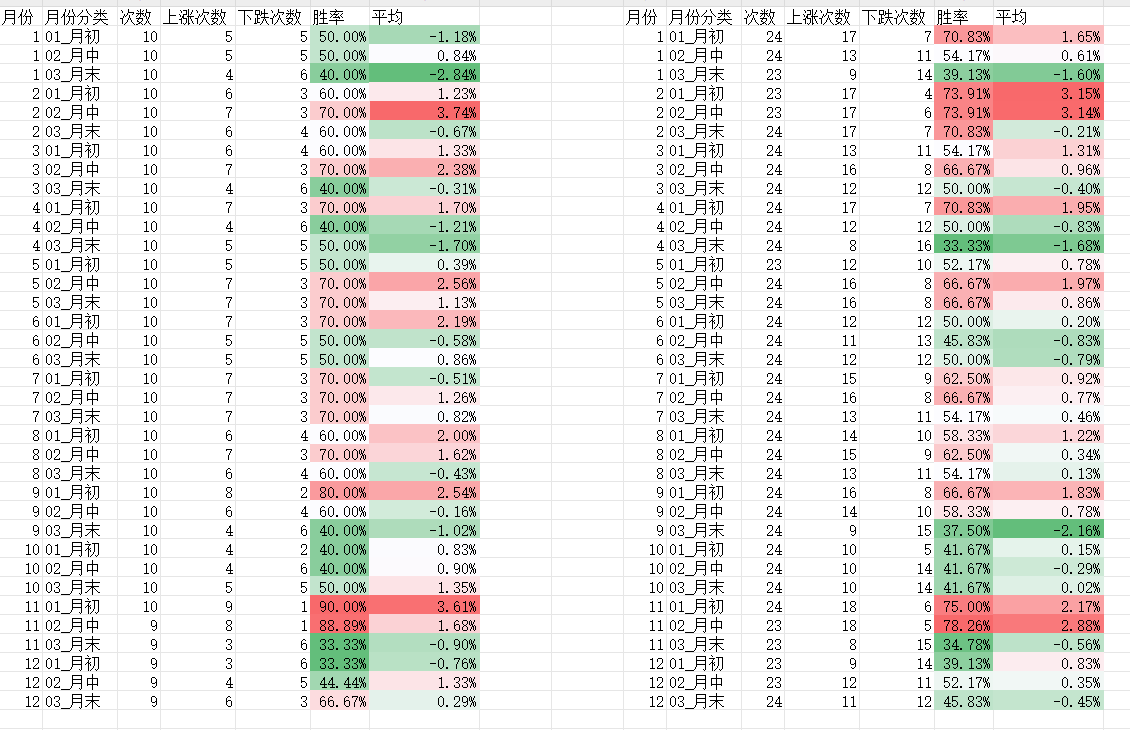
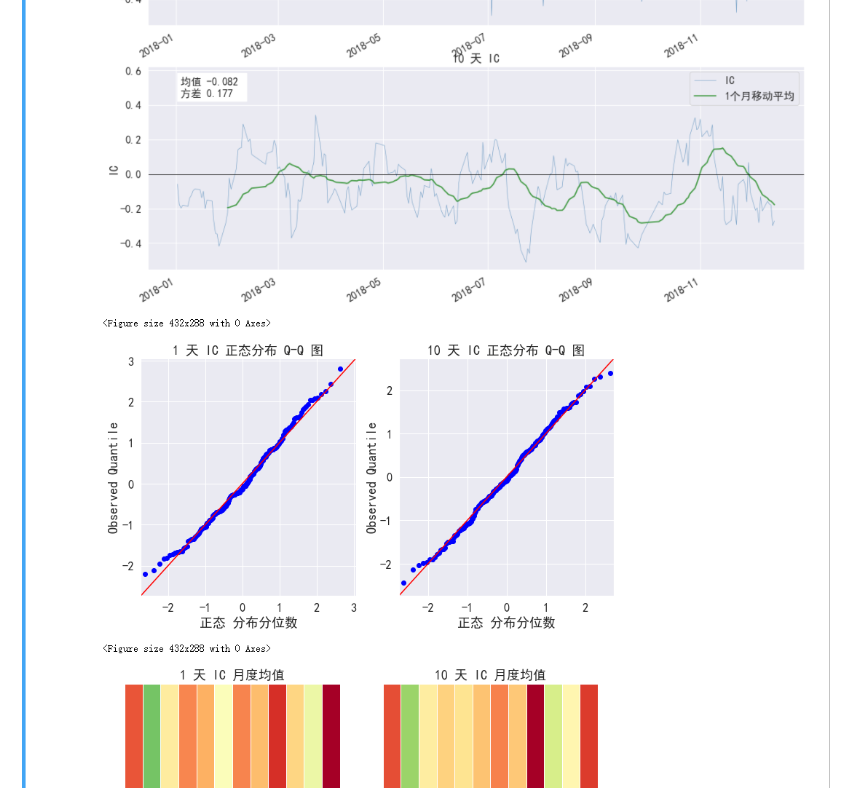
2024减肥记录
引言
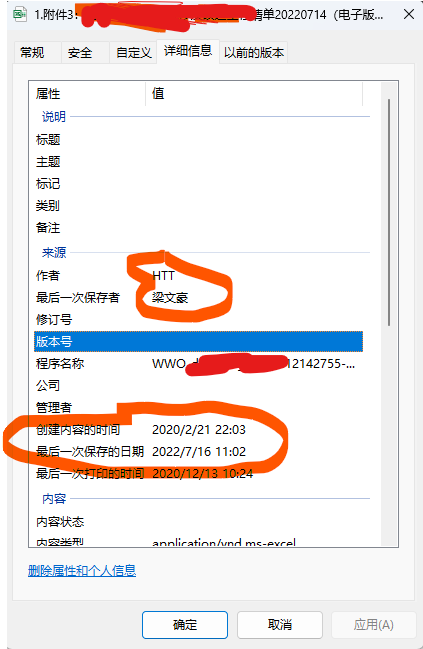
今天是2024年7月15日,上半年计划以失败而告终。新启一个。
目标
目标非常简单
77.5kg->65kg,一共12.5kg
记录
day1 2024-07-16 77.5kg
体重: 77.5kg
进度:0%
合计减重: 0kg
感想:跑路4公里,命快没了,跑完了炫了两个黄桃,两片西瓜,跑了等于没跑。。。。。
day2 2024-07-17 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:今日无运动,炫了两个黄桃,两片西瓜,罪过罪过。
day3 2024-07-18 77.5kg
体重: 77.5kg
进度: 0%,合计减重: 0kg
感想:今日跑步4公里,加油!晚上炫了两个桃子,一个梨,一瓶可乐,罪过。
day4 2024-07-19 77.7kg
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:吃了德克士,西瓜,无运动。。。。
day5 2024-07-20 77.7kg
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:无运动。。。。
day6 2024-07-21 77.7kg
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:无运动。。。。
day7 2024-07-22 77.7kg
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:无运动。。。。
day8 2024-07-23 78kg
体重: 78kg
进度: -4%,合计减重: -0.5kg
感想:体重新高了,跑步4公里,整体跑步还是不行,不知道是呼吸还是跑姿的问题,8公里配速心率直接180,6公里配置直接干到200.。。。。
day9 2024-07-24 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:跑步四公里,平均配速7-8,心率第一圈150,第二,三圈160,第四圈170,还是跑不快,不知道是呼吸还是姿势;
体重能不能下降,看吧,冲刺77瓶颈。
day10 2024-07-25 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:今日无运动,复制黏贴
day11 2024-07-26 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:今日无运动,复制黏贴
day12 2024-07-27 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:今日无运动,复制黏贴
day13 2024-07-28 77.3kg
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:今日无运动,复制黏贴
day14 2024-07-29 78.5kg
体重: 78.5kg
进度: -8%%,合计减重: -1kg
感想:跑步4公里
day15 2024-07-30 78.2kg
体重: 78.2kg
进度: -5.6%,合计减重: -0.7kg
感想:跑步4公里
day16 2024-07-31 77.5kg
体重: 77.5kg
进度: 0%,合计减重: 0kg
感想:今日休息
day17 2024-08-01 78.2kg
体重: 78.2kg
进度: -5.6%,合计减重: -0.7kg
感想:21天减肥计划day01
day18 2024-08-02 78.2kg
体重: 78.2kg
进度: -5.6%,合计减重: -0.7kg
感想:21天减肥计划day02
day19 2024-08-03 78.2kg
体重: 78.2kg
进度: -5.6%,合计减重: -0.7kg
感想:无运动
day20 2024-08-04 78.2kg
体重: 78.2kg
进度: -5.6%,合计减重: -0.7kg
感想:打篮球半小时
day21 2024-08-05 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:跑步5公里,心率控制在150~160之间。
day22 2024-08-06 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:体重无变化,跑步5公里,心率在155~165之间,配速8.
day23 2024-08-07 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:体重无变化,休息一天,吃西瓜,葡萄。
day24 2024-08-08 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:跑步5公里,心率155~160之间,配速8,跑完腿疼。
day25 2024-08-09 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:跑步5公里,心率155~160之间,配速8,累。
day26 2024-08-09 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:今日吃烧烤,休息,瓶颈期,体重是一动不动啊。
day27 2024-08-10 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:继续休息,无运动。
day28 2024-08-11 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:无运动。
day29 2024-08-12 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:21天减肥计划day03,体重继续无变化。
day30 2024-08-13 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:体重还是无变化,刚出去跑步天就下雨了,回家21天减肥计划day04,主要为腹部和拉伸,同时下午的时候非常饿,需要看下有没扛饿的零食。
措施:晚上不吃东西。
day31 2024-08-14 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:体重纹丝不动,昨晚回来晚了,没哟u运动。。
day32 2024-08-15 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:万年78.1,一周没动过了,今晚跑步5公里,配速7分30吧,心率控制的不错,一开始只有150多,后面到160多,步频163.回来后21天减肥计划day05,2轮hit。
day33 2024-08-16 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:无变化,今日无运动。
day34 2024-08-17 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:启动游,今日无运动。
day35 2024-08-18 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:启动游,今日无运动。
day36 2024-08-19 78.1kg
体重: 78.1kg
进度: -4.8%,合计减重: -0.6kg
感想:第19天体重无变化,跑步5公里,配速7.32,心率154,步频164
day37 2024-08-20 【0.8%】
体重: 77.4kg
进度: 0.8%,合计减重: 0.1kg
感想:哭死,体重终于变了,77.4,第20天了,减了0.1kg,21天减肥计划day06,tabeta,同一动作做7组,加油!。
day38 2024-08-21 【0.8%】
体重: 77.4kg
进度: 0.8%,合计减重: 0.1kg
感想:跑步5公里,配速7.14,心率159,步频167;21天减肥计划day07,拉升,加油!。
day39 2024-08-22 【5.6%】
体重: 76.8kg
进度: 5.6%,合计减重: 0.7kg
感想:本轮体重新低,加油!!
day21训练计划day08,今天hit,和儿子一起练的。
跑步5公里,心率160,步频163,配速7.49,比昨天差了非常多,不知道是连续跑步累了还是因为先做了hit累了。。
day40 2024-08-23 【0.8%】
体重: 77.4kg
进度: 0.8%,合计减重: 0.1kg
感想:无运动,今日疲劳,休息。
day41 2024-08-24 【0.8%】
体重: 77.4kg
进度: 0.8%,合计减重: 0.1kg
感想:无运动,今日疲劳,休息。
day42 2024-08-25 【0.8%】
体重: 77.4kg
进度: 0.8%,合计减重: 0.1kg
感想:无运动,今日疲劳,休息。
day43 2024-08-26【-2.4%】
体重: 77.8kg
进度: -2.4%,合计减重: -0.3kg
感想:周末胡吃海喝体重反弹了,day21运动day09,跑步5公里。。心率163,步频163,配速7.16
day44 2024-08-27【-2.4%】
体重: 77.8kg
进度: -2.4%,合计减重: -0.3kg
感想:体重无变化。day21运动day10,跑步5公里。。心率162,步频169,配速6.57,步频配速提升极大。
day45 2024-08-28【-2.4%】
体重: 77.8kg
进度: -2.4%,合计减重: -0.3kg
感想:休息
day46 2024-08-29【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:太累了,今日休息。
day47 2024-08-30【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:无运动。
day48 2024-08-31【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:无运动。
day49 2024-09-01【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:无运动。
day50 2024-09-02【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:体重5天没有变化了,跑步5公里。心率164,步频171,配速6.36,跑的不错。
day51 2024-09-03【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day52 2024-09-04【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day53 2024-09-04【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day54 2024-09-05【2.4%】
体重: 77.2kg
进度: 2.4%,合计减重: 0.3kg
感想:跑步5公里,day21天减肥计划第14天。
day55 2024-09-06【5.6%】
体重: 76.8kg
进度: 5.6%,合计减重: 0.7kg
感想:加油。
day56 2024-09-07【5.6%】
体重: 76.8kg
进度: 5.6%,合计减重: 0.7kg
感想:南北湖森泊游玩,无运动,加油。
day57 2024-09-08【5.6%】
体重: 76.8kg
进度: 5.6%,合计减重: 0.7kg
感想:南北湖森泊游玩,无运动,加油。
day58 2024-09-09【3.2%】
体重: 77.1kg
进度: 3.2%,合计减重: 0.4kg
感想:21天减肥训练day16,hitx4,波比跳,高抬腿,后踢腿,俯身登山
跑步5公里,心率168,步频171,配速6.2,心率偏高
day59 2024-09-10【4.8%】
体重: 76.9kg
进度: 4.8%,合计减重: 0.6kg
感想:下雨,无运动,加油。
day60 2024-09-11【5.6%】
体重: 76.8kg
进度: 5.6%,合计减重: 0.7kg
感想:加班回到家有点晚。
day61 2024-09-12【8.8%】
体重: 76.4kg
进度: 8.8%,合计减重: 1.1kg
感想:加油。
day62 2024-09-13【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:加油。
day63 2024-09-14【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:中秋,今日无运动。
day64 2024-09-15【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:中秋,今日无运动。
day65 2024-09-16【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:中秋,今日无运动。
day66 2024-09-17【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:中秋,今日无运动。
day67 2024-09-18【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:中秋放纵了,加油,留给的时间不多了。
day68 2024-09-19【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day69 2024-09-20【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day70 2024-09-21【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day71 2024-09-22【1.6%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day72 2024-09-23【-1.6%】
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:加油。
day73 2024-09-24【-1.6%】
体重: 77.7kg
进度: -1.6%,合计减重: -0.2kg
感想:加油。
day74 2024-09-25【6.4%】
体重: 76.7kg
进度: 6.4%,合计减重: 0.8kg
感想:加油。
day75 2024-09-26【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day76 2024-09-27【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day77 2024-09-28【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day78 2024-09-29【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day79 2024-09-30【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day80 2024-10-01【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day81 2024-10-02【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day82 2024-10-03【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day83 2024-10-04【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day84 2024-10-05【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day85 2024-10-06【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day86 2024-10-07【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day87 2024-10-08【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
day88 2024-10-09【-2.4%】
体重: 77.3kg
进度: 1.6%,合计减重: 0.2kg
感想:加油。
结论
失败!!!