使用 python camelot 实现提取 pdf 中的表格内容
场景描述
最近有个需求需要处理下从南京统计局下载的宏观数据pdf,需要将pdf中的表格数据提取出来进一步加工,样例格式如下。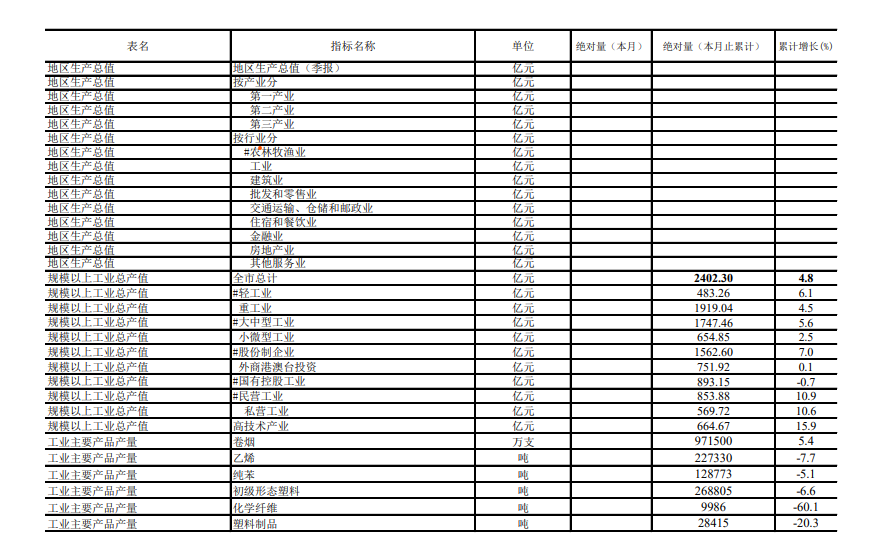
可以看到格式还是比较标准的,我本来以为网上随便一搜python pdf table提取,便能简单的处理大功搞成,然而实际还是踩了不少坑,因此还是记录下。
具体的pdf这里就不展示了,以camelot的样例pdf为例,下载可以点击此链接
技术选型
首先,我确实是在网上搜索python pdf table extract,基本很快就锁定了 pdfplumber,然而在一通操作后,发现pdfplumber的默认识别不太准确,一个很大的原因是pdf的表格很多并不是以标准的线画的,虽然可以使用text方式识别+定制化的一些参数,但是调整太累了,后面本人就放弃了。pdfplumber的官方文档参见pdfplumbergit地址,里面对于一些对象及配置有详尽的描述。另外,知乎的这篇关于python提取pdf不规则表格写得非常不错,里面有讲碰到不规则表格,提取内容错误时,如何利用 debug_tablefinder 画出红线,进而调整进阶参数以优化提取效果。
在pdfplumber碰壁后,继而了解到camelot在无线框表格上效果更好,因此果断尝试,不得不说最终的效果还是不错的。
camelot的git地址参见camelot git 地址,相对来说,camelot的文档就没有那么详尽了,不得不说是一个遗憾。
环境安装
camelot的安装挺坑的。。。,以下只是本人的安装和解决方案。
1. camelot安装
千万不要直接使用pip install camelot进行安装,真正的命令为
1 | pip install camelot-py |
安装完后,本人碰到了
1 | Python-camelot (Error: GhostscriptNotFound |
这个问题,参考网上的,到ghostscript官网下载对应的版本。
本人为windows,因此下载了ghostscript-10.01.1.tar.xz,解压完需要添加
1 | C:\Program Files\gs\gs9.26\bin |
到path下,不然依然会报错。
最后,你需要安装下ghostscript
1 | pip install ghostscript |
不然会得到以下错误
1 | PS C:/Users/ivan/AppData/Local/Programs/Python/Python311/python tjj_hgsj_py/nj_tjj.py |
至此,camelot安装完成。
代码实现
具体代码可以查看 camelot_pdf_table_parse
1 | import os |
整体代码就想对比较简单了,但是也有一些细节需要处理,方能最后使用,比如
- 读取所有page,camelot默认只读取pdf的第一页,因此需要all参数。
- 拼接dataframe
- 新增自定义列
- 保存csv去除行号
实现效果
pdf原始表格
提取后的dataframe效果
1 | report_date 0 1 2 3 4 5 6 |
最终的csv文件
1 | report_date,0,1,2,3,4,5,6 |
踩坑点及解决方法
Python-camelot (Error: GhostscriptNotFound
需要安装ghostscript
到ghostscript官网下载对应的版本。
ModuleNotFoundError: No module named ‘ghostscript’
安装完ghostscript程序后,还需安装ghostscript模块
1 | pip install ghostscript |
camelot只能读取pdf的第一页
参数需要填all
1 | tables= camelot.read_pdf(pdfFilePath,pages='all') |