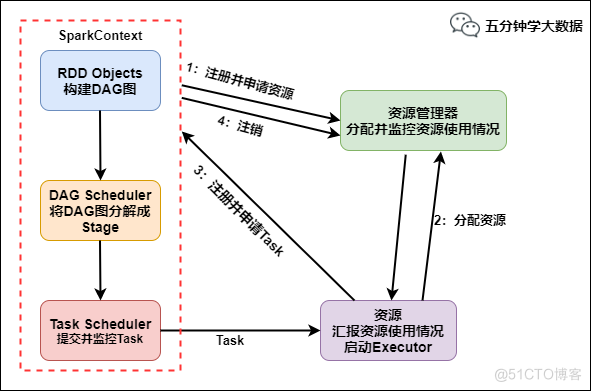
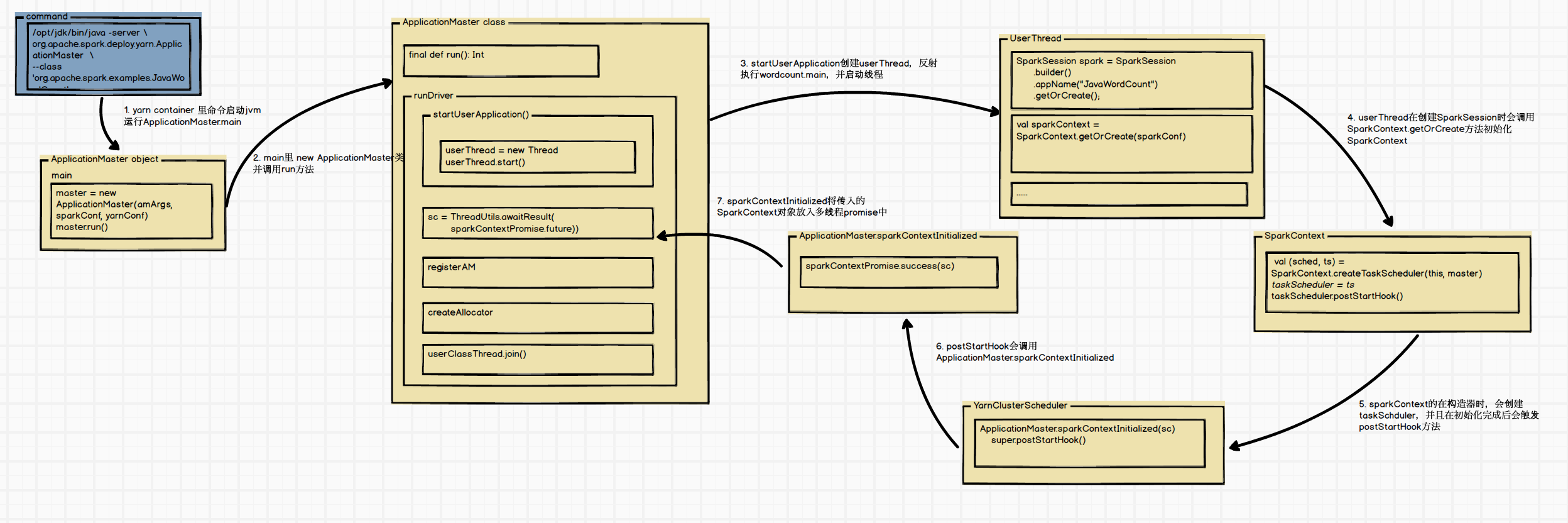
privatedefrunDriver(): Unit = { ...... //启动用户的application线程,即JavaWordCount的main类 userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has // been set by the Thread executing the user class. logInfo("Waiting for spark context initialization...") ...... try { val sc = ThreadUtils.awaitResult(sparkContextPromise.future, Duration(totalWaitTime, TimeUnit.MILLISECONDS)) if (sc != null) { ...... registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId) ...... createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf) } else { ...... } resumeDriver() userClassThread.join() } catch { ...... } finally { resumeDriver() } }
defgetOrCreate(): SparkSession = synchronized { ...... // Global synchronization so we will only set the default session once. SparkSession.synchronized { ...... val sparkContext = userSuppliedContext.getOrElse { ...... SparkContext.getOrCreate(sparkConf) // Do not update `SparkConf` for existing `SparkContext`, as it's shared by all sessions. } ...... }
return session } }
8. SparkContext.getOrCreate
该方法比较简单,主要用于获取或实例化 SparkContext ,并将其注册为单例对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defgetOrCreate(config: SparkConf): SparkContext = { // Synchronize to ensure that multiple create requests don't trigger an exception // from assertNoOtherContextIsRunning within setActiveContext SPARK_CONTEXT_CONSTRUCTOR_LOCK.synchronized { if (activeContext.get() == null) { setActiveContext(newSparkContext(config)) } else { if (config.getAll.nonEmpty) { logWarning("Using an existing SparkContext; some configuration may not take effect.") } } activeContext.get() } }
privatedefsparkContextInitialized(sc: SparkContext) = { sparkContextPromise.synchronized { // Notify runDriver function that SparkContext is available sparkContextPromise.success(sc) // Pause the user class thread in order to make proper initialization in runDriver function. sparkContextPromise.wait() } }
privatedefcreateAllocator( driverRef: RpcEndpointRef, _sparkConf: SparkConf, rpcEnv: RpcEnv, appAttemptId: ApplicationAttemptId, distCacheConf: SparkConf): Unit = { ..... val appId = appAttemptId.getApplicationId().toString() val driverUrl = RpcEndpointAddress(driverRef.address.host, driverRef.address.port, CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString val localResources = prepareLocalResources(distCacheConf)
// Before we initialize the allocator, let's log the information about how executors will // be run up front, to avoid printing this out for every single executor being launched. // Use placeholders for information that changes such as executor IDs. logInfo { val executorMemory = _sparkConf.get(EXECUTOR_MEMORY).toInt val executorCores = _sparkConf.get(EXECUTOR_CORES) val dummyRunner = newExecutorRunnable(None, yarnConf, _sparkConf, driverUrl, "<executorId>", "<hostname>", executorMemory, executorCores, appId, securityMgr, localResources, ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID) dummyRunner.launchContextDebugInfo() }
// Initialize the AM endpoint *after* the allocator has been initialized. This ensures // that when the driver sends an initial executor request (e.g. after an AM restart), // the allocator is ready to service requests. rpcEnv.setupEndpoint("YarnAM", newAMEndpoint(rpcEnv, driverRef))
allocator.allocateResources() val ms = MetricsSystem.createMetricsSystem(MetricsSystemInstances.APPLICATION_MASTER, sparkConf) val prefix = _sparkConf.get(YARN_METRICS_NAMESPACE).getOrElse(appId) ms.registerSource(newApplicationMasterSource(prefix, allocator)) // do not register static sources in this case as per SPARK-25277 ms.start(false) metricsSystem = Some(ms) reporterThread = launchReporterThread() }