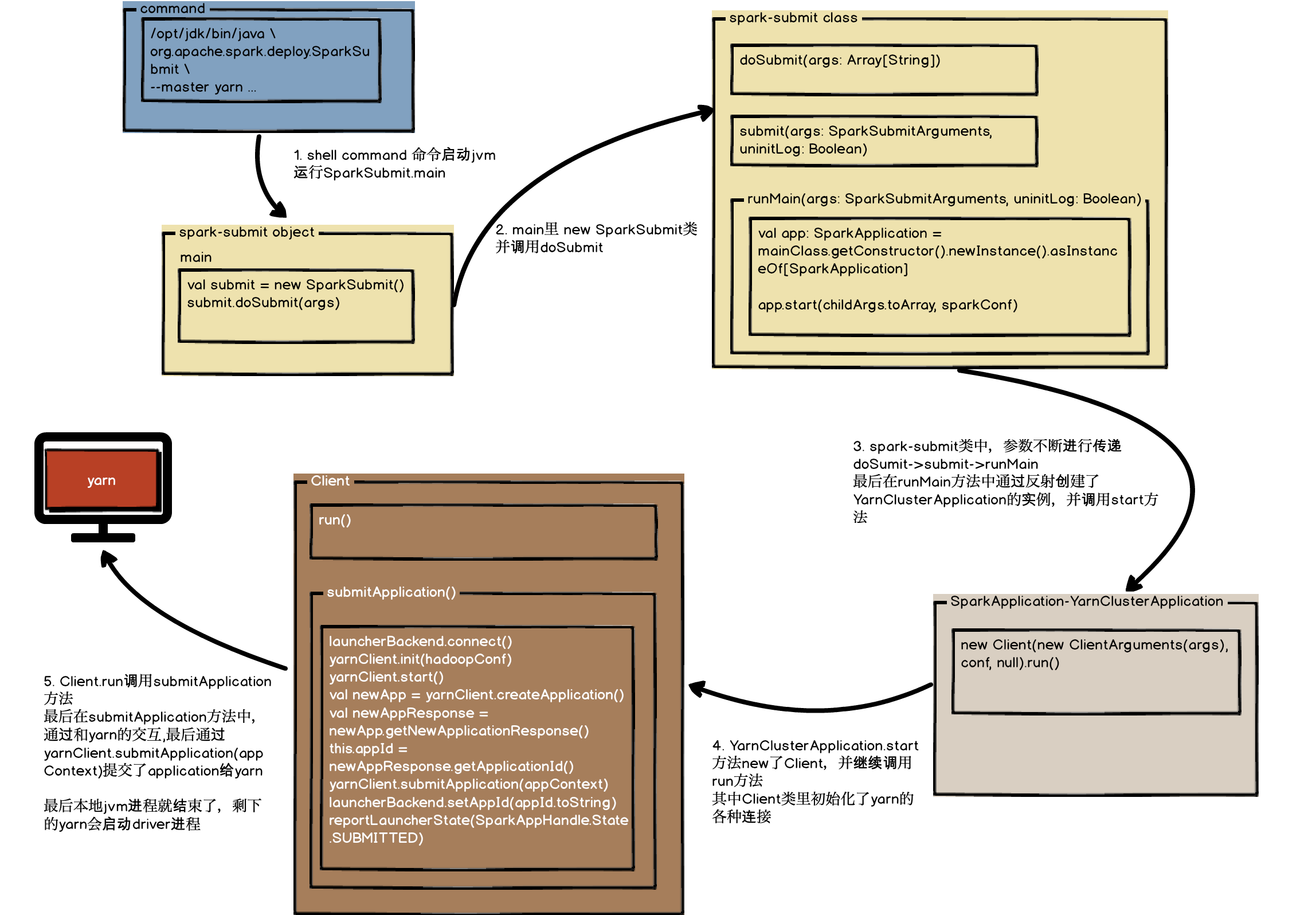
//submit->doRunMain->runMain submit方法中直接调用函数doRunMain,doRunMain判断是否需要代理用户,之后就调用runMain方法 privatedefsubmit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = { defdoRunMain(): Unit = { if (args.proxyUser != null) { ...... } else { runMain(args, uninitLog) } }
// In standalone cluster mode, there are two submission gateways: // (1) The traditional RPC gateway using o.a.s.deploy.Client as a wrapper // (2) The new REST-based gateway introduced in Spark 1.3 // The latter is the default behavior as of Spark 1.3, but Spark submit will fail over // to use the legacy gateway if the master endpoint turns out to be not a REST server. if (args.isStandaloneCluster && args.useRest) { try { logInfo("Running Spark using the REST application submission protocol.") doRunMain() } catch { // Fail over to use the legacy submission gateway case e: SubmitRestConnectionException => logWarning(s"Master endpoint ${args.master} was not a REST server. " + "Falling back to legacy submission gateway instead.") args.useRest = false submit(args, false) } // In all other modes, just run the main class as prepared } else { doRunMain() } }
overridedefstart(args: Array[String], conf: SparkConf): Unit = { // SparkSubmit would use yarn cache to distribute files & jars in yarn mode, // so remove them from sparkConf here for yarn mode. conf.remove(JARS) conf.remove(FILES) conf.remove(ARCHIVES)
if (log.isDebugEnabled) { logDebug("Requesting a new application from cluster with %d NodeManagers" .format(yarnClient.getYarnClusterMetrics.getNumNodeManagers)) }
// Get a new application from our RM val newApp = yarnClient.createApplication() val newAppResponse = newApp.getNewApplicationResponse() this.appId = newAppResponse.getApplicationId()
// The app staging dir based on the STAGING_DIR configuration if configured // otherwise based on the users home directory. // scalastyle:off FileSystemGet val appStagingBaseDir = sparkConf.get(STAGING_DIR) .map { newPath(_, UserGroupInformation.getCurrentUser.getShortUserName) } .getOrElse(FileSystem.get(hadoopConf).getHomeDirectory()) stagingDirPath = newPath(appStagingBaseDir, getAppStagingDir(appId)) // scalastyle:on FileSystemGet
// Verify whether the cluster has enough resources for our AM verifyClusterResources(newAppResponse)
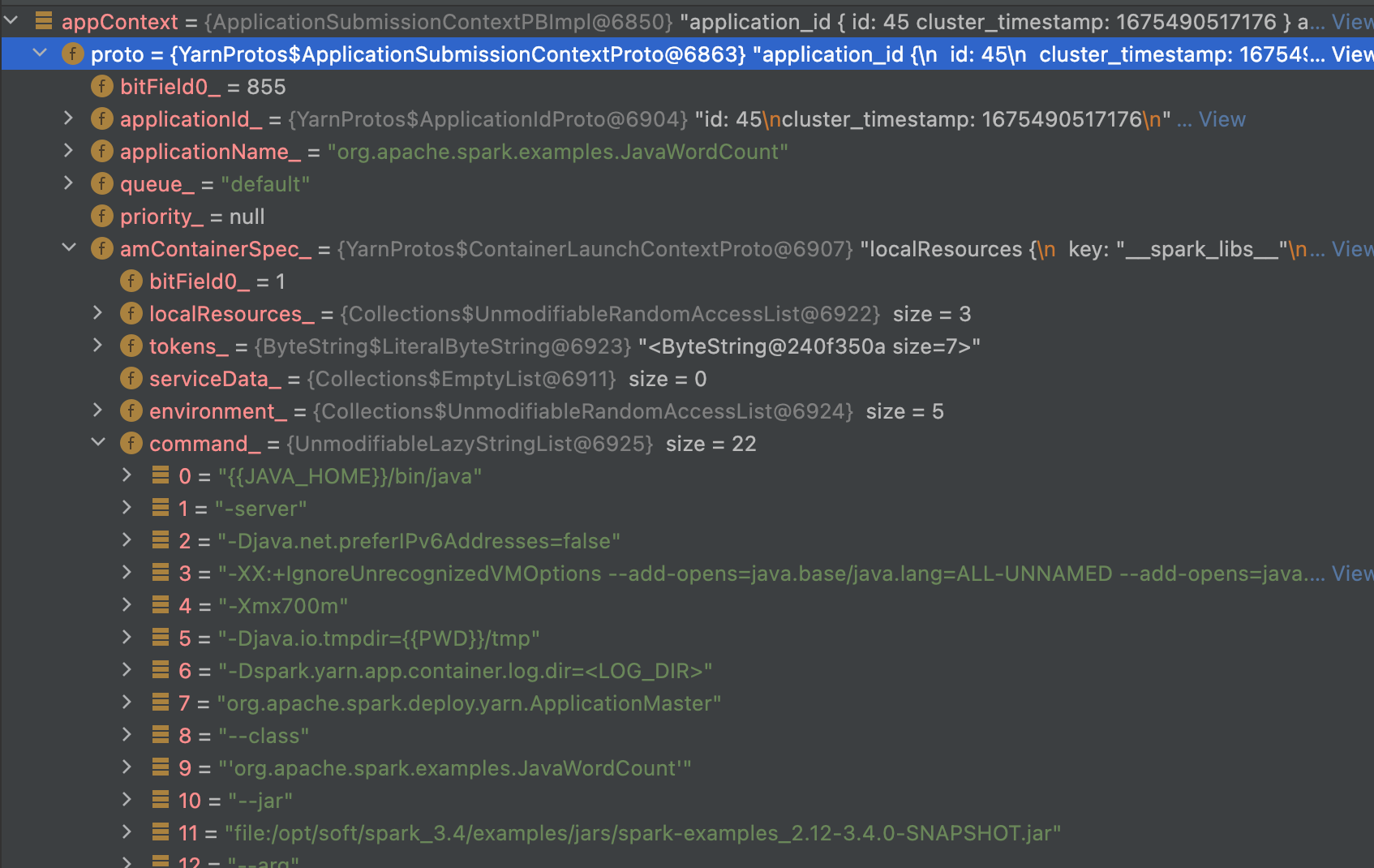
// Set up the appropriate contexts to launch our AM val containerContext = createContainerLaunchContext() val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application logInfo(s"Submitting application $appId to ResourceManager") yarnClient.submitApplication(appContext) launcherBackend.setAppId(appId.toString) reportLauncherState(SparkAppHandle.State.SUBMITTED) } catch { case e: Throwable => if (stagingDirPath != null) { cleanupStagingDir() } throw e } }
6. 至此,本地jvm进程就结束了,剩下的yarn会启动driver进程
其他补充
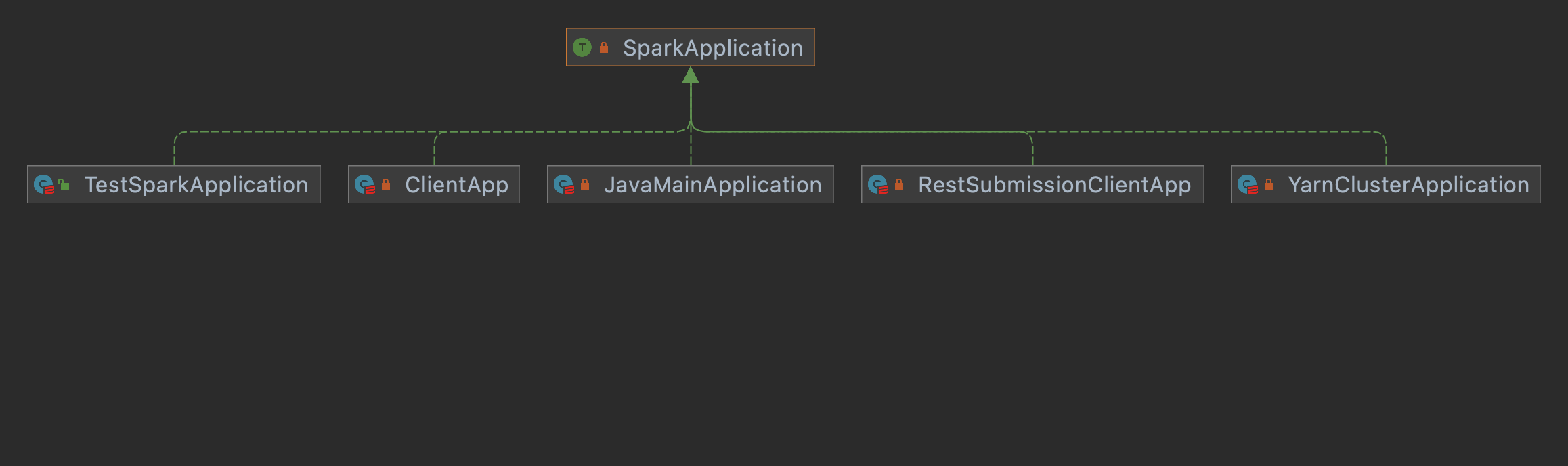
SparkApplication
1 2 3 4 5 6 7 8
/** * Entry point for a Spark application. Implementations must provide a no-argument constructor. */ private[spark] traitSparkApplication{
defstart(args: Array[String], conf: SparkConf): Unit
defsubmitApplication(): Unit = { ResourceRequestHelper.validateResources(sparkConf) ...... try { // Set up the appropriate contexts to launch our AM val containerContext = createContainerLaunchContext() val appContext = createApplicationSubmissionContext(newApp, containerContext) ...... } ..... }
//根据amArgs参数拼装最后执行的命令 // Command for the ApplicationMaster val commands = prefixEnv ++ Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++ javaOpts ++ amArgs ++ Seq( "1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout", "2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
// TODO: it would be nicer to just make sure there are no null commands here val printableCommands = commands.map(s => if (s == null) "null"else s).toList //将命令传递给amContainer并返回。 amContainer.setCommands(printableCommands.asJava) ...... }
最后,通过
1
val appContext = createApplicationSubmissionContext(newApp, containerContext)