Spark SQL内部剖析 阅读笔记
背景
本文为个人阅读Spark SQL内部剖析书籍时,记录一些名词解释,方便个人阅读理解
#SQL 转换过程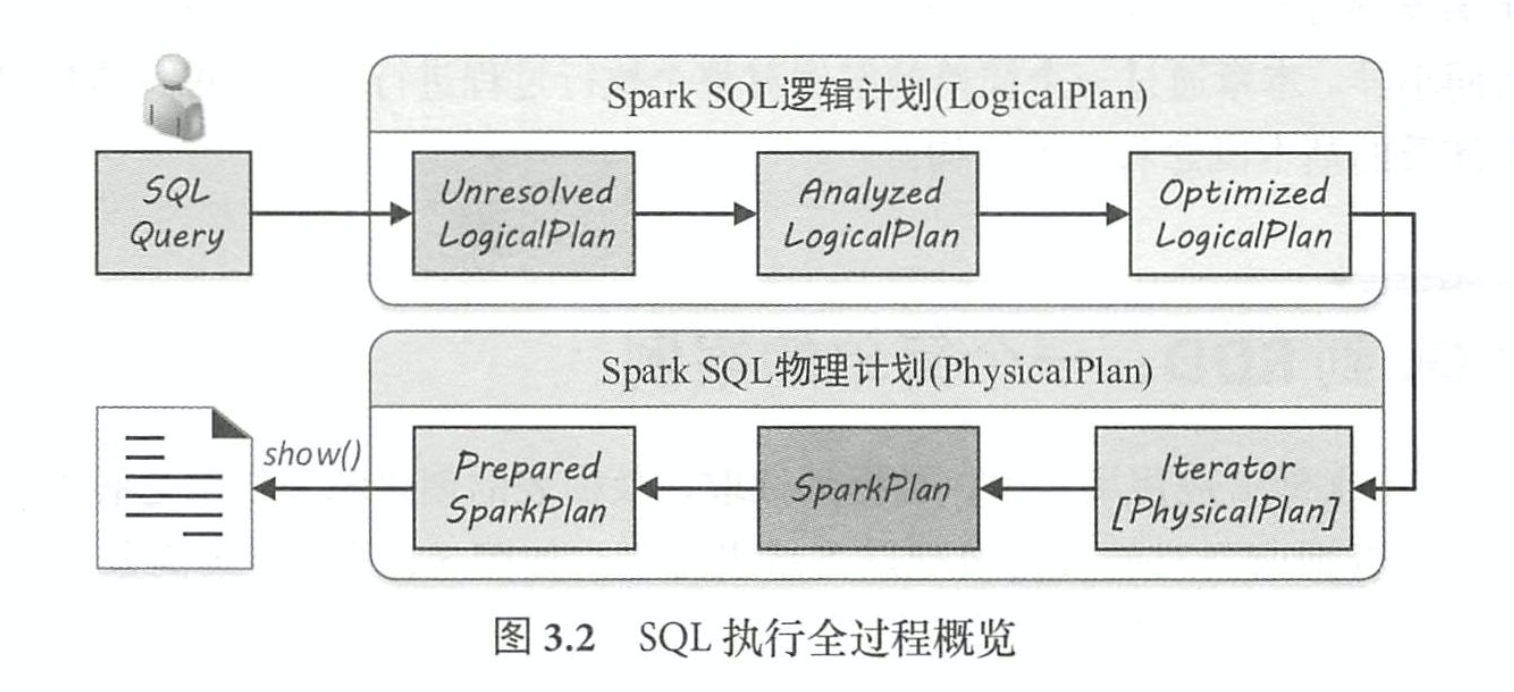
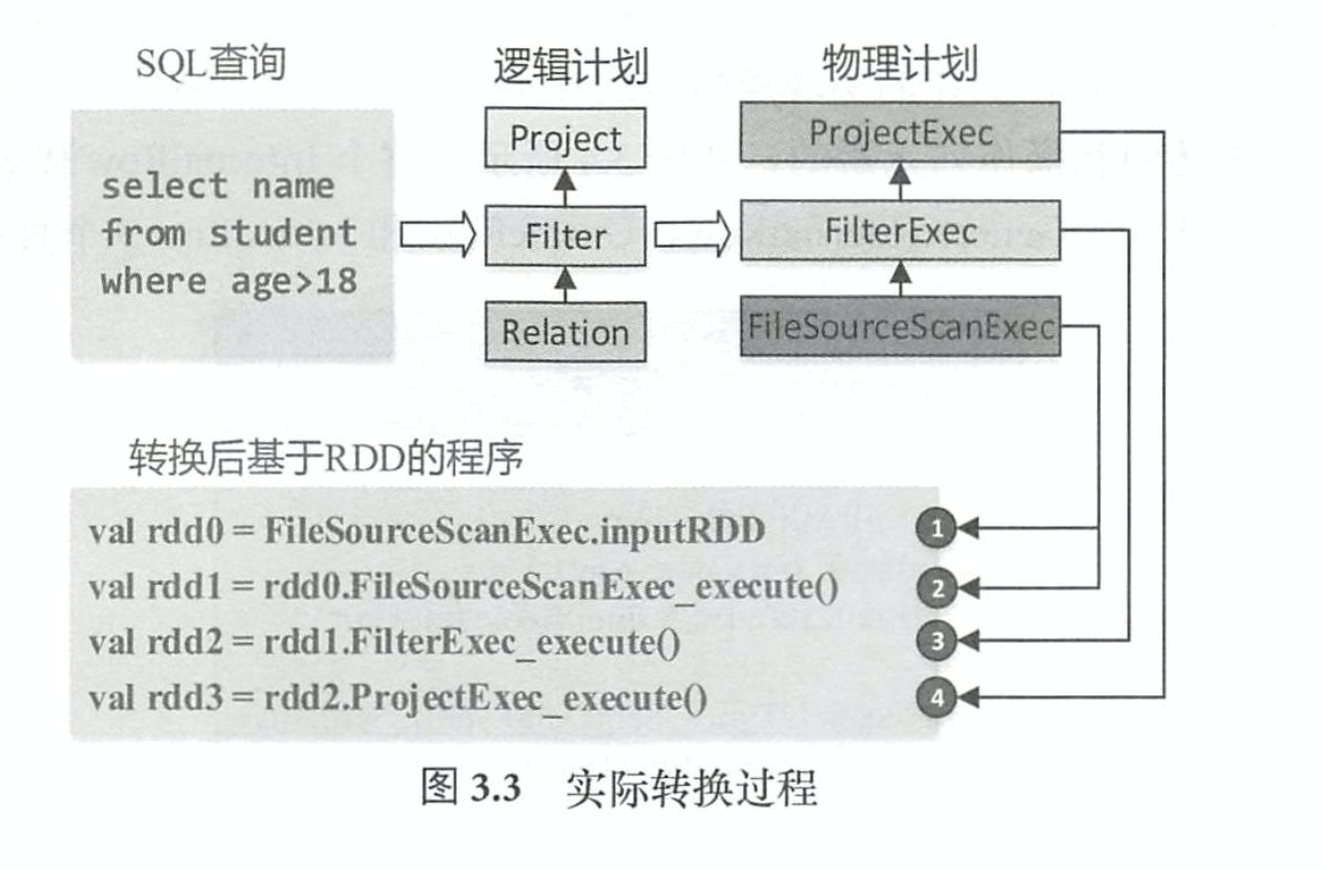
- Relation、
数据表 - Filter
过滤逻辑(age>l8) - Project
列剪裁逻辑 (只涉及3列中的2列)
ROW
数据处理首先需要考虑如何表示数据 。 对于关系表来讲,通常操作的数据都是以“行”为单 位的 。 在 SparkSQL 内部实现中, InternalRow就是用来表示一行行数据的类
TreeNode
无论是逻辑计划还是物理计划,都离不开中间数据结构。在 Catalyst 中,对应的是 TreeNode体系 。 TreeNode类是 SparkSQL 中所有树结构的基类,定义了一 系列通用的集合操作和树遍历操作接口 。
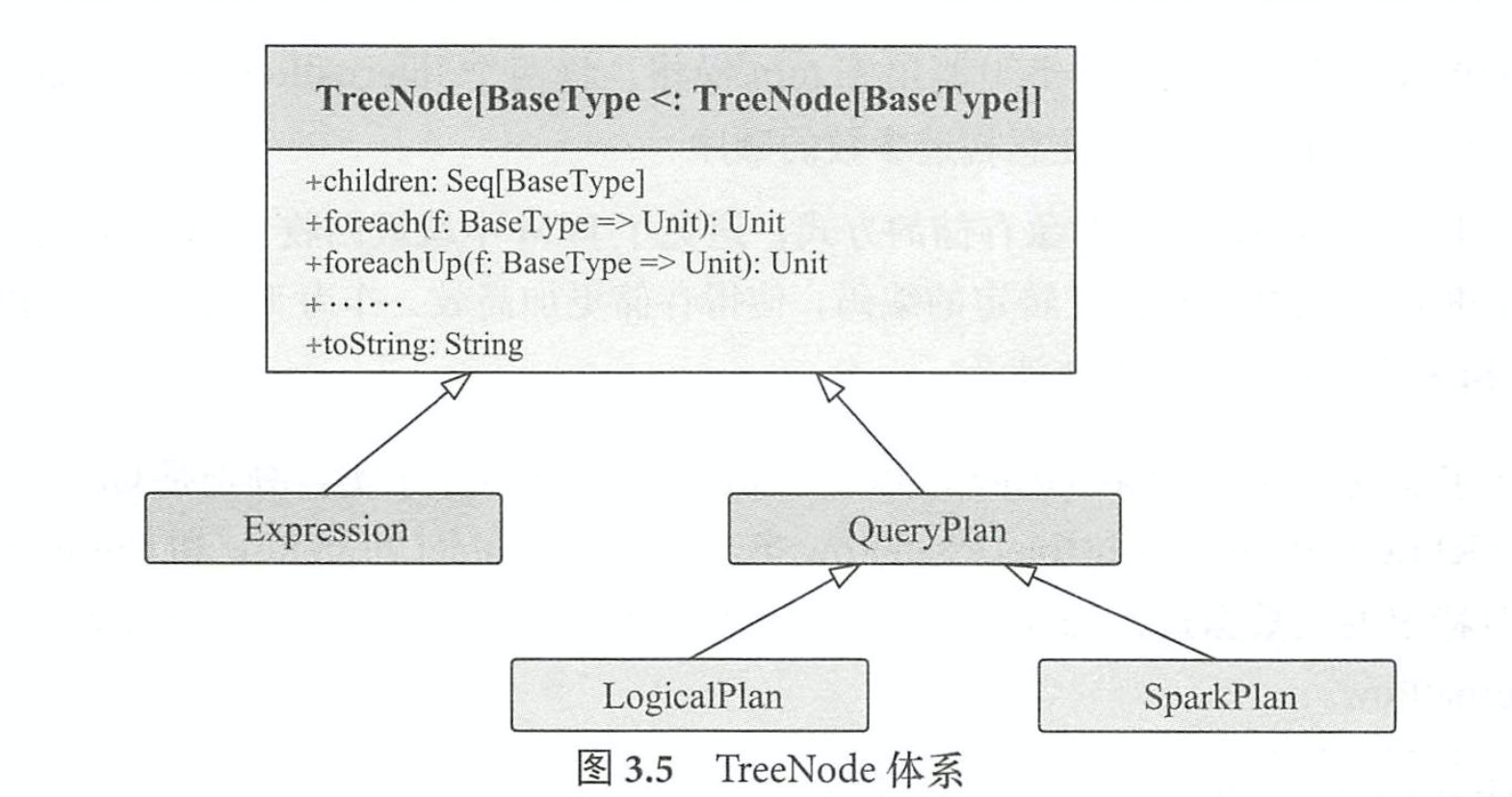
Expression 体系
表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运 算、逻辑操作、转换操作、过滤操作等。 如果说TreeNode是“框架”,那么Expression就是“灵 魂”。
4.2 SparkSqlParser之AstBuilder
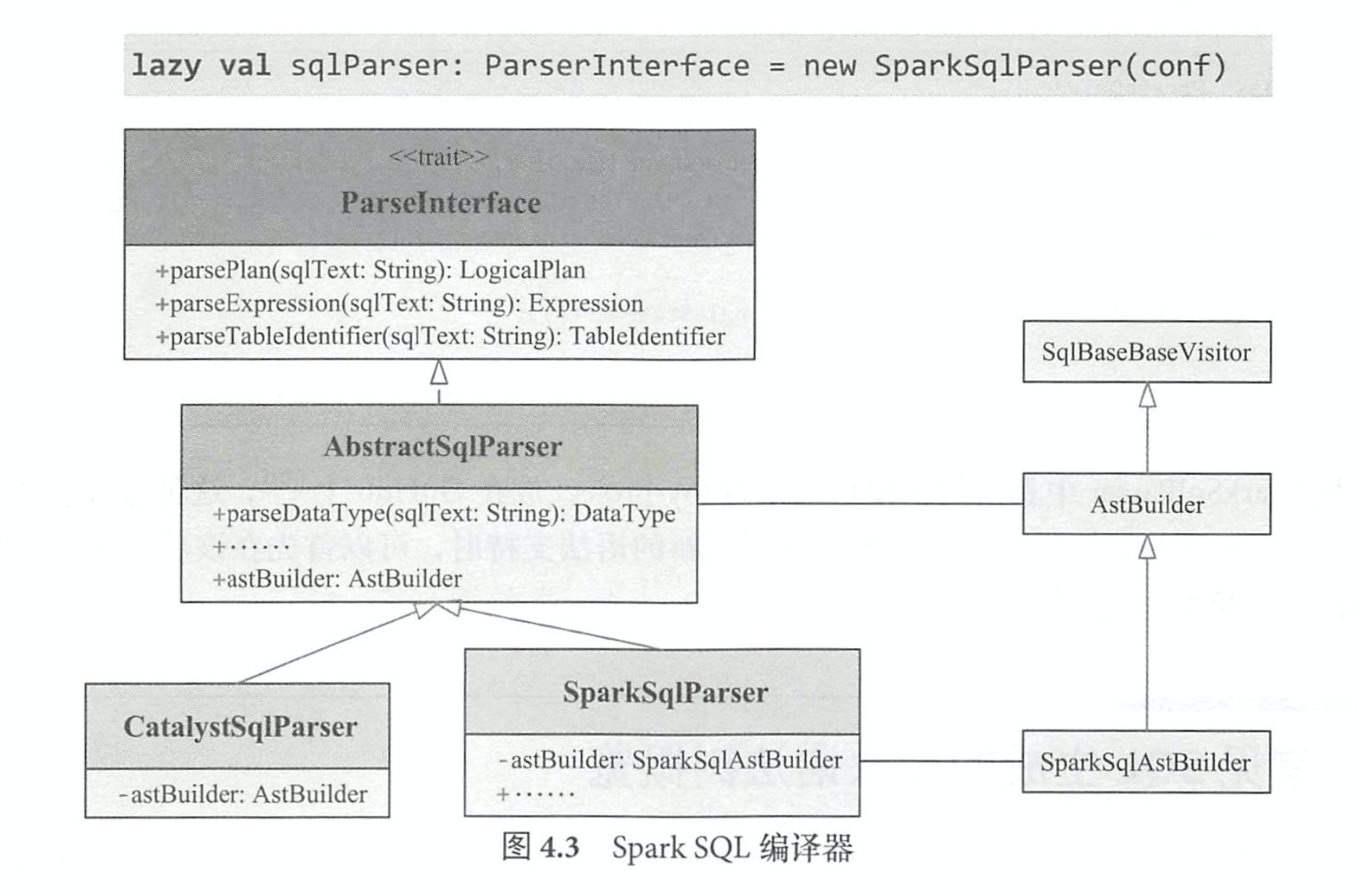
其中,比较核心的是 AstBuilder,它继承了 ANTLR4 生成的默认 SqlBaseBaseVisitor,用于生成 SQL对应的抽象语法树 AST (Unresolved LogicalPlan); SparkSqlAst- Builder 继承 AstBuilder,并在其基础上定义了 一 些 DDL 语句的访问操作,主要在 SparkSqlParser 中调用 。
当面临开发新的语法支持时,首先需要改动的是 ANTLR4 文件(在 Sq1Base.g4 中添加文法), 重新生成词法分析器( SqlBaseLexer)、语法分析器( SqlBaseParser)和访问者类( SqlBaseVisitor 接口与 SqlBaseBaseVisitor类),然后在 AstBuilder等类中添加相应的访问逻辑,最后添加执行逻 辑。
Context
在 Catalyst中, SQL 语句经过解析,生成的抽象语法树节点都以 Context结尾来命名 。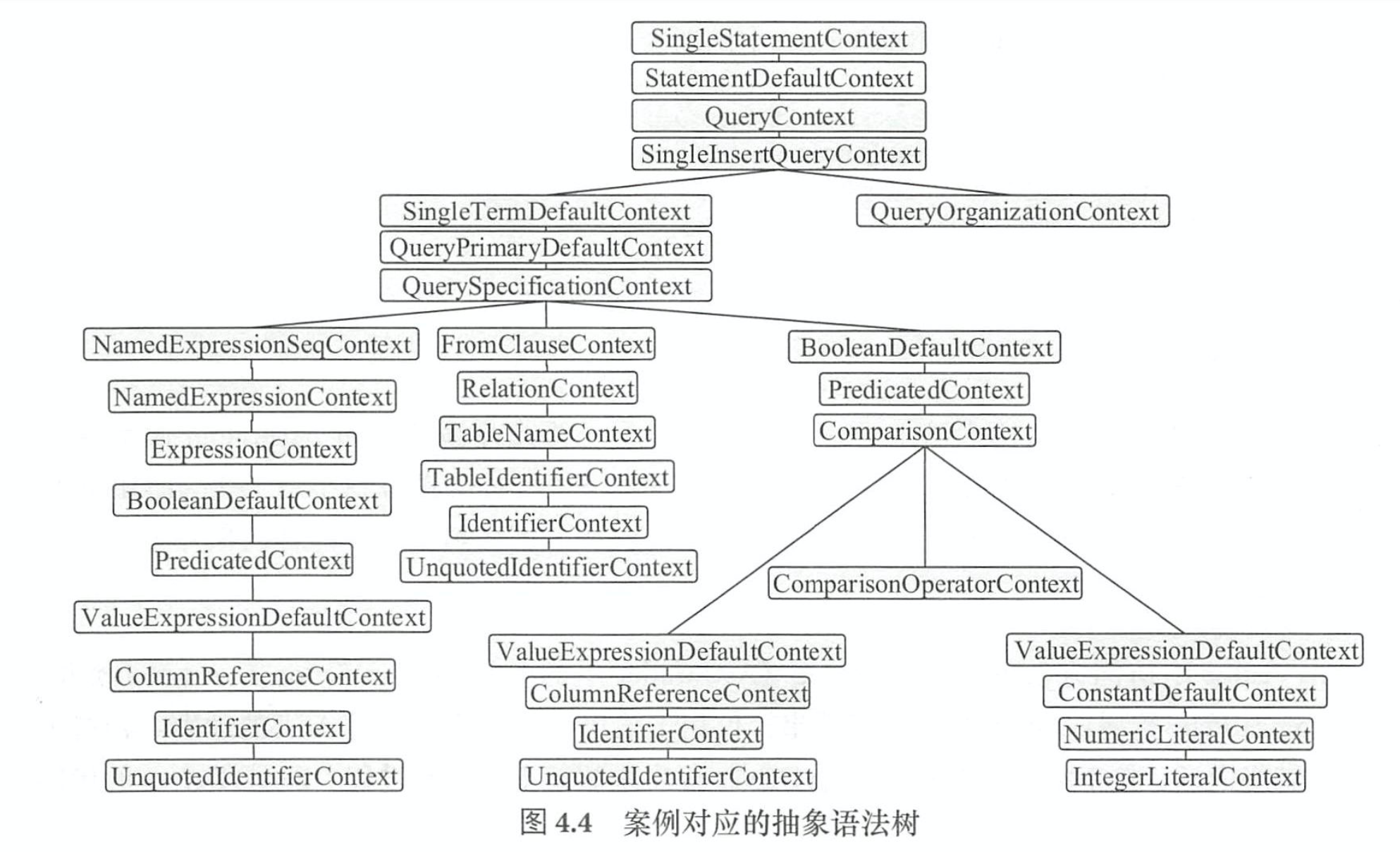
5.1 Spark SQL 逻辑计划
Spark SQL 逻辑计划在实现层面被定义为 LogicalPlan 类 。 从 SQL 语句经过 SparkSqlParser 解析生成 Unresolved LogicalPlan,到最终优化成为 Optimized LogicalPlan,这个流程主要经过 3 个阶段,如图 5.1 所示 。 这 3 个阶段分别产生 Unresolved Logica!Plan, Analyzed LogicalPlan 和 Optimized LogicalPlan,其中 OptimizedLogicalPlan传递到下一个阶段用于物理执行计划的生戚。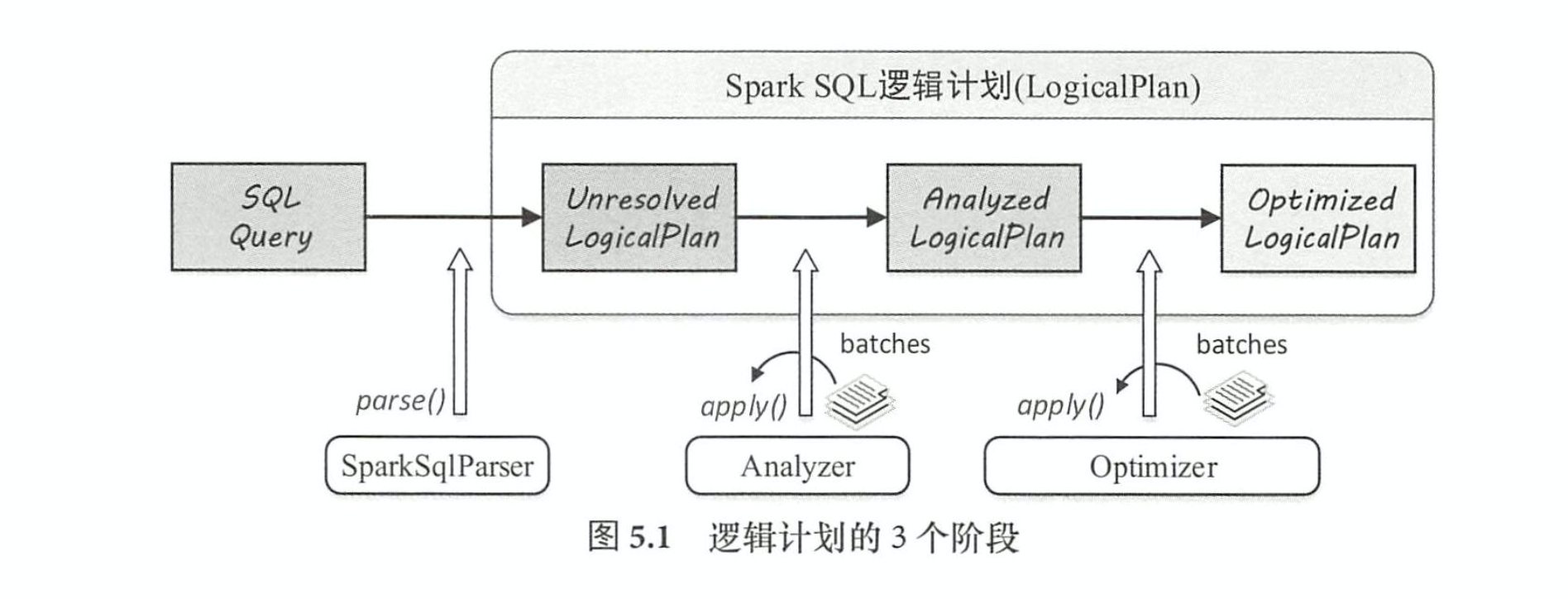
具体来讲,这 3 个阶段所完成的工作分别如下 。
(1)由 SparkSq!Parser 中的 AstBuilder执行节点访问,将语法树的各利I Context节点转换成
对应的 LogicalPlan 节点,从而成为 一棵未解析的逻辑算子树( Unresolved LogicalPlan),此时的
逻辑算子树是最初形态,不包含数据信息与列信息等。
(2)由 Analyzer将一系列的规则作用在 Unresolved LogicalPlan 上,对树上的节点绑定各种
数据信息,生成解析后的逻辑算子树( Analyzed LogicalPlan)。
(3)由 SparkSQL中的优化器(Optimizer)将一系列优化规则作用到上一步生成的逻辑算
子树中,在确保结果正确的前提下改写其中的低效结构,生成优化后的逻辑算子树( Optimized
Logica!Plan) 。
本章首先在 5.2 节全面介绍 Logica!Plan 所涉及的方方面面的基础知识,包括 LogicalPlan 分
类和各种操作的概述;然后,在 5.3~5.5节分别讲解 3个阶段的执行过程;最后,在 5.6节对全 章内容进行总结 。
5.2.1 QueryPlan 概述
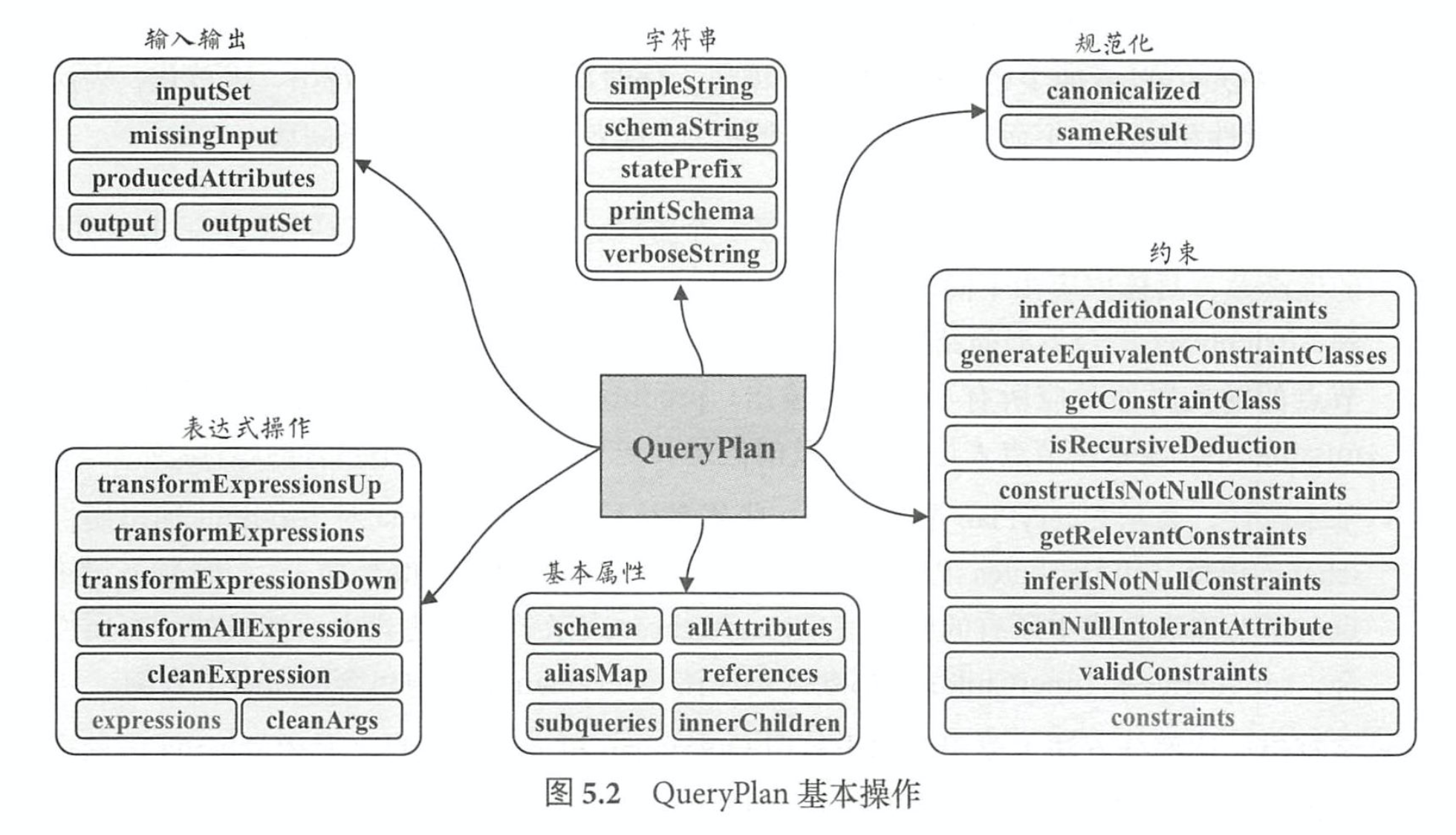
QueryPlan的主要操作分为6个模块,分别是输入输出、 字符串、 规范化、表达式 操作、基本属性和约束。
- 输入输出: QueryPlan 的输入输出定义了 5 个方法,其中 output 是返 回值为 Seq[Attribute] 的虚函数,具体内容由不同子节点实现,而 outputSet 是将 output 的返回值进行封装,得 到 AttributeSet集合类型的结果 。 获取输入属性的方法 inputSet 的返回值也是 AttributeSet, 节点的输入属性对应所有子节点的输出; producedAttributes 表示该节点 所产生的属性; missinglnput表示该节点表达式中涉及的但是其子节点输出中并不包含的属性 。
- 基本属性:表示 QueryPlan节点中的一些基本信息,其中 schema对应 output输出属性的 schema信息, allAttributes记录节点所涉及的所有属性( A忧ribute)列表, aliasMap 记录节 点与子节点表达式中所有的别名信息, references 表示节点表达式中所涉及的所有属性集 合, subqueries 和 innerChildren 都默认实现该 QueryPlan 节点中包含的所有子查询 。
- 字符串:这部分方法主要用于输出打印 QueryPlan树型结构信息,其中 schema信息也会 以树状展示。 需要注意的一个方法是 statePre缸,用来表示节点对应计划状态的前缀字符
串。 在 QueryPlan 的默认实现中,如果该计划不可用 (invalid),则前缀会用感叹号(“!”)
标记。 - 规范化: 类似 Expression 中的 方法定义,对 QueryPlan 节点类型也有规范化( Canonicalize) 的概念。 在 QueryPlan 的默认实现中, canonicalized直接贼值为当前的 QueryPlan类;此 外,在 sameResult 方法中会利用 canonicalized 来判断两个 QueryPlan 的输出数据是否相同 。
- 表达式操作:在第 3 章中已经介绍过 Spark SQL 丰富的表达式体系,其典型的特点就是不 需要驱动,直接执行 。 而在 QueryPlan 各个节点中,包含了各种表达式对象,各种逻辑操 作一般也都是通过表达式来执行的。 在QueryPlan的方法定义中,表达式相关的操作占据 重要的地位,其中 expressions方法能够得到该节点中的所有表达式列表,其他方法很容易 根据命名了解对应功能,具体的实现细节可以参看代码 。
- 约束(Constraints):本质上也属于数据过滤条件(F过ter)的一种,同样是表达式类型。 相 对于显式的过滤条件,约束信息可以“推导”出来,例如,对于“ a > S”这样的过滤条件, 显然 a 的属性不能为 null,这样就可以对应地构造 isNotNull (a)约束;又如“ a=S”和 “a=b”的谓词,能够推导得到“b=S”的约束条件。在实际情况下, SQL语句中可能会 涉及很复杂的约束条件处理,如约束合并、 等价性判断等。 在QueryPlan类中,提供了大 量方法用于辅助生成 constraints表达式集合以支持后续优化操作 。 例如, validConstraints 方法返回该 QueryPlan 所有可用的约束条件,比较常用的 constructlsNotNullConstraints 方 法,会针对特定的列构造 isNotNull 的约束条件 。
5.4.1 Catalog 体系分析
按照 SQL 标准的解释,在 SQL 环境下 Catalog 和 Schema 都属于抽象概念 。 在关系数据库 中, Catalog是一个宽泛的概念,通常可以理解为一个容器或数据库对象命名空间中的一个层次,主要用来解决命名冲突等问题 。
在 SparkSQL 系统中, Catalog主要用于各种函数资源信息和元数据信息(数据库、数据表、
数据视图、数据分区与函数等)的统一管理。 SparkSQL 的 Catalog体系涉及多个方面,不同层 次所对应的关系如图 5.11 所示 。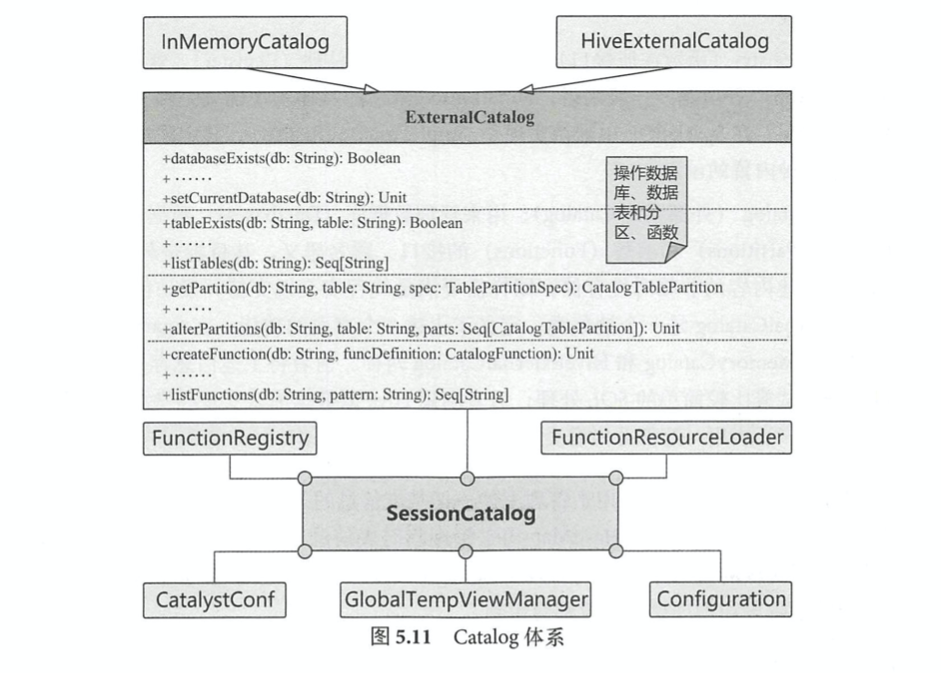
5.4.2 Rule 体系
在 Unresolved LogicalPlan 逻辑算子树的操作(如绑定、解析、优化 等 )中,主要方法都是 基于规则( Rule)的,通过 Scala语言模式匹配机制( Pattern-match)进行树结构的转换或节点 改写 。 Rule是一个抽象类,子类需要复写 apply(plan: TreeType)方法来制定特定的处理逻辑,基 本定义如下 。
6.1 Spark SQL 物理计划
在 SparkSQL 中,物理计划用 SparkPlan表示,从 OptimizedLogicalPlan传入到 SparkSQL物理 计划提交并执行,主要经过 3个阶段。 如图 6.1 所示,这 3个阶段分别产生 Iterator[PhysicalPlan]、 SparkPlan 和 Prepared SparkPlan,其中 Prepared SparkPlan 可以直接提交并执行(注:这里的 “PhysicalPlan”和“ SparkPlan”均表示物理计划) 。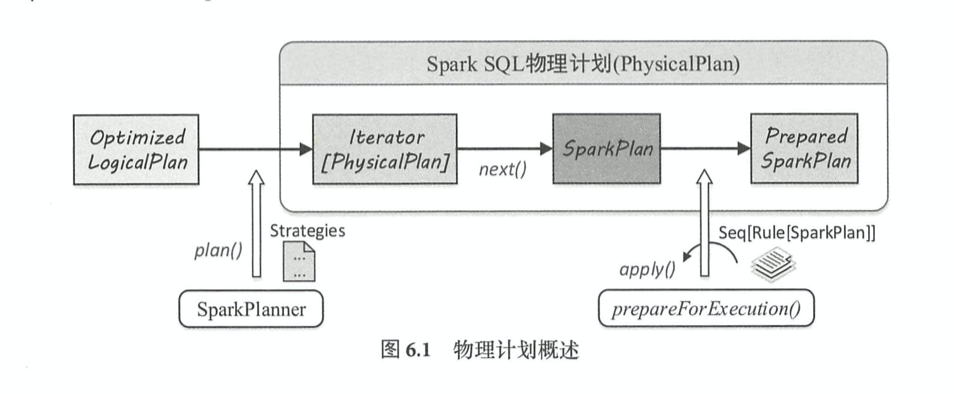
spark sql物理执行计划操作
- Project进行列剪裁
- Filter 行过滤
- Exchange 负责对数据进行重分区,
- SampleExec 对输入 RDD 中的数据进行采样,
- SortExec按照一 定条件对输入 RDD 中数据进行排序,
- WholeStageCodegenExec 类型的 SparkPlan 将生成的代码 整合成单个 Java 函数 。
聚合过程 partial & final
Final模式一般和 Partial模式组合在一起使用 。 Partial模式可以看作是局部数据的聚合,在 具体实现中, Partial 模式的聚合函数在执行时会根据读入的原始数据更新对应的聚合缓冲区, 当处理完所有的输入数据后,返回的是聚合缓冲区中的中间数据 。 而 Final模式所起到的作用 是将聚合缓冲区的数据进行合并,然后返回最终的结果 。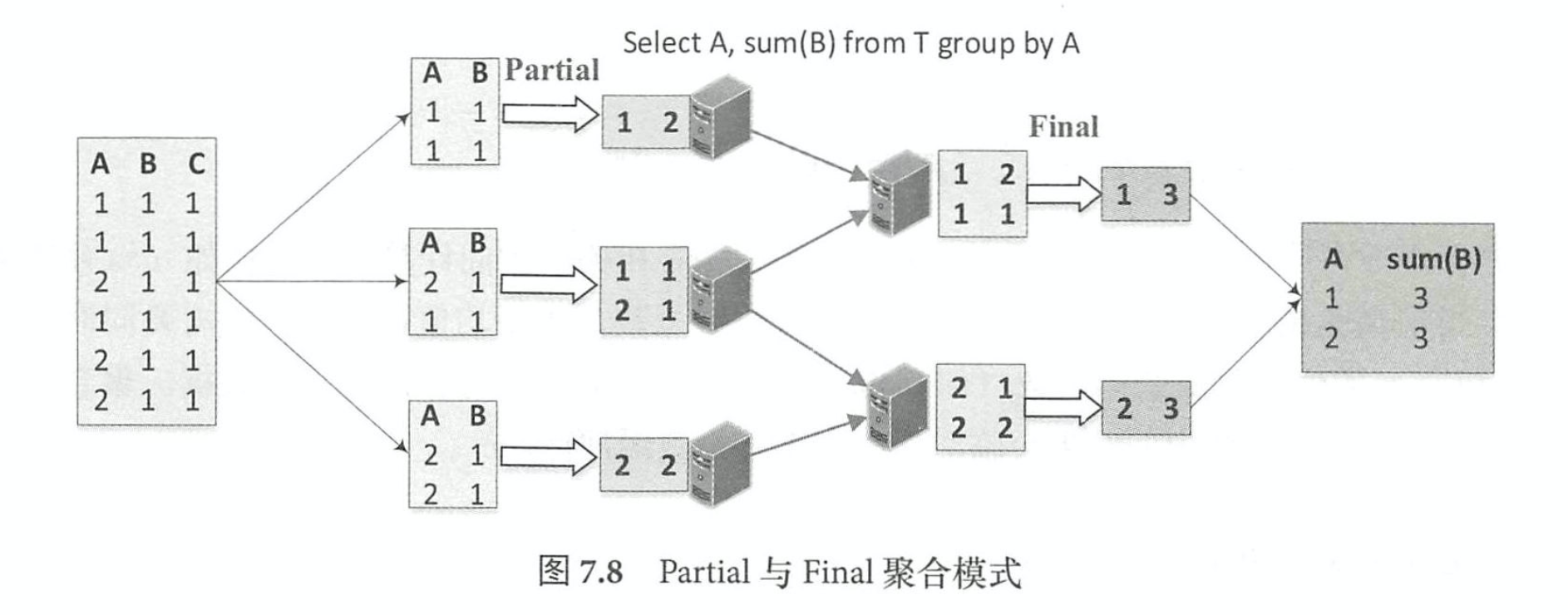
Complete
Complete模式和上述的 Partial/Final组合方式不一样,不进行局部聚合计算,一般来讲, Complete模式应用在不支持Partial模式的聚合函数中。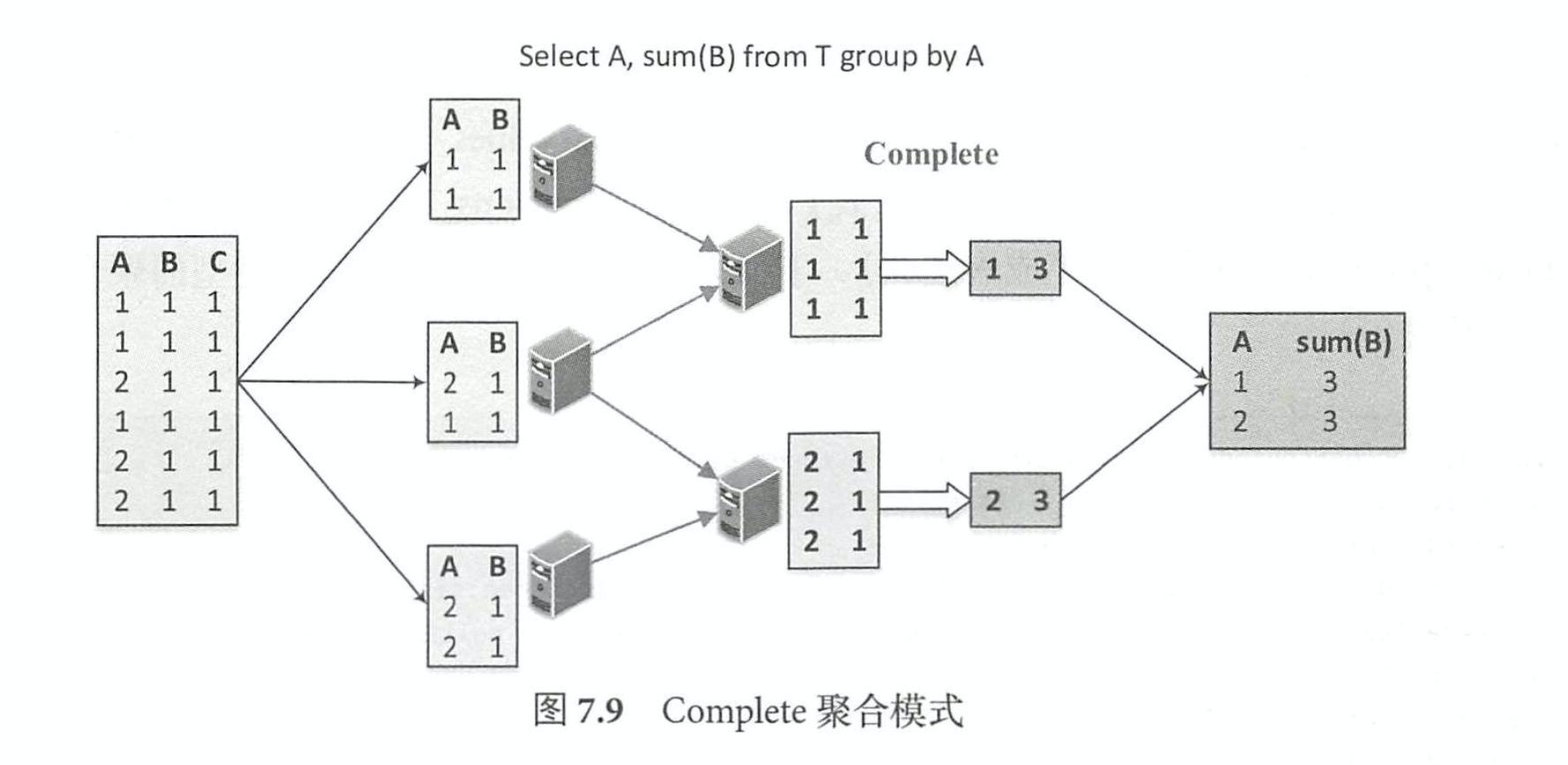
聚合函数计算过程 – 包含distinct
相比 Partial、 Final和 Complete模式, PartialMerge模式的聚合函数主要是对聚合缓冲区进 行合并,但此时仍然不是最终的结果。 ParitialMerge主要应用在 distinct语句中,如图 7.10所示。 聚合语句针对同一张表进行 sum 和 count (distinct)查询,最终的执行过程包含了 4 步聚合操 作。 第 l步按照(A,C)分组,对 sum函数进行 Partial模式聚合计算;第 2步是 PartialMerge模 式,对上一步计算之后的聚合缓冲区进行合井,但此时仍然不是最终的结果;第 3步分组的列 发生变化,再一次进行 Partial模式的 count计算;第 4步完成 Final模式的最终计算 。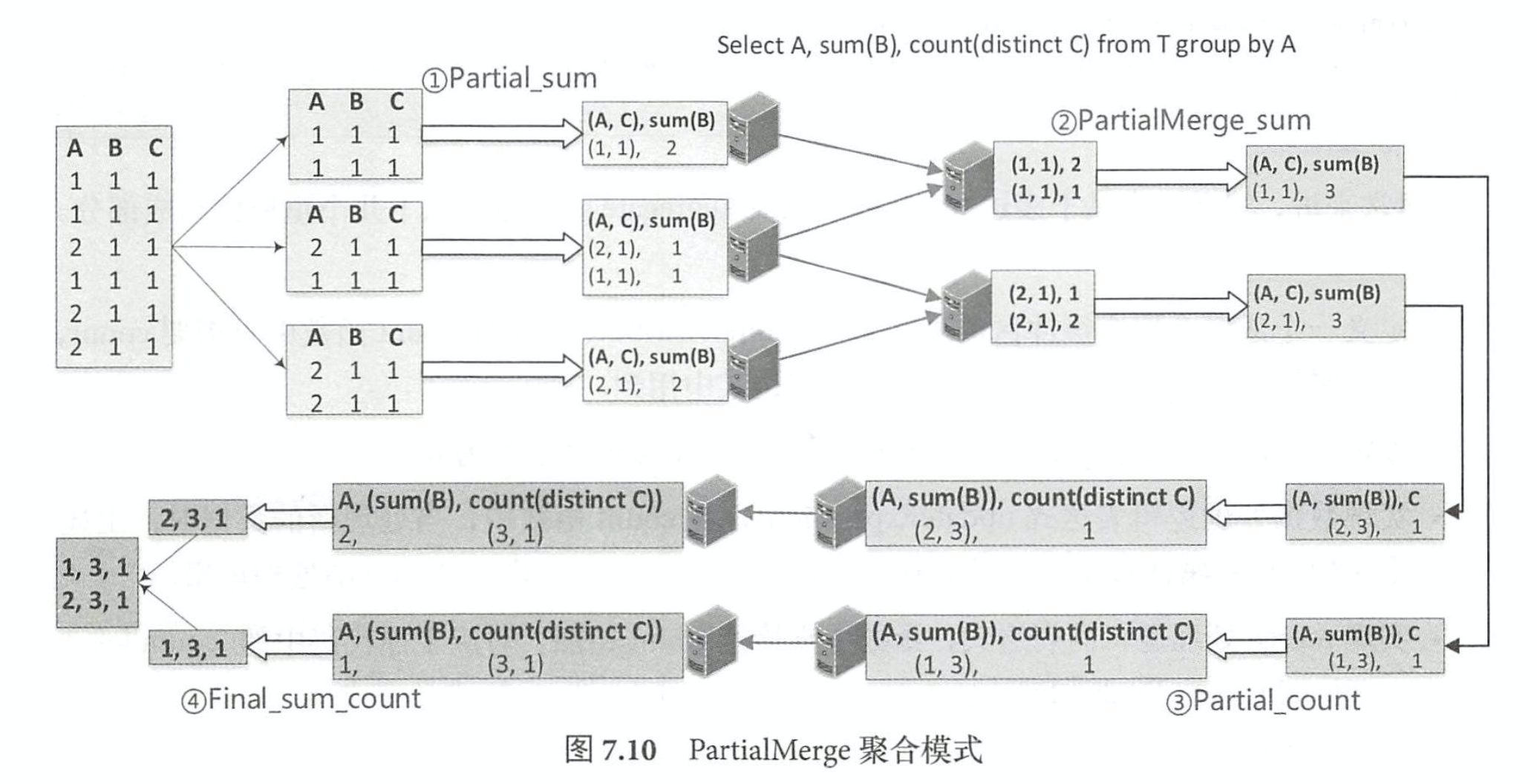
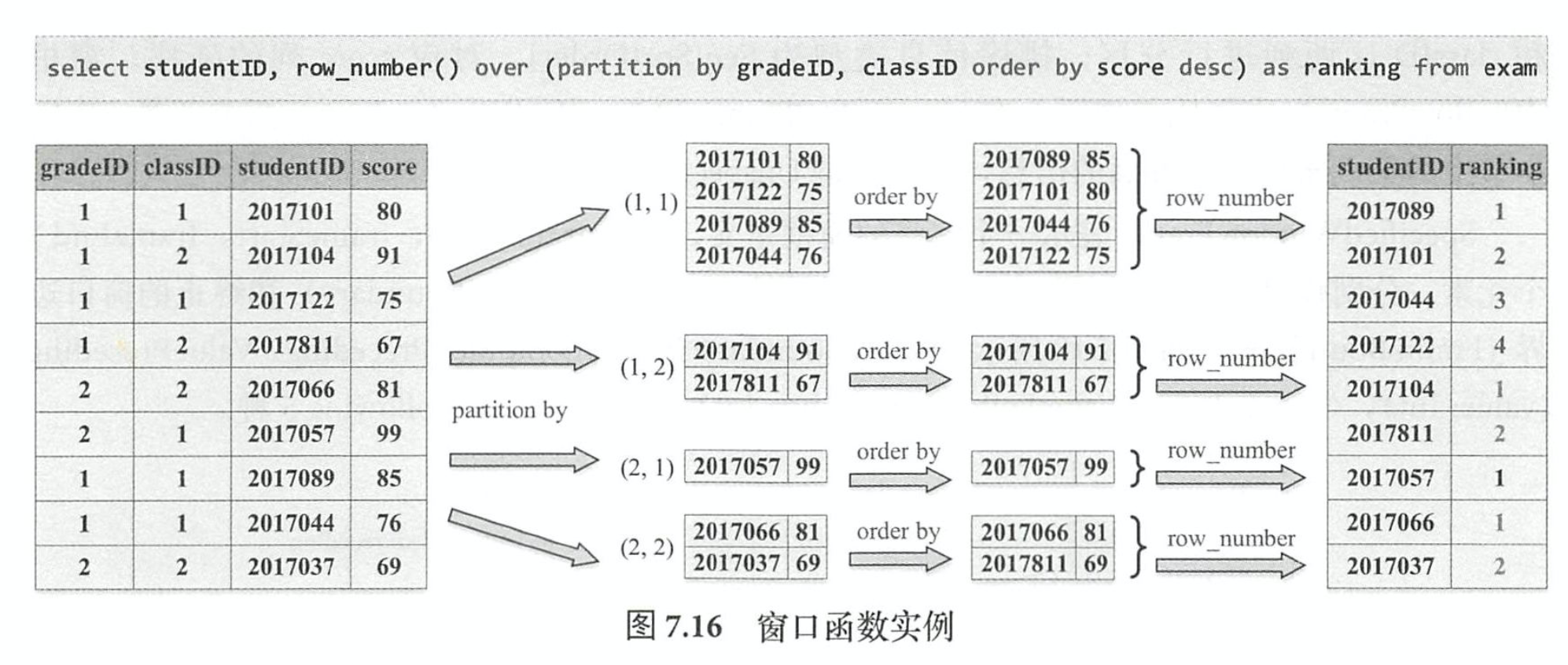
窗口函数