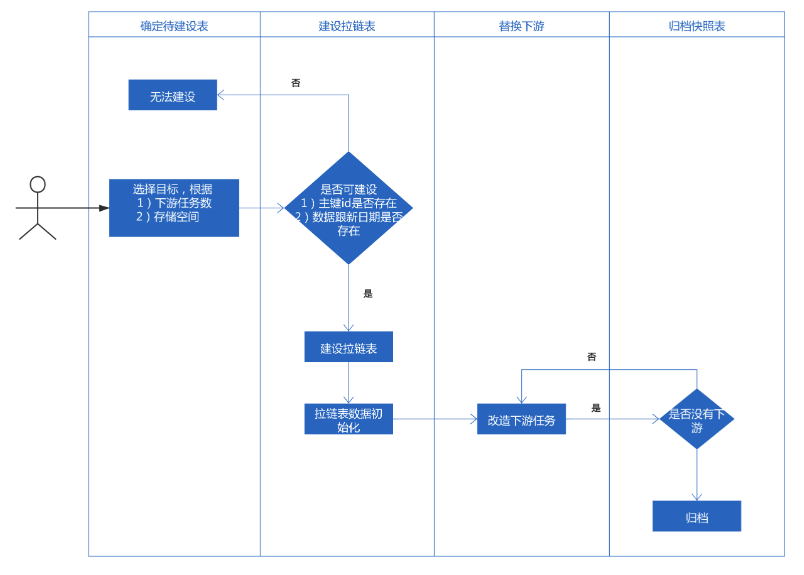
日级别拉链表存储方案
背景
当前数仓表的生命周期策略数据生命周期管理规范,除个别表外,无条件对所有表采用93天快照策略,数据重复存储,造成存储压力大。
现状:共xxx张表,占用xxx张空间,平均每张xxx存储。
基于合理利用存储,控制存储无序扩展,节约公司存储成本,需要该表快照策略,由快照策略改为拉链策略。
说明
本方案所说拉链,指的是替换快照方式日粒度的存储拉链,有别于基于业务流水数据设计的拉链。
方案比较
快照vs拉链
简洁版
| 比较项 | 快照 | 拉链 |
|---|---|---|
| 写入 | 无需加工 | 需要加工 |
| 使用 | 无成本 | 理解成本高 |
| 存储 | 126份副本 | 2~5份副本 |
| 计算 | 无 | 去重&排序 |
| 适用 | 所有 | 有主键&数据变更时间 |
明细版
| 比较项 | 快照 | 拉链 |
|---|---|---|
| 写入 | 快照直接按数据日期写入,简单易懂 | 拉链需要结合当天最新数据和历史拉链数据加工出最新数据,略微复杂 |
| 使用 | 快照关联历史直接按数据日期取多版本,简单易懂 | 拉链需要根据业务日期和开始时间及结束时间比较,确定唯一版本,使用成本高 |
| 存储 | 快照为93天周期+每月最后一天,以3年为例,共计126份副本 | 拉链只有在数据变更才会重复存储,根据数据量变更频繁程度,预估2~5份副本 |
| 计算 | 无计算 | 需要根据id和创建时间和结束时间进行去重和排序,进而计算出开始时间和结束时间 |
| 适用 | 所有 | 需要有主键&数据变更时间 |
总结
快照方案简单粗暴有效,拉链方案复杂优雅有效。
加工和使用成本上,可以认为拉链是快照方案的2~5倍
存储成本上,可以任务拉链是快照方案的 1/30 之一
前提条件
并非所有的表都可以做成拉链表来存储历史记录,业务表必须满足一下几点方可设计拉链
| 条件 | 解释 | 现状 |
|---|---|---|
| 有唯一主键id | 业务库必须有唯一主键id用于标识同一条记录 这样才能对同一条记录进行版本区分 |
开发规范里有明确必须有主键id 不排除个别表 |
| 有业务数据变更时间 | 如果数据字段发生变更,然而数据时间不进行变更会导致拉链表无法确认时间 | 开发规范里有明确edit_time需要自动更新 历史老表存在不更新现象,需要在mysql表结构中确认是否自动更新 |
设计
统一规范
1)无穷大的结束时间,统一采用 29991231 表示
2)无穷小的开始时间,统一采用 20000101表示
3)拉链表统一新增三个字段
之所以加上data前置,为了防止字段重名
| 字段名 | 解释 |
|---|---|
| data_start_date | 数据生效开始日期 |
| data_end_date | 数据生效结束日期 |
| data_is_active | 数据是否当前有效 |
| 4)拉链表分区统一使用三个字段进行分区 | |
| 其中data_start_year和data_end_year是为了加快使用效率 | |
| dayid是为了获取昨天版本 | |
| 字段名 | 解释 |
| ———– | ———– |
| data_start_year | 数据开始年份 |
| data_end_year | 数据结束年份 |
| dayid | 数据日期 |
5)data_start_date和data_end_date采用闭区间设计
6)拉链表的生命周期为2,即保留两份副本
7) 命名统一采用 xxx_fds命名
8)当前拉链表只针对dwd进行设计
设计举例
mysql 举例表结构
表名:test_a
| 字段 | 解释 | 其他 |
|---|---|---|
| id | 主键id | pk |
| test_name | 测试名称 | |
| create_time | 创建时间 | |
| edit_time | 编辑时间 |
mysql 举例表数据
20210701数据
| 日期 | id | test_name | create_time | edit_time |
|---|---|---|---|---|
| 20210701 | 1 | what’s your name | 20210701 | 20210701 |
| 20210701 | 2 | what’s your age | 20210701 | 20210701 |
| 2021072 | 1 | what’s wrong | 20210701 | 20210702 |
| 20210702 | 2 | what’s your age | 20210701 | 20210701 |
| 20210710 | 1 | whattttttttttt | 20210701 | 20210710 |
| 20210710 | 2 | what’s your age | 20210701 | 20210701 |
拉链表代码
1 | set hive.exec.dynamic.partition=true; |
拉链表数据效果
|数据日期| data_start_date| data_end_date| data_is_active| id| test_name| create_time| edit_time| data_start_year| data_end_year|
|—–| —–| —–| —–| —–| —–| —–| —–| —–| —–|
|20210701| 20210701| 29991231| 1| 1| what’s your name| 20210701| 20210701| 2021| 2999|
|20210701|20210701 |29991231 |1 |2 |what’s your age| 20210701| 20210701| 2021| 2999|
|20210702| 20210701| 20210701| 0| 1| what’s your name| 20210701| 20210701| 2021| 2021|
|20210702|20210702| 29991231| 1| 1| what’s wrong| 20210701| 20210702| 2021| 2999|
|20210702|20210701| 29991231| 1| 2| what’s your age| 20210701| 20210701| 2021| 2999|
|20210710| 20210701| 20210701| 0| 1| what’s your name| 20210701| 20210701| 2021| 2021|
|20210710|20210702| 20210709| 0| 1| what’s wrong| 20210701| 20210702| 2021| 2021|
|20210710|20210710| 29991231| 1| 1| whattttttttttt| 20210701| 20210710 |2021| 2999|
|20210710|20210701 |29991231 |1| 2| what’s your age| 20210701| 20210701| 2021| 2999|
拉链表的使用
获取当前最新数据
1)优先使用最新表而非快照表
2)一定要用快照: sql select * from dwd_test_a_fds where dayid='cur_time' and data_is_active=1
获取某一天的状态
1 | select * from dwd_test_a_fds |
根据业务字段字段进行匹配
1 | select a.* |
效果
待测试,暂定dwd_order_shop_full_d 表
流程