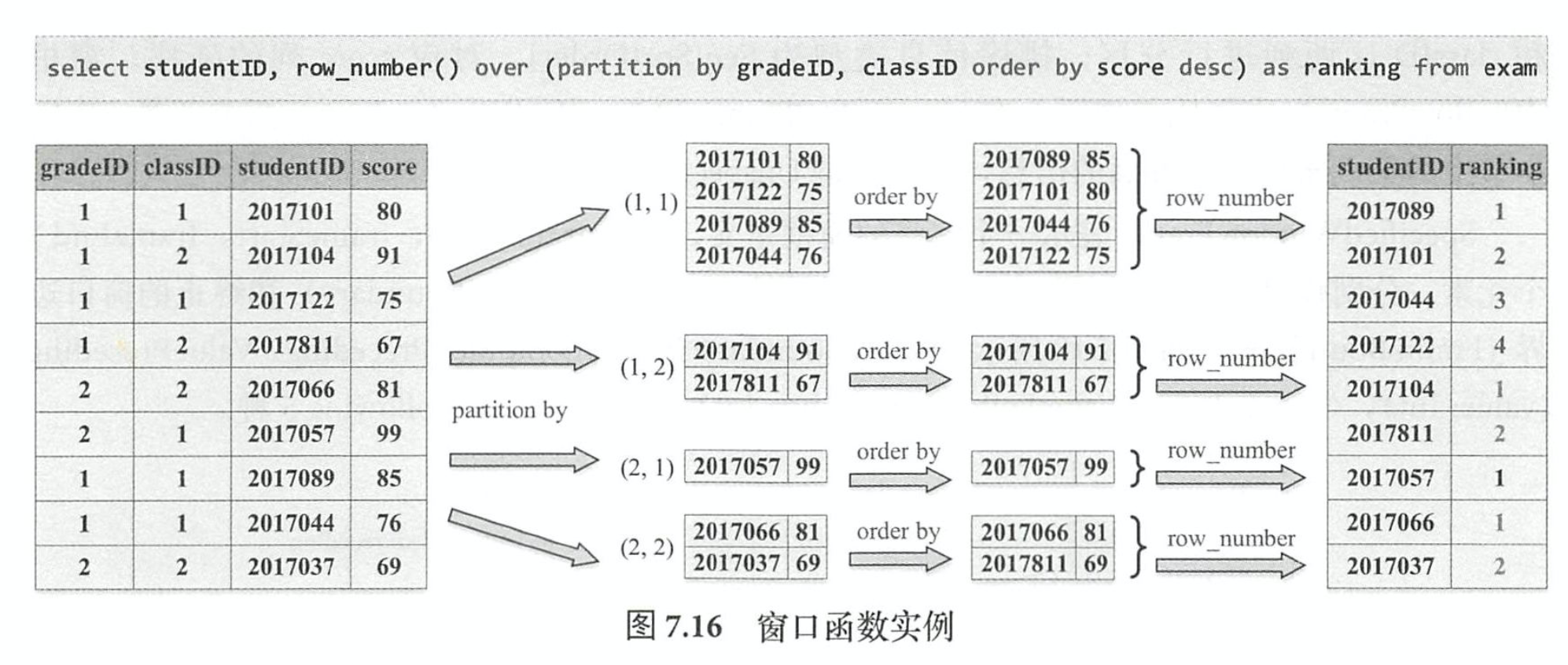
linux cpu 指令集架构 RISC / CISC | arm | amd | X86/i386 | aarch64
问题
在下载软件包时,linux软件包经常会有
- linux_386.tar.gz
- linux_amd64.tar.gz
- linux_arm.tar.gz
- linux_arm64.tar.gz
- linux_mips.tar.gz
- linux_mips64.tar.gz
- linux_mips64le.tar.gz
- linux_mipsle.tar.gz
- linux_riscv64.tar.gz
等选项,作为硬件一窍不通的人了,看了这么多选项两眼发黑,到底选哪个版本才是符合自己服务器的呢?
基础知识
在了解上面选项之前,我们需要先了解下 CISC 和 RISC ,这是所有分类的前置分类。
指令集架构
每一种处理器都有自己可以识别的一整套指令,称为 【指令集】。
处理器执行指令时,根据不同的指令采取不同的动作,完成不同的功能,既可以改变自己内部的工作状态,也能控制其它外围电路的工作状态。
处理器 【指令集】 只是定义了硬件与软件(含OS)之间的接口、标准规范,而不定义处理器的实现
一台计算机上全部指令的集合,就是这台计算机的 指令系统 。
指令系统 也称 指令集,是这台计算机全部功能的体现。
而人们设计计算机首要考虑的是它拥有的功能,也就是首先要按功能档次设计指令集;然后,按指令集的要求在硬件上实现。
指令系统 不仅仅是指令的集合,还包括全部指令的指令格式、寻址方式和数据形式。
CISC
CISC(Complex Instruction Set Computer, 复杂指令系统计算机),除了RISC,任何全指令集计算机都使用的是复杂指令集计算(CISC)。
常见使用CISC的处理器主要有X86.
从计算机诞生以来,人们一直沿用CISC指令集方式。
早期的桌面软件是按CISC设计的,并一直沿续到现在。目前,桌面计算机流行的x86体系结构即使用CISC。
微处理器(CPU)厂商一直在走CISC的发展道路,包括Intel、AMD,还有其他一些现在已经更名的厂商,如TI(德州仪器)、IBM以及VIA(威盛)等。
在CISC微处理器中,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
顺序执行的优点是控制简单,但计算机各部分的利用率不高,执行速度慢。
CISC架构的服务器主要以IA-32架构(Intel Architecture,英特尔架构)为主,而且多数为中低档服务器所采用。
RISC
RISC(reduced instruction set computer,精简指令集计算机)是一种执行较少类型计算机指令的微处理器。
纽约约克镇IBM研究中心的John Cocke证明,计算机中约20%的指令承担了80%的工作,他于1974年提出了RISC的概念。
目前常见使用RISC的处理器包括DEC Alpha、ARC、ARM、MIPS、PowerPC、SPARC和SuperH等。
RISC是一种执行较少类型计算机指令的微处理器,起源于80年代的MIPS主机(即RISC机),RISC机中采用的微处理器统称RISC处理器。
这样一来,它能够以更快的速度执行操作(每秒执行更多百万条指令,即MIPS)。因为计算机执行每个指令类型都需要额外的晶体管和电路元件,计算机指令集越大就会使微处理器更复杂,执行操作也会更慢。
CISC 指令集有哪些?
| 指令集架构 | 发源于(时间、干系人) | 具体示例 | 微处理器 |
|---|---|---|---|
| X86 指令集(架构) | 创始者: Intel公司 | X86-32 / X86-64(即 AMD64 / Intel64) | 1. Intel i8086 CPU处理器(首台X86 CPU) 2. VIA CPU处理器 3. Intel Core I3/I5/I7/I9 CPU处理器 4. AMD CPU处理器 |
RISC 指令集 有哪些?
| 指令集架构 | 发源于(时间、干系人) | 具体示例 | 微处理器 |
|---|---|---|---|
| MIPS(Million Instructions Per Second) 指令集架构 | 1.创立于1998年; 2.创始者: 斯坦福大学教授John LeRoy Hennessy(RISC架构的开拓者) |
MIPS I/II/III/IV/V/16/32/64 | 龙芯芯片 |
| ARM(Acorn/Advanced RISC Machine) 指令集架构 | 1. 创立于1985年; 2. 创始者:Acorn公司、加州大学伯克利分校Sophie Wilson(指令集开发)和Steve Furber(芯片设计)2位教授(2家单位合作推出ARM1芯片,以此作为其未来个人计算机的中枢) |
ARMv7a架构: ARM Cortex A8/A9 ARMv7M架构:ARM Cortex A3/A4 ARMv8架构(支持32+64位架构):ARM Cortex A32/35/53/57/72/73/77/78 |
1. 高通骁龙Qualcomm 810处理器 2.海思麒麟950处理器 3. 三星Exynos 4412处理器 4.Apple A系列处理器、Apple A6/A6X CPU处理器(基于Apple Swift 微架构[ARM指令集扩展的微架构]) |
| AArch64/ARM64(ARMv8A架构的2种执行状态/执行模式之一,64位指令集架构) | 1. 概念于2011年在美国加州圣克拉拉的一场技术大会“ARM TechCon 2011”的ARM公司院士、首席架构师Richard Grisenthwaite发布 | .. | .. |
| AArch32 指令集(ARMv8A架构的2种执行状态/执行模式之一,64位指令集架构) | 同上 | 同上 | 同上 |
| Power PC(Performance Optimization With Enhanced RISC – Performance Computing, 简称:PPC) 指令集 | 1.POWER是1991年,Apple、IBM、Motorola组成的AIM联盟所发展出的微处理器架构; 2.PowerPC是整个AIM联盟平台的一部分,并且是到目前为止唯一的一部分; 3.但苹果电脑自2005年起,将旗下电脑产品转用Intel CPU; 4.该设计是从早期的RISC架构(比如IBM 801)与MIPS架构的处理器得到灵感的 |
(略) | 任天堂Gamecube、MPC505/821/850/860/8240/8245/8260/8560 |
| SPARC(Scalable Processor Architecture可伸缩的处理器架构) 指令集 | 1987年,SUN公司与TI合作的成果 | (略) | ERC 32(机构: 欧洲航天航空局) |
| RISC-V / RISC-FIVE 指令集(Reduced Instruction Set Computer-V, 第5代精简指令集计算机) | 1.创始者: Keste Asanovic教授(RISC-V基金会主席)、David Pattern教授(《量化分析》作者、RISC-V概念的提出者、Turing奖获得者)、Andrew Waterman(SiFive首席工程师、Rocket处理器作者)、Yunsup Lee(SiFive的CTO、Rocket处理器作者) 2.源于2010年,当时加州大学伯克利分校(UC Berkeley)一研究团队要设计一款CPU,为该项目选架构的时候研究团队对比了当时的ARM、MIPS、SPARC和X86等,发现:不仅这些【指令集越来越复杂】,还有很多【IP法律】问题,再加上【X86授权难以获取】,【ARM授权价格昂贵】,所以该研究团队最终决定设计一套全新的指令集。 2.于是,成立了一个四人小组,仅用了3个月的时间就完成了RISC-V指令集的开发。 3.其【目标】是:新的指令集能满足从微控制器到超级计算机等各种尺寸的处理器 |
略 |
如何确认下载哪个版本?
了解了上文的知识,直接在linux中查看指令集架构即可
arch命令查看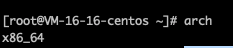
file /lib/systemd/systemd查看
可以看到,笔者的服务器为x86架构,那么对应到上文的选项,应该选择 linux_amd64.tar.gz 下载。