web自动化测试【转载】
参考文章 Web自动化测试
参考文章 Web自动化测试
KMP(Knuth-Morris-Pratt)算法是一种字符串匹配算法,可以在 O(n+m) 的时间复杂度内实现两个字符串的匹配。
所谓字符串匹配,是这样一种问题:“字符串 P 是否为字符串 S 的子串?如果是,它出现在 S 的哪些位置?” 其中 S 称为主串;P 称为模式串。下面的图片展示了一个例子。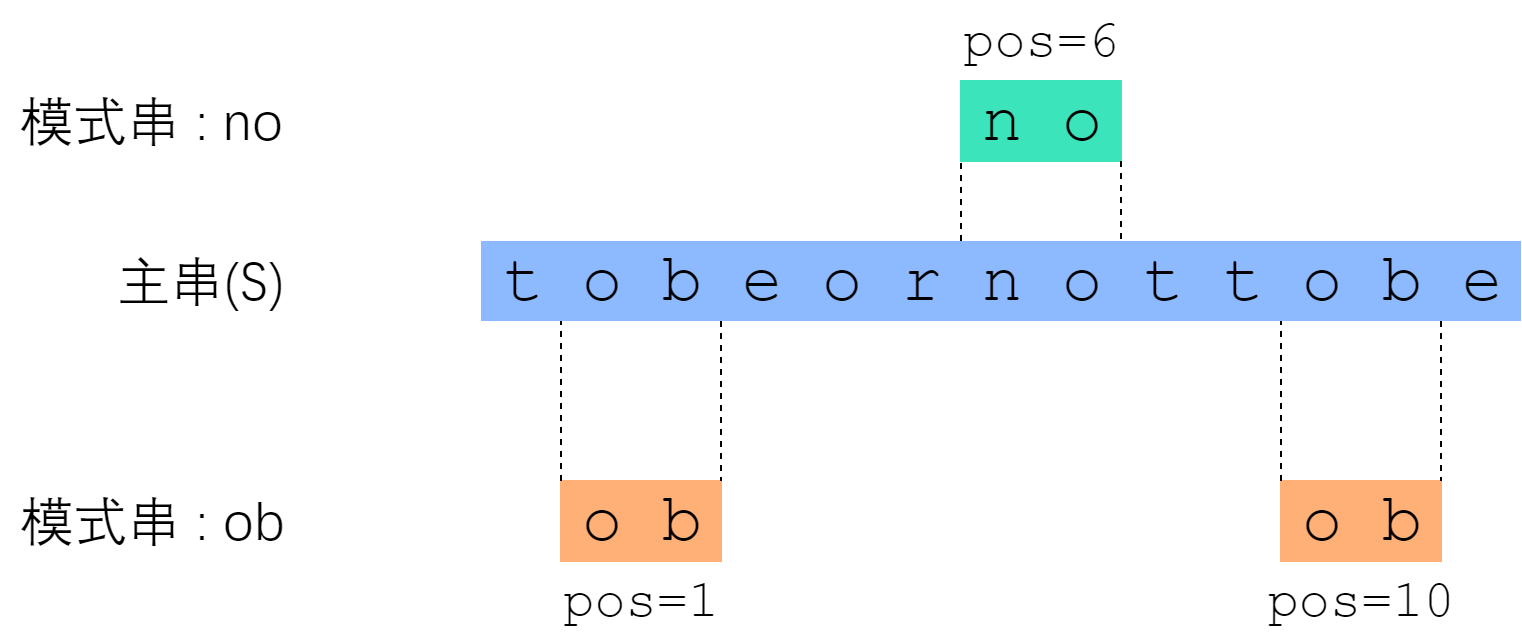
主串是莎翁那句著名的 “to be or not to be”,这里删去了空格。“no” 这个模式串的匹配结果是“出现了一次,从$S[6]$开始”;“ob”这个模式串的匹配结果是“出现了两次,分别从$S[1]$、$S[10]$开始”。按惯例,主串和模式串都以0开始编号。 字符串匹配是一个非常频繁的任务。例如,今有一份名单,你急切地想知道自己在不在名单上;又如,假设你拿到了一份文献,你希望快速地找到某个关键字(keyword)所在的章节……凡此种种,不胜枚举。 我们先从最朴素的Brute-Force算法开始讲起。
顾名思义,Brute-Force是一个纯暴力算法。说句题外话,我怀疑,“暴力”一词在算法领域表示“穷举、极低效率的实现”,可能就是源于这个英文词。
首先,我们应该如何实现两个字符串 A,B 的比较?所谓字符串比较,就是问“两个字符串是否相等”。最朴素的思想,就是从前往后逐字符比较,一旦遇到不相同的字符,就返回False;如果两个字符串都结束了,仍然没有出现不对应的字符,则返回True。实现如下:
既然我们可以知道“两个字符串是否相等”,那么最朴素的字符串匹配算法 Brute-Force 就呼之欲出了——
现在我们来模拟 Brute-Force 算法,对主串 “AAAAAABC” 和模式串 “AAAB” 做匹配: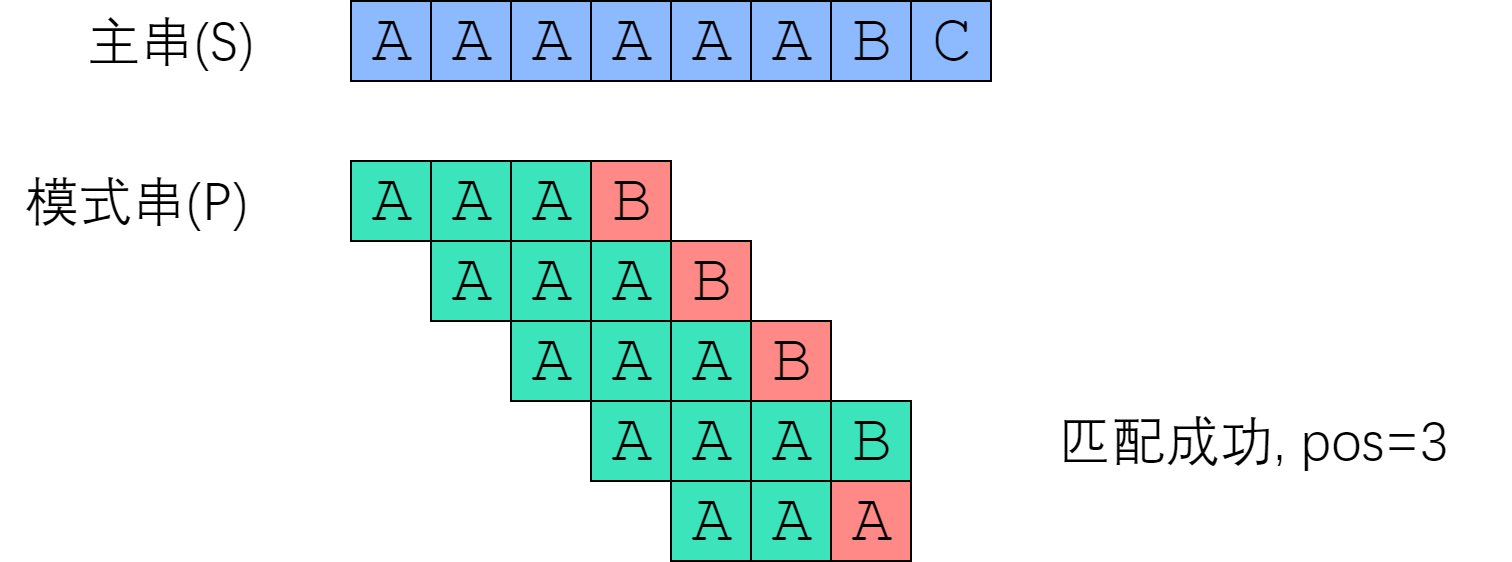
这是一个清晰明了的算法,实现也极其简单。下面给出Python和C++的实现:


我们成功实现了 Brute-Force 算法。现在,我们需要对它的时间复杂度做一点讨论。按照惯例,记 $n = |S|$ 为串 S 的长度,$m = |P|$ 为串 P 的长度。
考虑“字符串比较”这个小任务的复杂度。最坏情况发生在:两个字符串唯一的差别在最后一个字符。这种情况下,字符串比较必须走完整个字符串,才能给出结果,因此复杂度是 $O(len)$ 的。
由此,不难想到 Brute-Force 算法所面对的最坏情况:主串形如“AAAAAAAAAAA…B”,而模式串形如“AAAAA…B”。每次字符串比较都需要付出 $|P|$ 次字符比较的代价,总共需要比较 $|S| - |P| + 1$次,因此总时间复杂度是 $O(|P|⋅(|S|−|P|+1))O(|P|\cdot (|S| - |P| + 1) )O(|P|\cdot (|S| - |P| + 1) )$ . 考虑到主串一般比模式串长很多,故 Brute-Force 的复杂度是 $O(|P|⋅|S|)O(|P| \cdot |S|)O(|P| \cdot |S|)$ ,也就是 $O(nm)的$。这太慢了!
经过刚刚的分析,您已经看到,Brute-Force 慢得像爬一样。它最坏的情况如下图所示: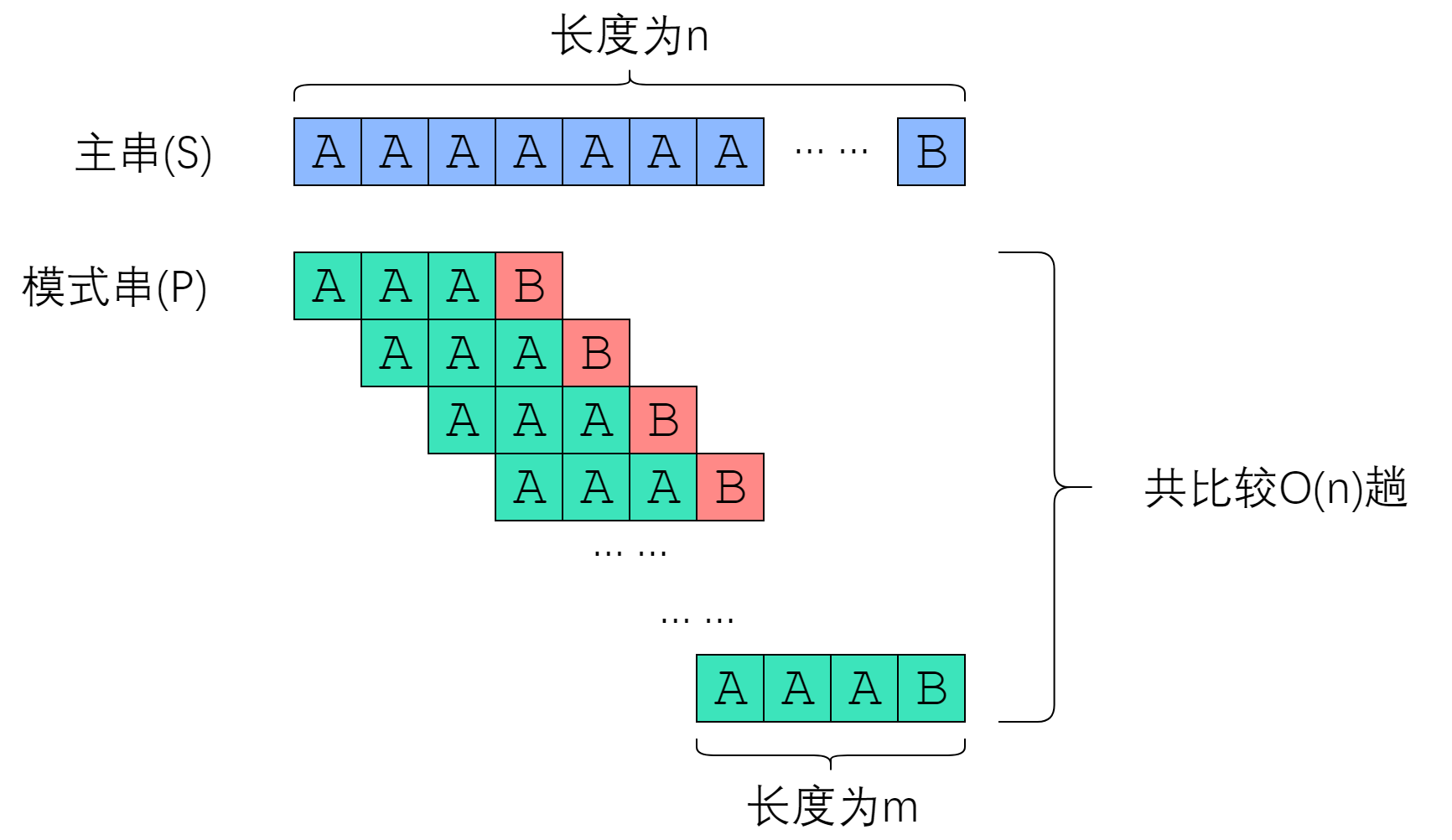
我们很难降低字符串比较的复杂度(因为比较两个字符串,真的只能逐个比较字符)。因此,我们考虑降低比较的趟数。如果比较的趟数能降到足够低,那么总的复杂度也将会下降很多。 要优化一个算法,首先要回答的问题是“我手上有什么信息?” 我们手上的信息是否足够、是否有效,决定了我们能把算法优化到何种程度。请记住:尽可能利用残余的信息,是KMP算法的思想所在。
在 Brute-Force 中,如果从 S[i] 开始的那一趟比较失败了,算法会直接开始尝试从 S[i+1] 开始比较。这种行为,属于典型的“没有从之前的错误中学到东西”。我们应当注意到,一次失败的匹配,会给我们提供宝贵的信息——如果 S[i : i+len(P)] 与 P 的匹配是在第 r 个位置失败的,那么从 S[i] 开始的 (r-1) 个连续字符,一定与 P 的前 (r-1) 个字符一模一样!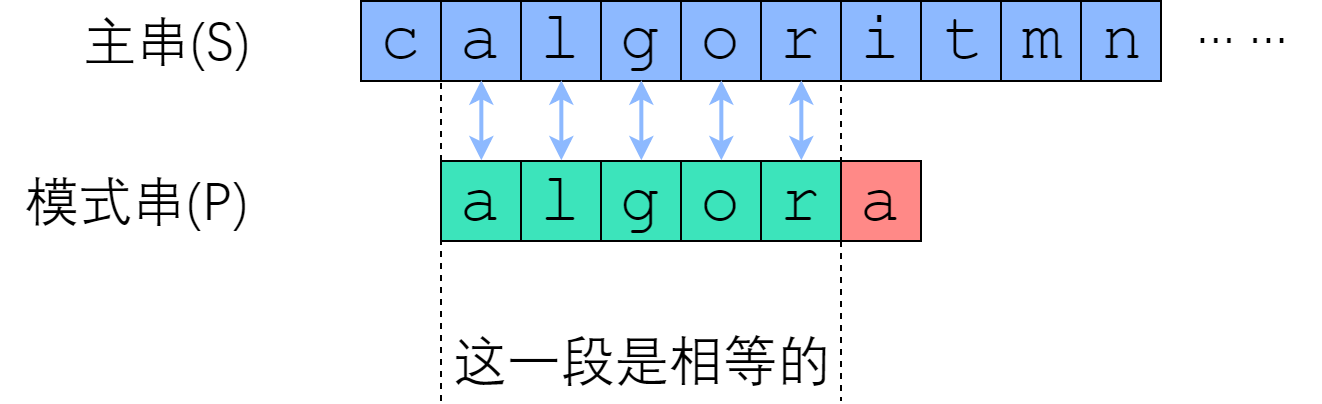
需要实现的任务是“字符串匹配”,而每一次失败都会给我们换来一些信息——能告诉我们,主串的某一个子串等于模式串的某一个前缀。但是这又有什么用呢?
有些趟字符串比较是有可能会成功的;有些则毫无可能。我们刚刚提到过,优化 Brute-Force 的路线是“尽量减少比较的趟数”,而如果我们跳过那些绝不可能成功的字符串比较,则可以希望复杂度降低到能接受的范围。 那么,哪些字符串比较是不可能成功的?来看一个例子。已知信息如下:
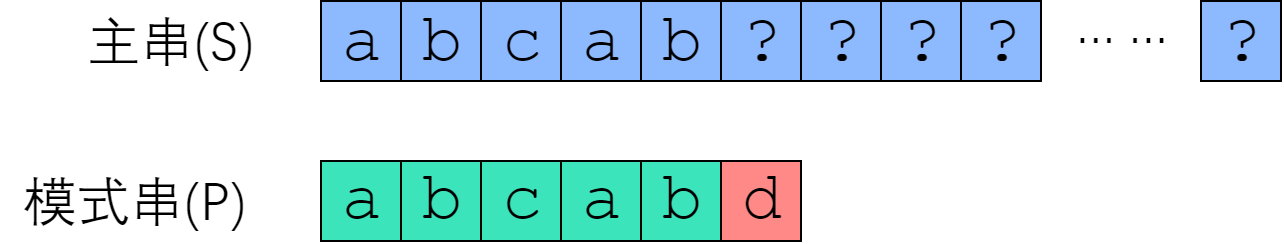
next数组是对于模式串而言的。P 的 next 数组定义为:$next[i]$ 表示 $P[0]$ ~ $P[i]$ 这一个子串,使得 前k个字符恰等于后k个字符 的最大的k. 特别地,k不能取i+1(因为这个子串一共才 i+1 个字符,自己肯定与自己相等,就没有意义了)。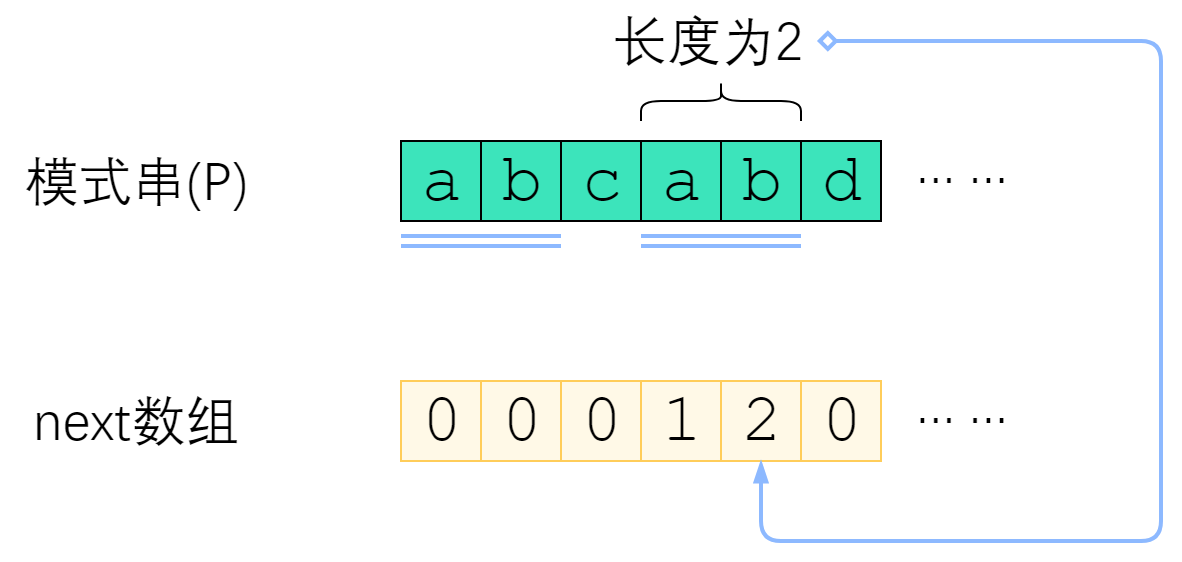
上图给出了一个例子。P=”abcabd”时,$next[4]$=2,这是因为$P[0]$ ~ $P[4]$ 这个子串是”abcab”,前两个字符与后两个字符相等,因此$next[4]$取2. 而$next[5]=0$,是因为”abcabd”找不到前缀与后缀相同,因此只能取0.
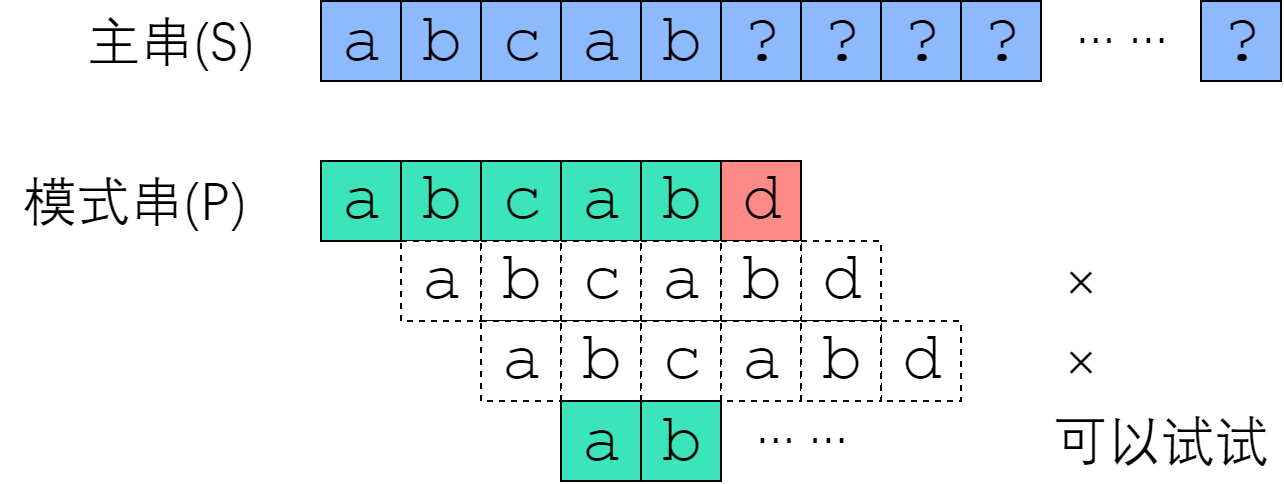
如果把模式串视为一把标尺,在主串上移动,那么 Brute-Force 就是每次失配之后只右移一位;改进算法则是每次失配之后,移很多位,跳过那些不可能匹配成功的位置。但是该如何确定要移多少位呢?
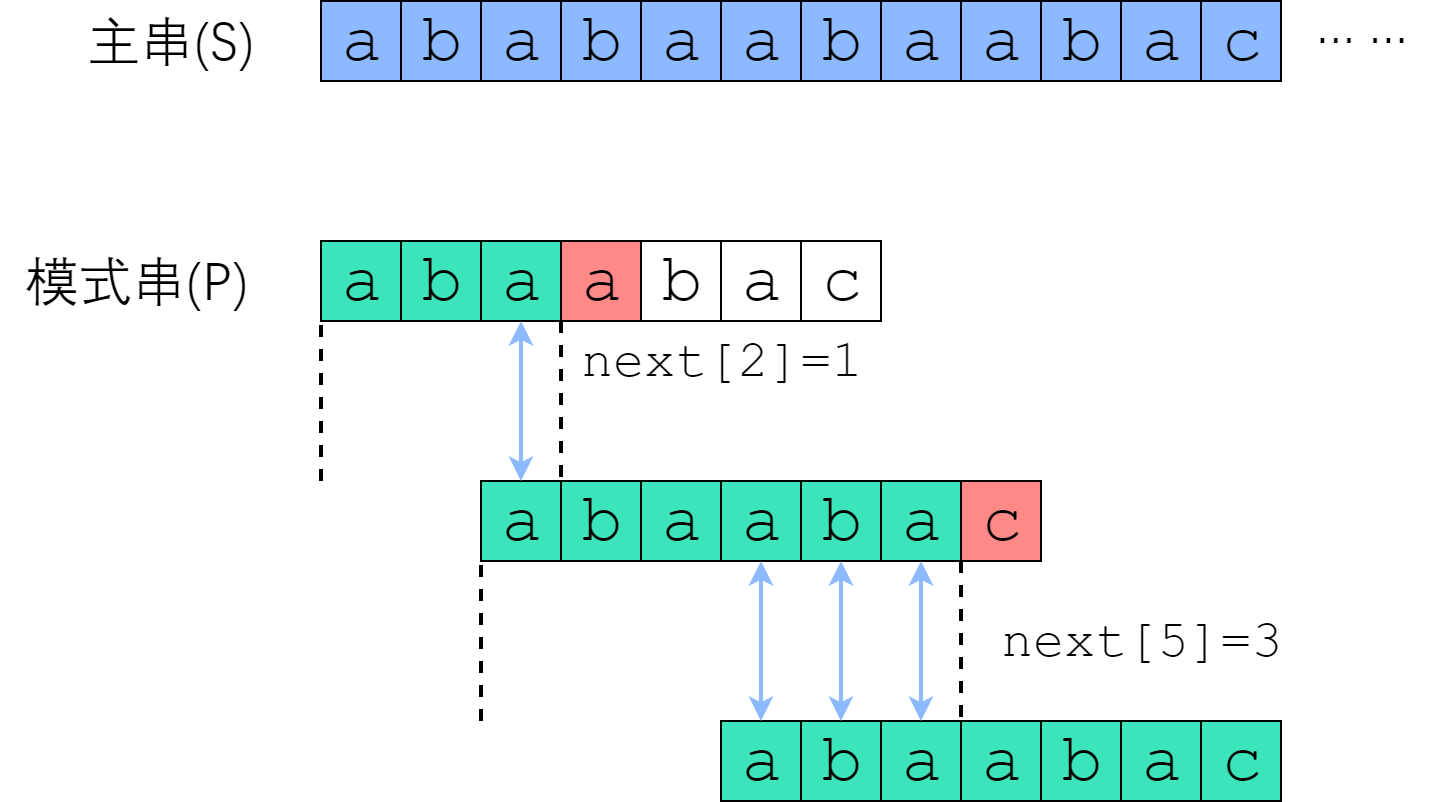
在 $S[0]$ 尝试匹配,失配于 $S[3] <=> P[3]$ 之后,我们直接把模式串往右移了两位,让 $S[3]$ 对准 $P[1]$. 接着继续匹配,失配于 $S[8] <=> P[6]$, 接下来我们把 P 往右平移了三位,把 $S[8]$ 对准 $P[3]$. 此后继续匹配直到成功。
我们应该如何移动这把标尺?很明显,如图中蓝色箭头所示,旧的后缀要与新的前缀一致(如果不一致,那就肯定没法匹配上了)!
回忆next数组的性质:$P[0]$ 到 $P[i]$ 这一段子串中,前$next[i]$个字符与后$next[i]$个字符一模一样。既然如此,如果失配在 $P[r]$, 那么$P[0]$~$P[r-1]$这一段里面,前$next[r-1]$个字符恰好和后$next[r-1]$个字符相等——也就是说,我们可以拿长度为 $next[r-1]$ 的那一段前缀,来顶替当前后缀的位置,让匹配继续下去!
您可以验证一下上面的匹配例子:P[3]失配后,把P[next[3-1]]也就是P[1]对准了主串刚刚失配的那一位;P[6]失配后,把P[next[6-1]]也就是P[3]对准了主串刚刚失配的那一位。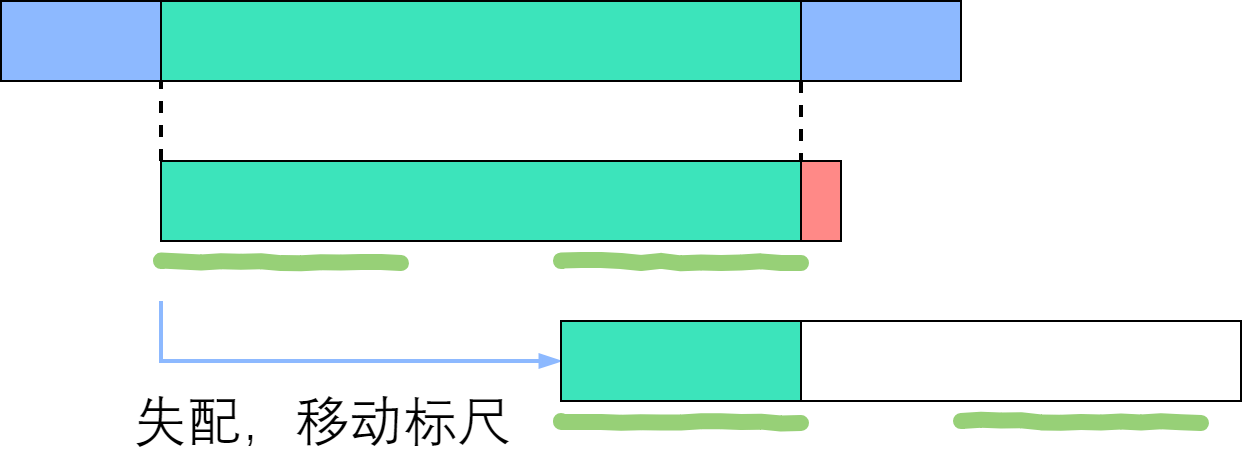
如上图所示,绿色部分是成功匹配,失配于红色部分。深绿色手绘线条标出了相等的前缀和后缀,其长度为next[右端]. 由于手绘线条部分的字符是一样的,所以直接把前面那条移到后面那条的位置。因此说,next数组为我们如何移动标尺提供了依据。接下来,我们实现这个优化的算法。
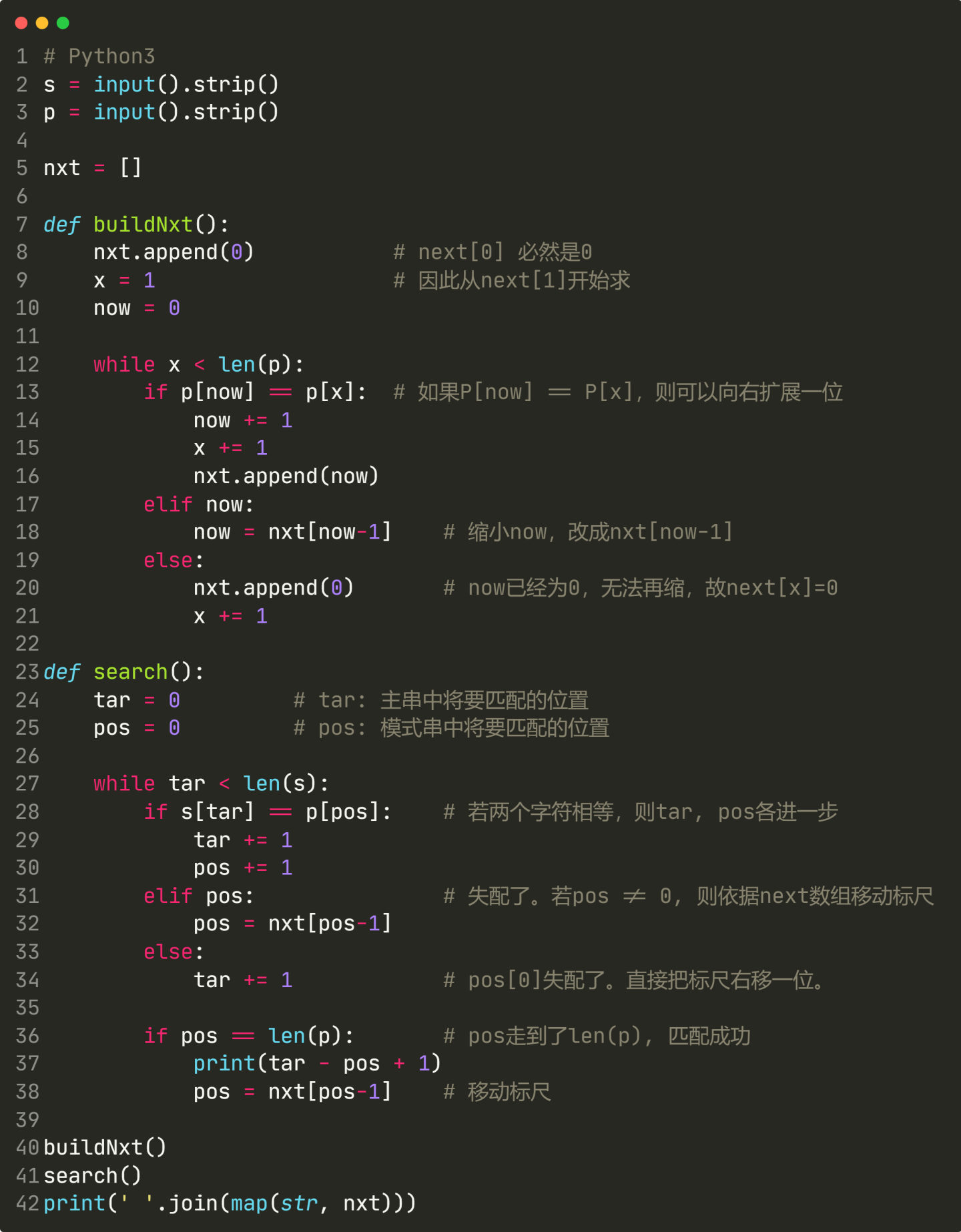
了解了利用next数组加速字符串匹配的原理,我们接下来代码实现之。分为两个部分:建立next数组、利用next数组进行匹配。 首先是建立next数组。我们暂且用最朴素的做法,以后再回来优化:

如上图代码所示,直接根据next数组的定义来建立next数组。不难发现它的复杂度是 $O(m2)O(m^2)O(m^2)$ 的。
接下来,实现利用next数组加速字符串匹配。代码如下:

如何分析这个字符串匹配的复杂度呢?乍一看,pos值可能不停地变成next[pos-1],代价会很高;但我们使用摊还分析,显然pos值一共顶多自增len(S)次,因此pos值减少的次数不会高于len(S)次。由此,复杂度是可以接受的,不难分析出整个匹配算法的时间复杂度:O(n+m).
终于来到了我们最后一个问题——如何快速构建next数组。
首先说一句:快速构建next数组,是KMP算法的精髓所在,核心思想是“P自己与自己做匹配”。
为什么这样说呢?回顾next数组的完整定义:

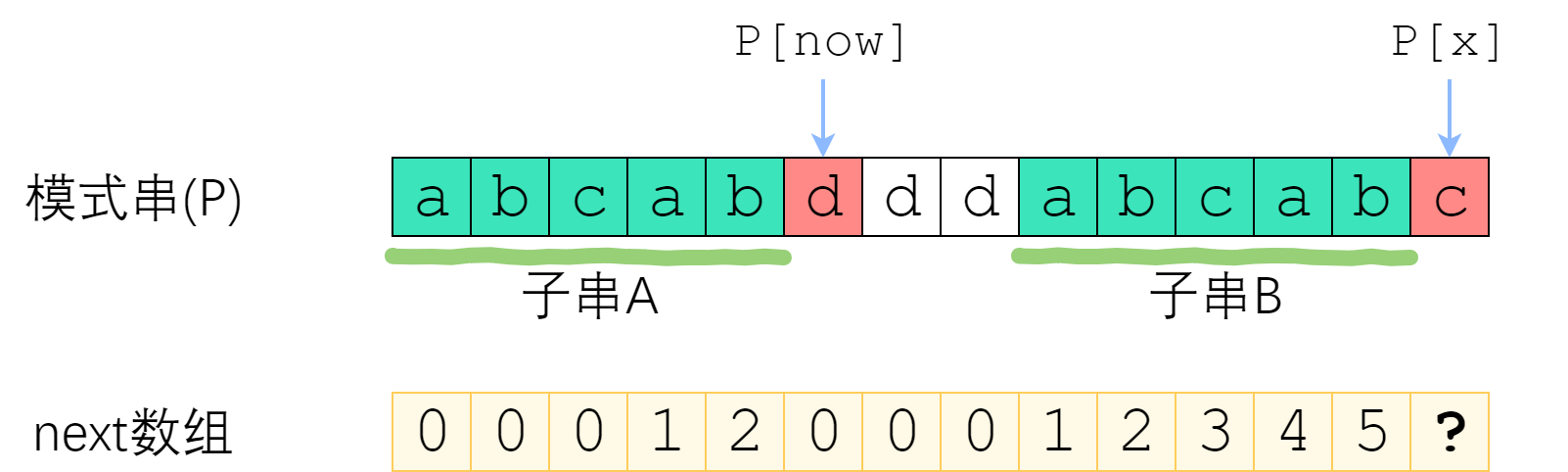
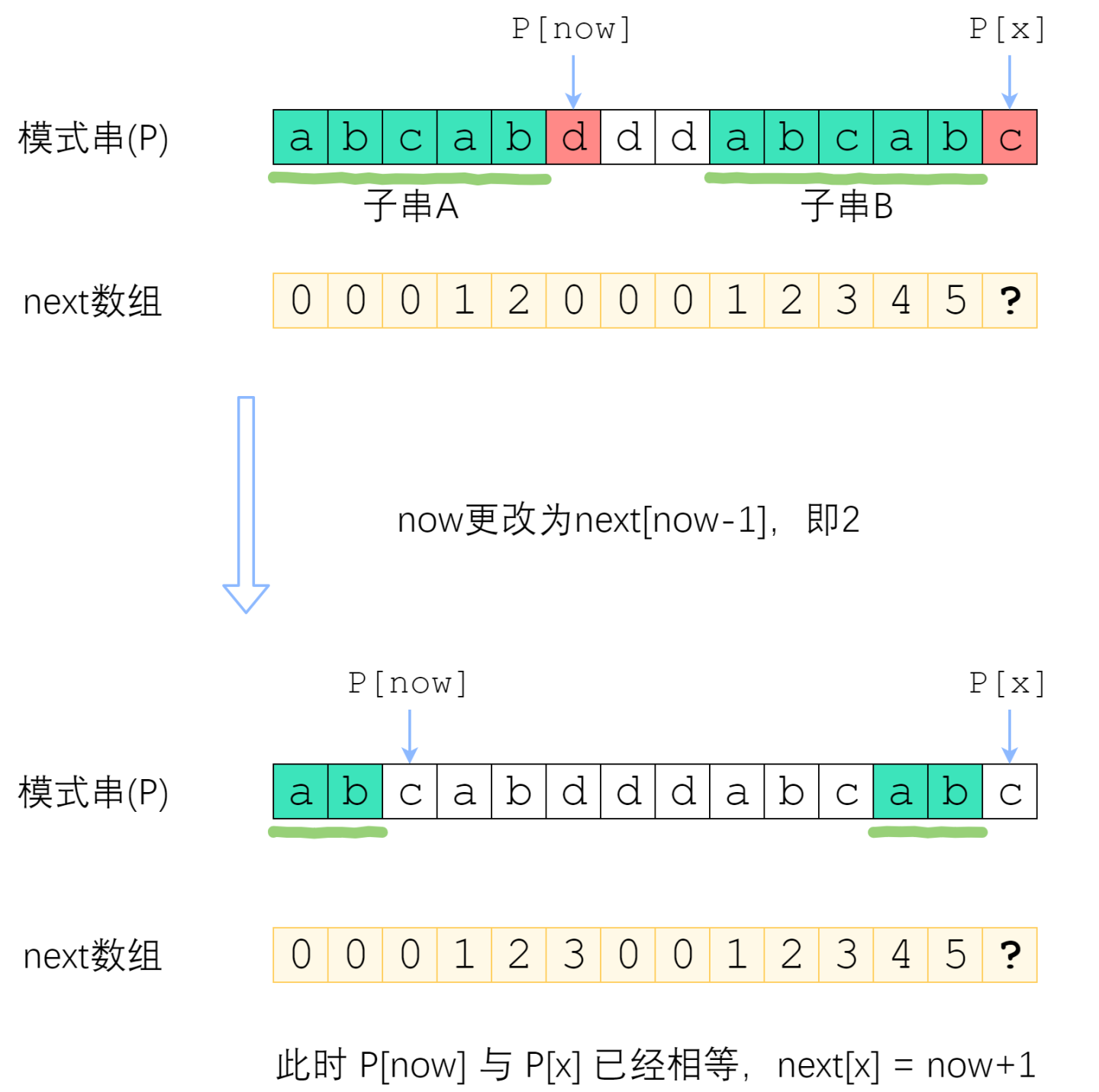

最后附上洛谷P3375 【模板】KMP字符串匹配 的Python和Java版代码:
1 | public class Kmp { |
学完了这么牛逼的算法,将复杂度从$O(m*n)$降低到了$O(m+n)$,那么来看一下jdk源码String.indexOf和contains是使用kmp算法吗?
1 | public boolean contains(CharSequence s) { |
contains直接调用indexOf方法
1 | static int indexOf(char[] source, int sourceOffset, int sourceCount, |
indexOf方法采用的是非常朴素的Brute-Force暴力算法。
所以,为什么jdk没有采用kmp算法?
这就不清楚了,一种说法是短字符串的比较,开辟空间消耗的资源远远比计算的大,kmp更适用的场景是,固定的pattern,不断去比较新的字符串,复用next数组。
很多人在各种平台开通会员时,经常会选择自动续费,连续包月,毕竟便宜啊。
但是设置后,过个个把月,就不怎么使用功能了,然而钱还是每月哗哗哗的扣款,心疼啊。
本文就描述微信2022新版如何取消自动扣款设置。
大家上网搜的基本都是旧版方案,比如这篇微信怎么样关闭自动扣款,旧版微信在【我的】界面确实有【支付这个选项】,然而在最新的2022版本中已经没有了。
没有了不要慌,这就来说新版怎么取消。
2022微信新版的操作界面在【我的-服务-钱包-支付设置-自动续费中】





该页面展示的是你自动续费的选项,选中你要取消的服务,进入详情页

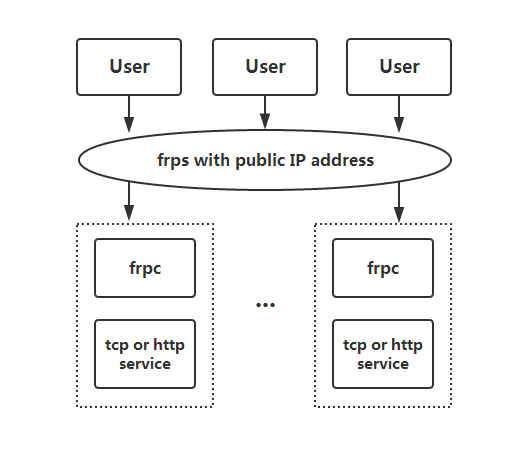
之前写过一篇ngrok+nginx实现windows远程桌面连接实现了在公司远程连接家里的电脑,最近发现另一个开源网络穿透frp似乎更优秀,其在git的star达到了61.4k,本篇就是用frp搭建网络穿透。
官方的解释为
frp is a fast reverse proxy to help you expose a local server behind a NAT or firewall to the Internet. As of now, it supports TCP and UDP, as well as HTTP and HTTPS protocols, where requests can be forwarded to internal services by domain name.
frp also has a P2P connect mode.
frp 是一种快速反向代理,可帮助您将 NAT 或防火墙后面的本地服务器暴露给 Internet。 目前,它支持 TCP 和 UDP,以及 HTTP 和 HTTPS 协议,可以通过域名将请求转发到内部服务。
frp 还有一个 P2P 连接模式。
简单来说,你个人本地web服务,通过与frp的服务建立隧道连接,然后别人就可以通过访问frp服务来访问你的本地服务了。
frp的git地址: https://github.com/fatedier/frp
frp官方文档: https://gofrp.org/docs/overview/
官方文档罗列了相关概念和操作,要是有能力尽量阅读官方文档。
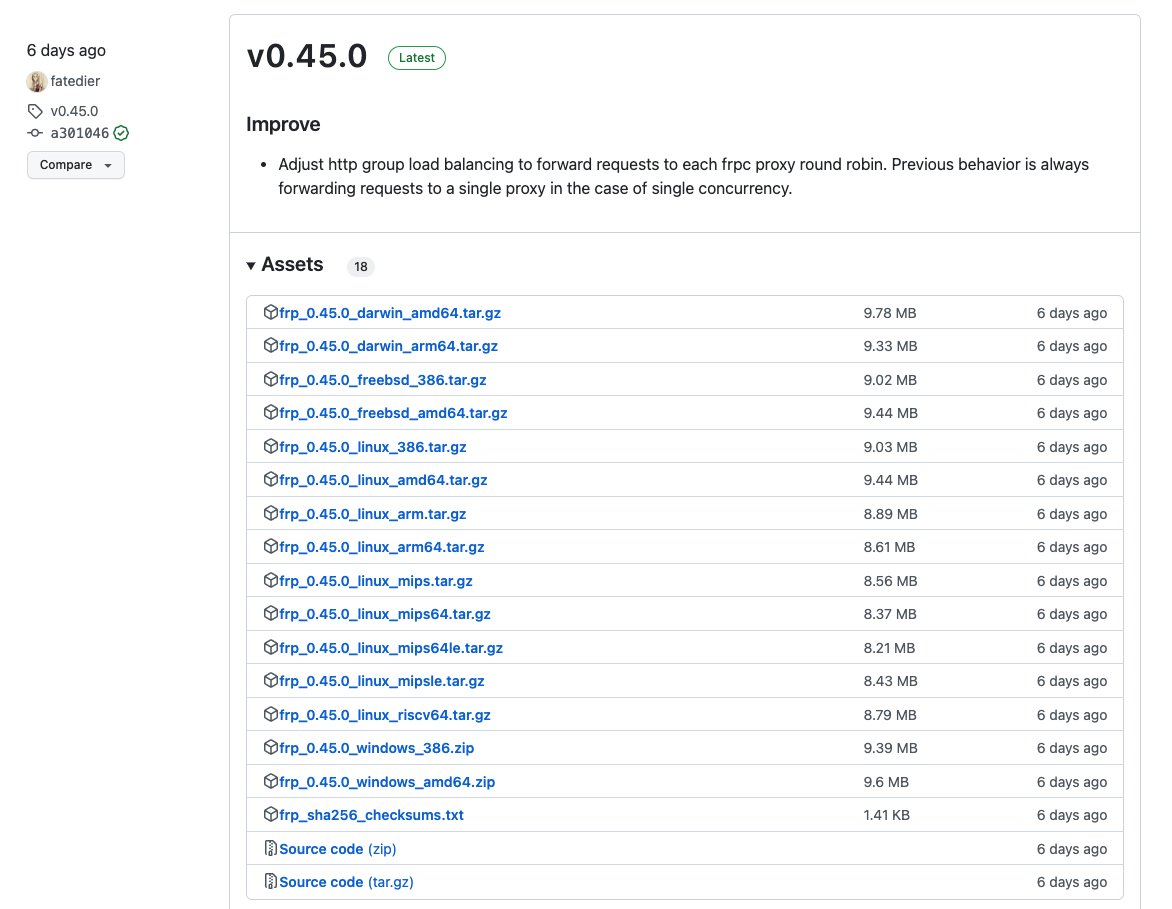
frp可以在release页面进行下载,当前的最新版本为0.045,客户端和服务端为同一个,只不过配置和启动命令不同,大家可以根据自己的操作系统进行下载,要是linux不知道下载那个那个文件,可以查看linux cpu 指令集架构 RISC / CISC | arm | amd | X86/i386 | aarch64这篇文章了解cpu对应的指令集架构下载对应的软件包。
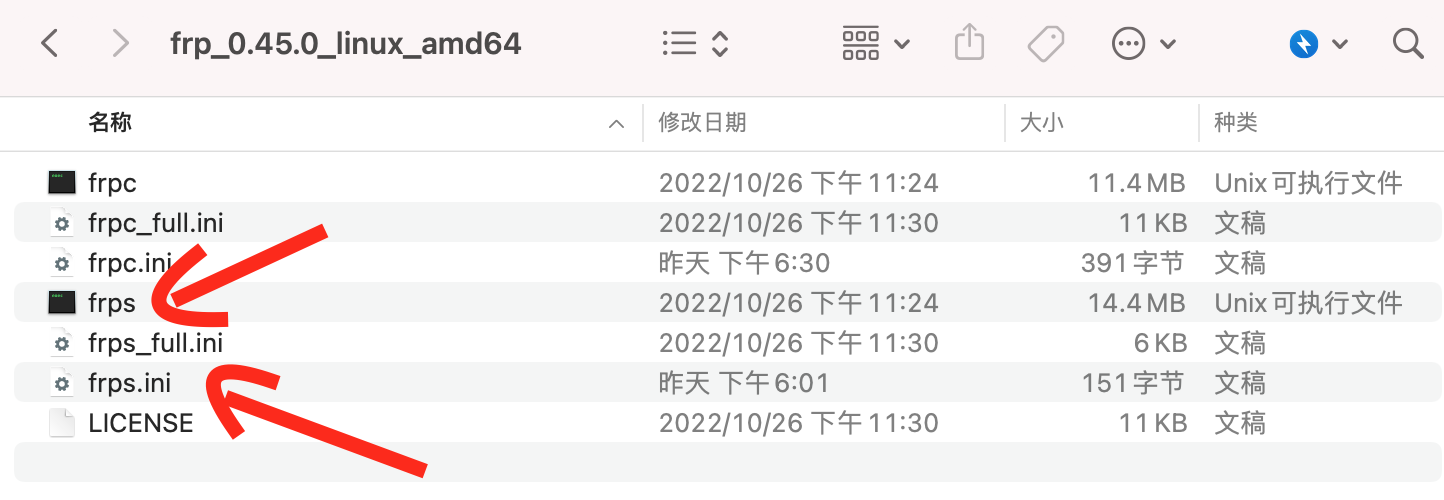
frp的服务端配置文件为frp文件夹下的frps.ini文件,具体完整的配置可以参考frps_full.ini文件.
本人的一个配置为
1 | # 模块名 |
标准的启动命令为
1 | /frp_path/frps -c /frp_path/frps.ini |
只使用命令,当我们推出linux shell后,服务就暂停了,这不是我们想要的结果,部署有两种方式,使用systemd及后天运行脚本。
systemd
systemd为官方推荐的部署方式,参考官方文档 使用 systemd
后台运行
我们也可以使用linux后台运行命令自己部署
1 | nohup /frp_path/frps -c /frp_path/frps.ini & |
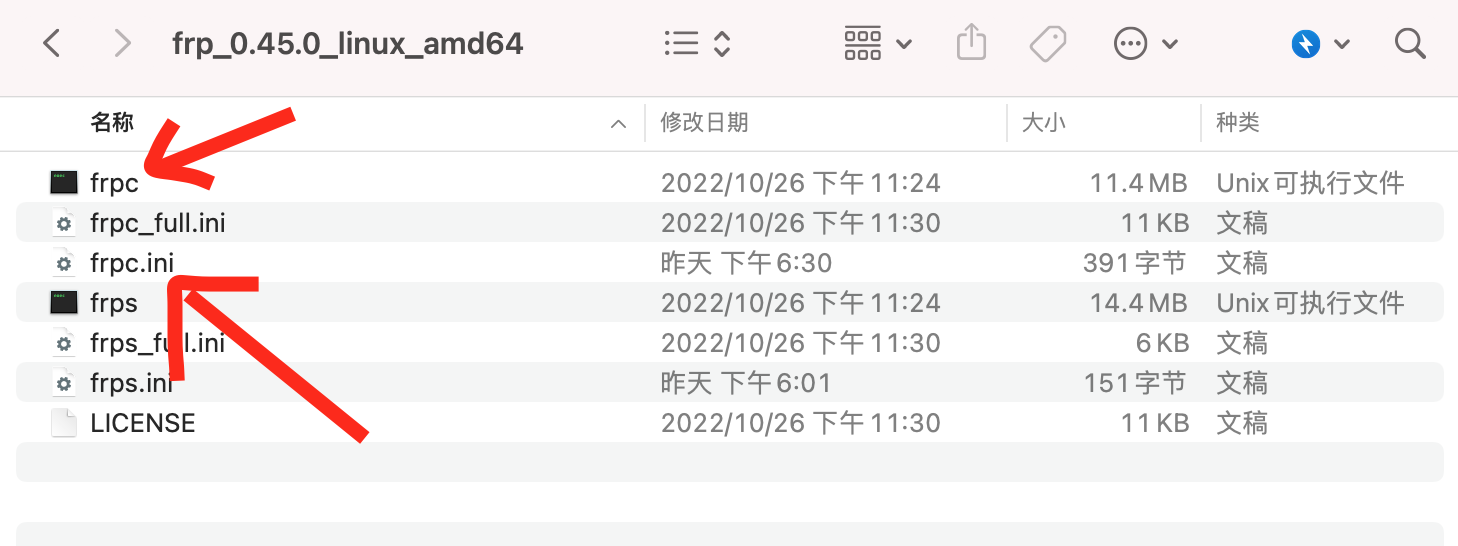
frp的客户端配置文件为frp文件夹下的frpc.ini文件,具体完整的配置可以参考frpc_full.ini文件.
本人的一个配置为
1 | # frpc.ini |
标准的启动命令为
1 | ./frpc -c ./frpc.ini |
linux 下推荐使用 systemd
windows下推荐自己编写.bat文件,然后配置为开机启动项,windows的开机启动配置可以参考win10 开机启动,无需登录
登录你的域名管理,配置frp.xxx.com及*.frp.xxx.com指向你的frp server地址
一个简单的nginx配置如下
1 | server { |
本质上就是当后续使用服务的时候,如访问者访问http://web1.frp.xxx.com 时,将请求转交给frp server处理。
登录 http://server ip:7091 进行访问,端口为之前服务端的dashboard_port配置。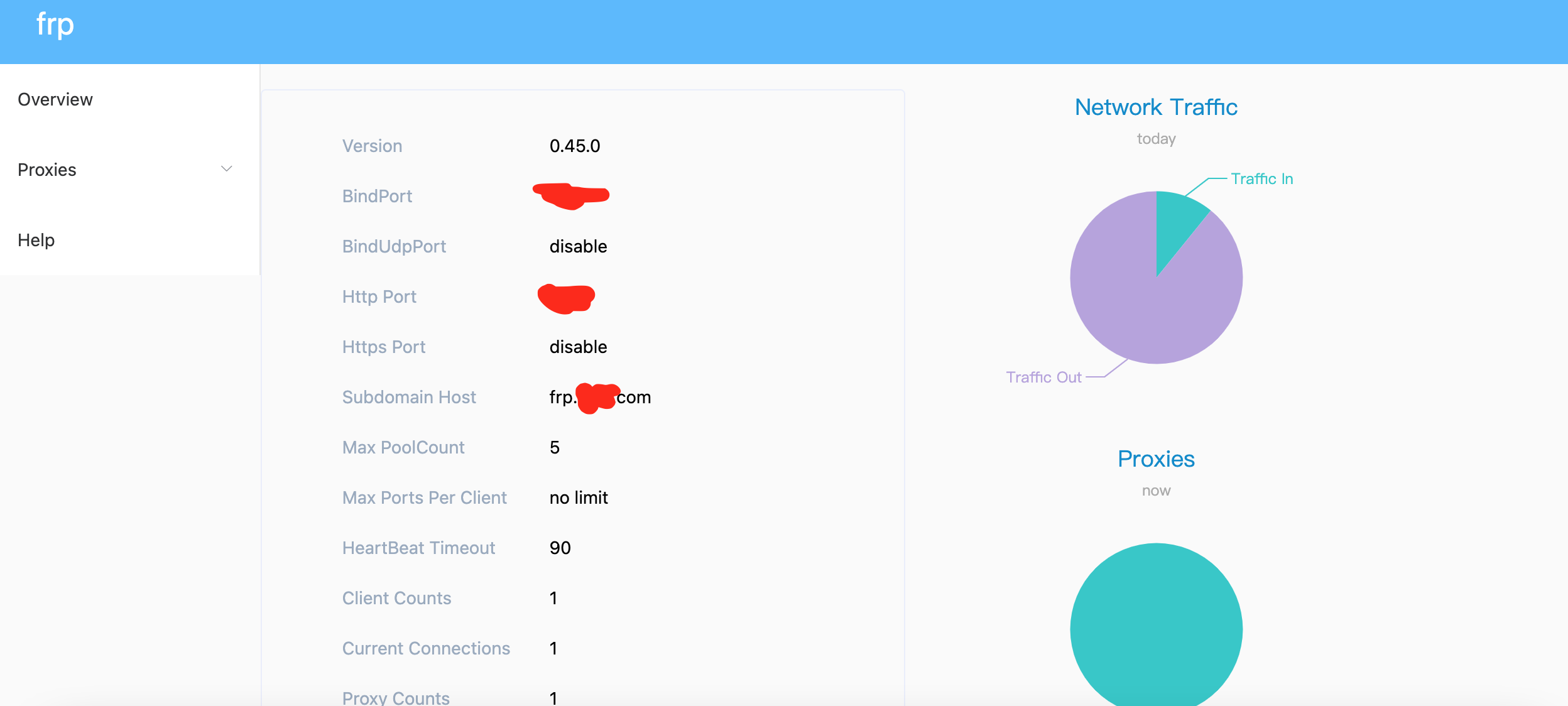
通过以下地址 frp.xxx.com:3389 进行连接
如果是页面,直接访问 web1.frp.xxx.com ,输入用户名密码后即可进行访问
如果是程序调用,需要加上 Authorization 的header,具体可以参考文章 JAVA Http Basic auth
参考身份认证 ,目前 frpc 和 frps 之间支持两种身份验证方式,token 和 oidc,默认为 token。
http相关的可以通过设置 BasicAuth 鉴权实现简单的认证。
复杂可以通过安全地暴露内网服务,这样服务只能被部署了visitor frp client的机器访问,缺点是需要部署frp cli。
至此,使用frp搭建的http穿透及远程桌面连接已顺利实现。
有时候我们希望一些常用程序在开机后就自动运行。
比如笔者就配置了一个远程登录结合frp网络穿透实现windows远程连接,那么就需要frp程序在开机时就运行。
那么如何配置呢?
上网搜索开机启动,有非常多的答案,但大多方案都有一个弊端,需要登录后才会启动。
比如知乎的这篇Windows10 开机自启动设置 中给的【任务选项->启动】配置及【运行窗口->shell:startup】启动项选项两个方案,都是需要用户登录后才能生效的。
那么有没有不需要启动就能登录的?
有的,可以采用设置定时任务的方式实现。
1、在Windows10桌面,右键点击此电脑图标,在弹出菜单中选择“管理”菜单项。
2、然后在打开的计算机管理窗口中,找到“任务计划程序”菜单项。
3、右键,点击创建基本任务
这里创建任务由两种,一种为向导模式的【创建基本任务】,一种为直接模式【创建任务】,我们选择向导模式。
4、进入创建基本任务界面,填入名称和描述,本人的为frp启动,填完后点击下一步。
5、进入触发器选择界面,这里我选择的是计算机启动时,如果你有不同需求,按照自己需求选择。
6、进入操作选择界面,这里我们选择启动程序,因为我们的目标是运行程序。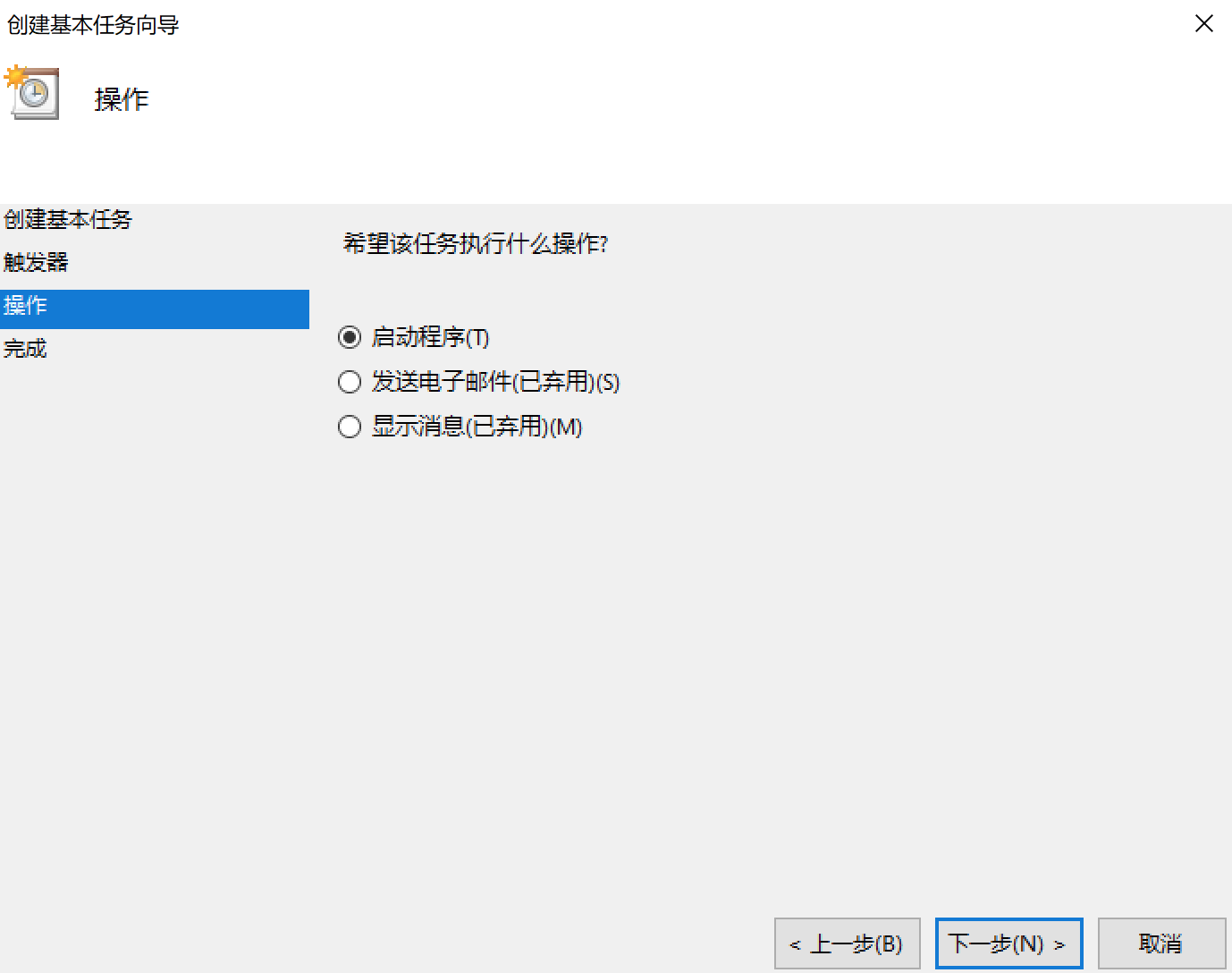
7、点击下一步,点击界面上的浏览按钮,选择我们期望运行的程序,这里本人选择的是自己编写的start_frp.bat脚本。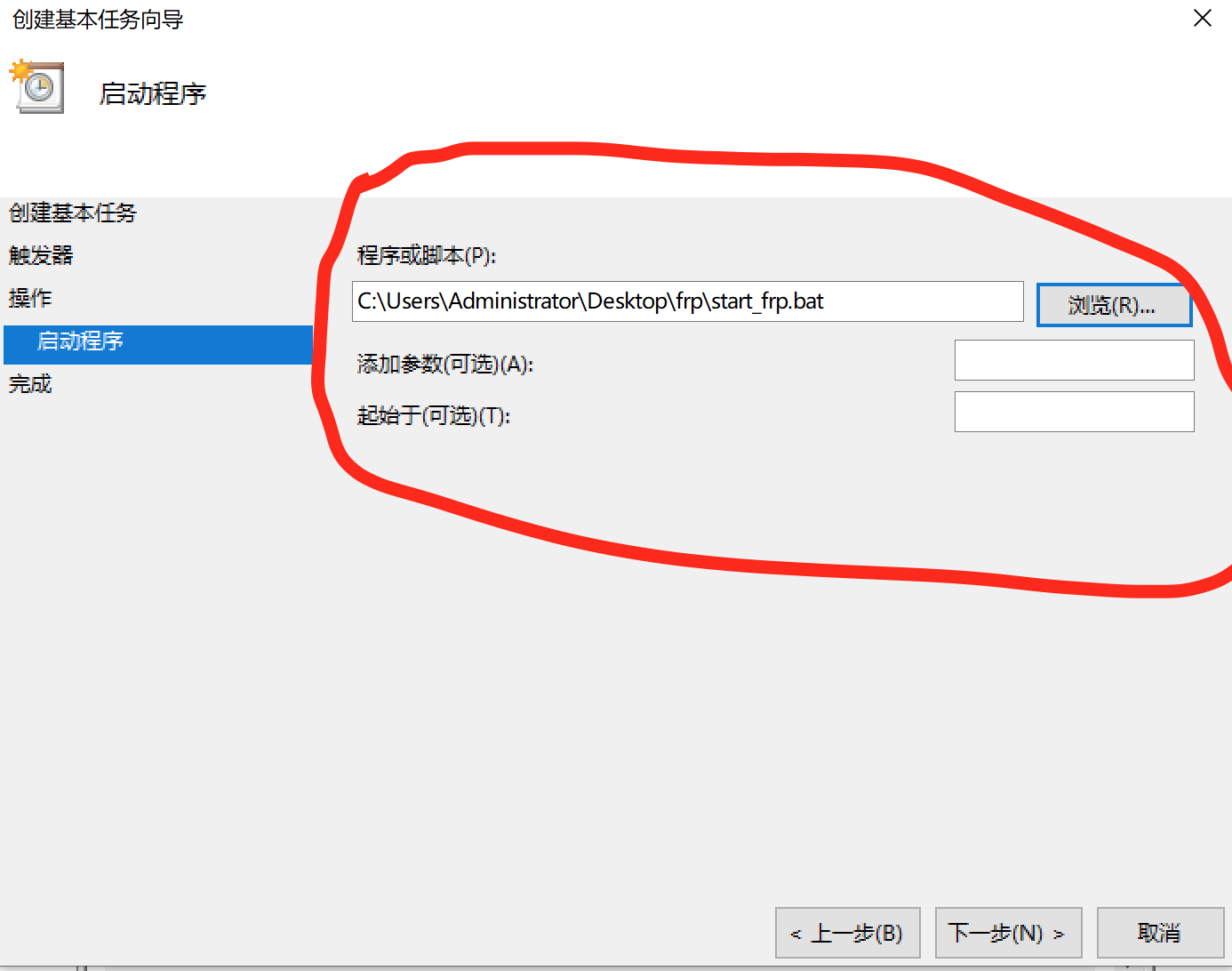
8、最后点击完成完成配置。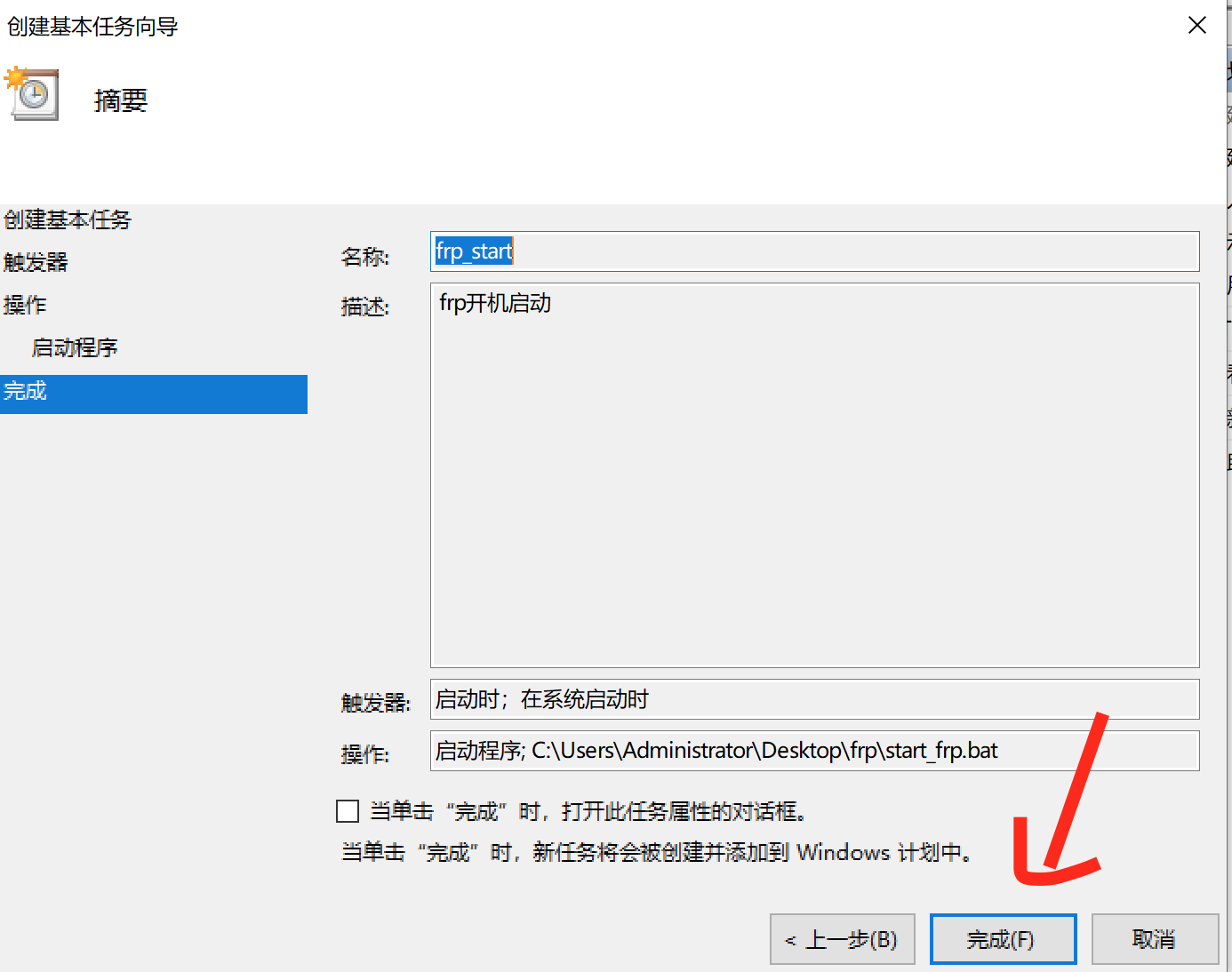
9、回到之前的【管理->系统工具->任务执行计划->任务执行计划程序库】,此时就能看到自己创建的定时任务了。
此时大家可以重启电脑进行验证。
访问者模式是一种行为模式。
访问者模式是一种将数据操作和数据结构分离的设计模式。(觉得太抽象,可以看下面的例子)。
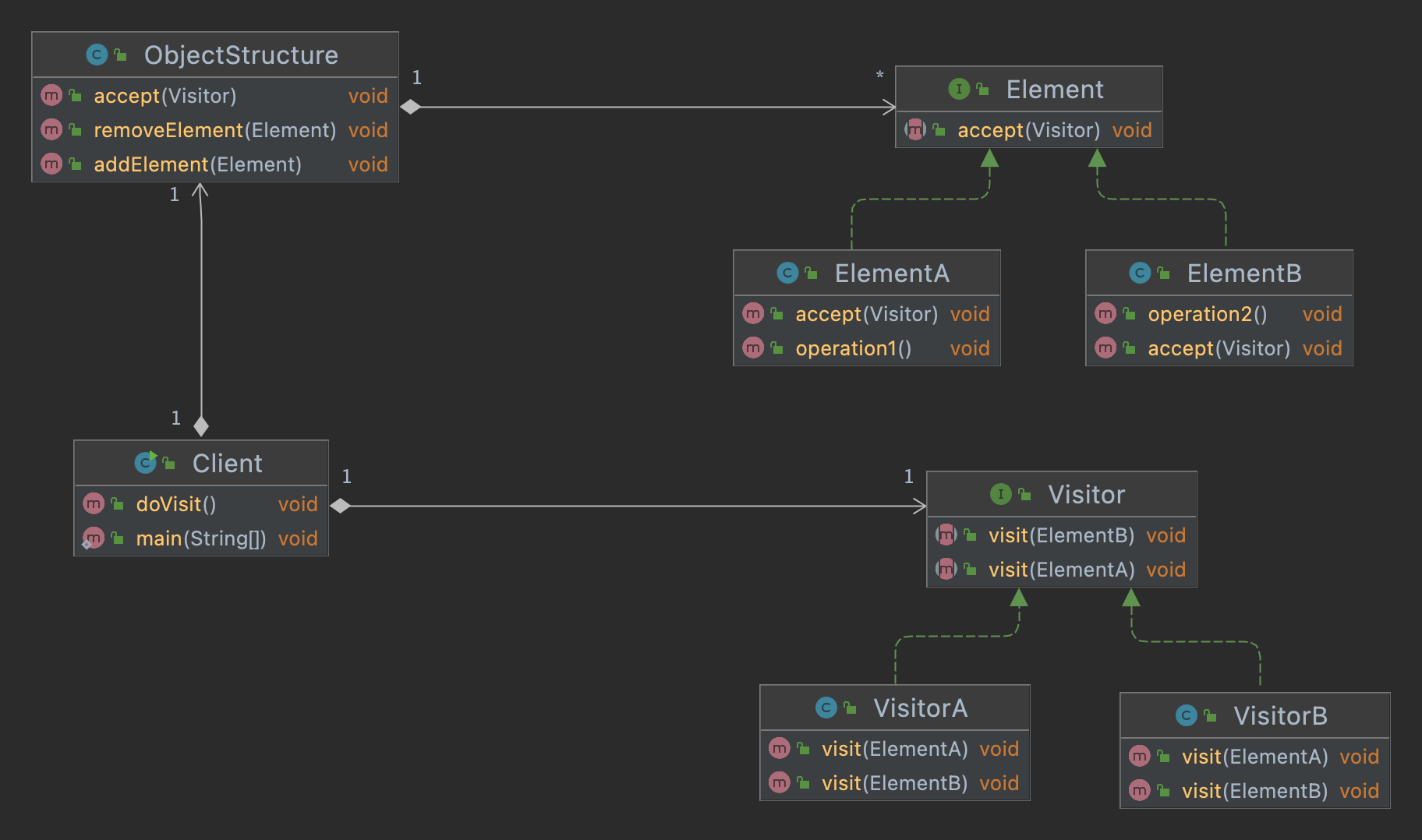
Element接口
1 | /** |
Element Concrete 实现
1 | public class ElementA implements Element { |
visitor接口
1 | /** |
visitor concrete
1 | public class VisitorA implements Visitor { |
ObjectStructure
1 | public class ObjectStructure { |
最后client调用
1 | public class Client { |
执行结果
1 | Visitor A start visit ElementA |
依然很抽象,看下面的例子吧。
访问者模式,用游客访问城市经典的例子再合适不过了.
不同的游客有不同的访问行为,跟团游和自驾游或休闲游在游览景点是的行为也是完全不相同的,完美符合访问者模式中的访问者这一对象。
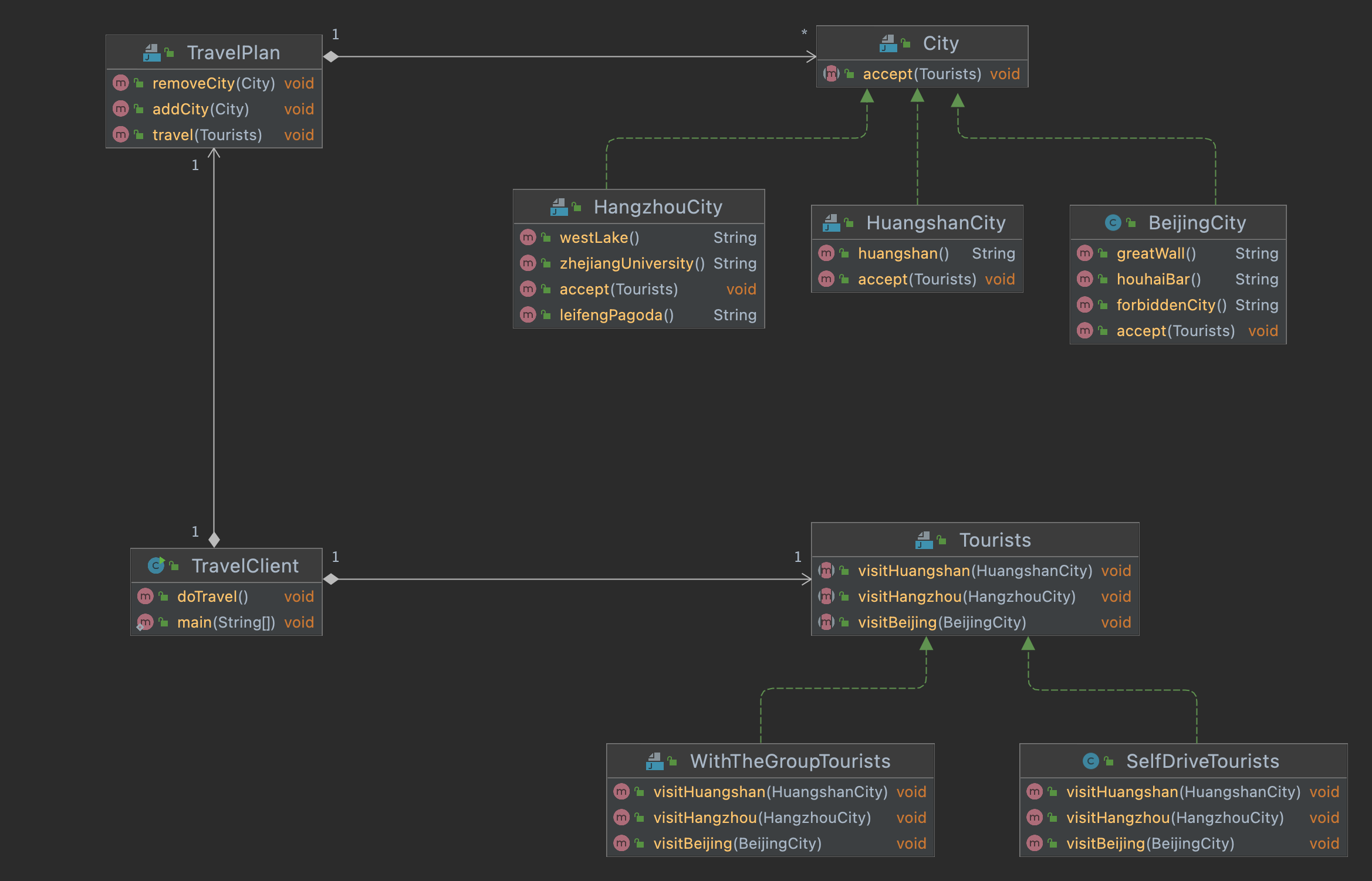
City
1 | /** |
CityConcrete
1 | /** |
Tourists
1 |
|
TouristsConcrete
1 | /** |
TravelPlan
1 | /** |
TravelClient
1 | /** |
执行结果
1 | >>>>开始跟团旅游北京 |
以上例子代码可在个人github项目design-patterns中找到。
使用idea阅读spark 源码时,如果是第一次导入,会碰到 org.apache.spark.sql.catalyst.parser.SqlBaseParser包下相关的类无法找到的问题。
如 AstBuilder 继承 SqlBaseBaseVisitor,SqlBaseBaseVisitor就无法找到。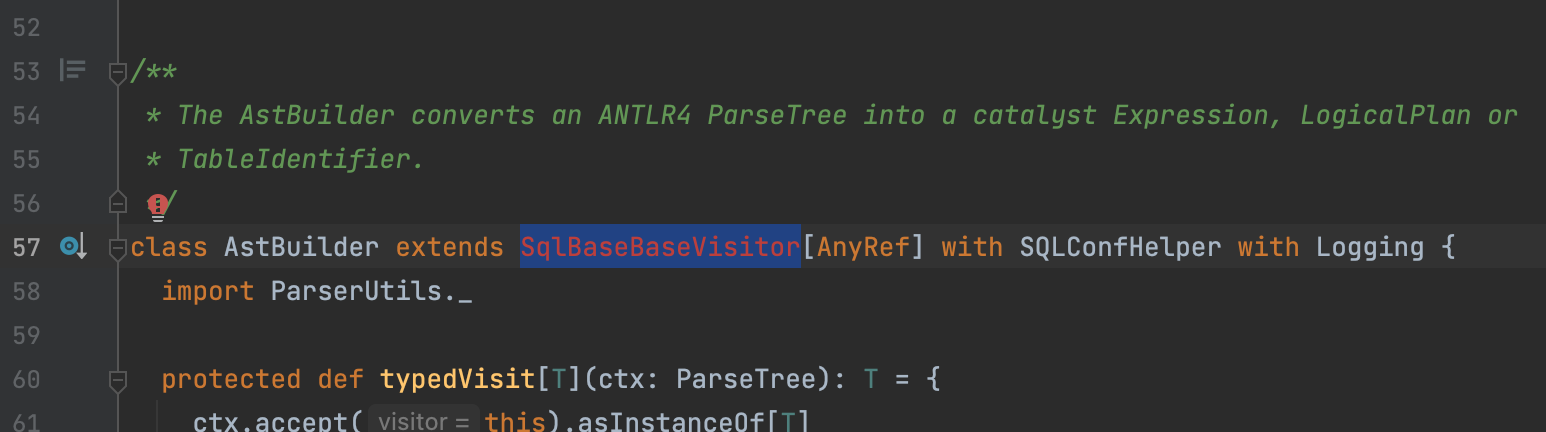
org.apache.spark.sql.catalyst.parser.SqlBaseParser包下相关的代码并不是人工写的源码,而是antlr4框架自动生成的代码,因为代码没有生成,所以idea无法找到相关代码。
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It’s widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build parse trees and also generates a listener interface (or visitor) that makes it easy to respond to the recognition of phrases of interest.
ANTLR(另一种语言识别工具)是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。 它广泛用于构建语言、工具和框架。 从语法中,ANTLR 生成一个可以构建解析树的解析器,还生成一个侦听器接口(或访问者),可以轻松响应对感兴趣短语的识别。
简单来说就是定义语言此法和语法的框架,比如sql的解析。
对应的同类产品有:
spark使用antlr4来解析sql语法,生成语法树,之后应用语法树生成相关逻辑树及最后的物理执行计划。
如果你对sparksql 采用antlr4 解析比较感兴趣,这里推荐
ANTLR4-SqlBase这个开源项目,该作者为 《Spakr SQL内核剖析》 一书作者剥离的Parser模块,用于查看Spark SQL语法解析SQL后生成的语法树的项目。
使用antlr4插件生成代码,并将相关代码引入到classpath中。
本人mac系统
在 intellij Idea->Preference->Plugins
下搜索 antlr4,安装插件
找到SqlBase.g4文件,该文件在sql/catalyst/src/main/antlr4/org.apache.spark.sql.catalyst.parser下
右键,找到antlr4插件的Generate ANTLR Recognizer选项,点击
如下图所示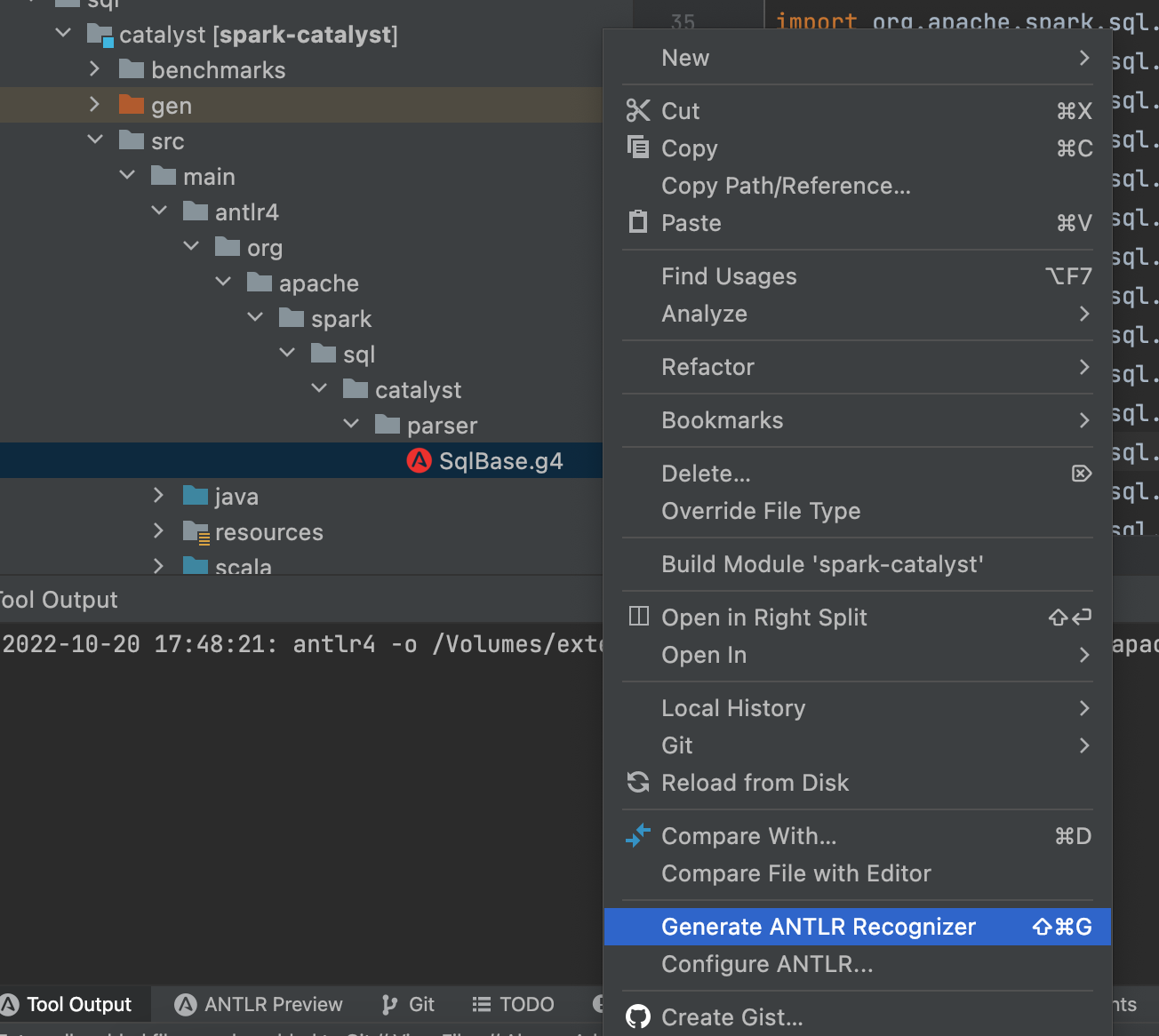
会在 sql/catalyst 下创建gen文件夹,生成对应的代码,如果想修改目录,可以点击configure ANTLR修改,这里直接默认的就好
生成的代码结构如下图
选中再上一步生成的gen文件,右键,找到Mark Directory as -> Sources Root,将该文件夹设置为代码跟路径,这样idea就会将该文件夹添加到classpath中并编译。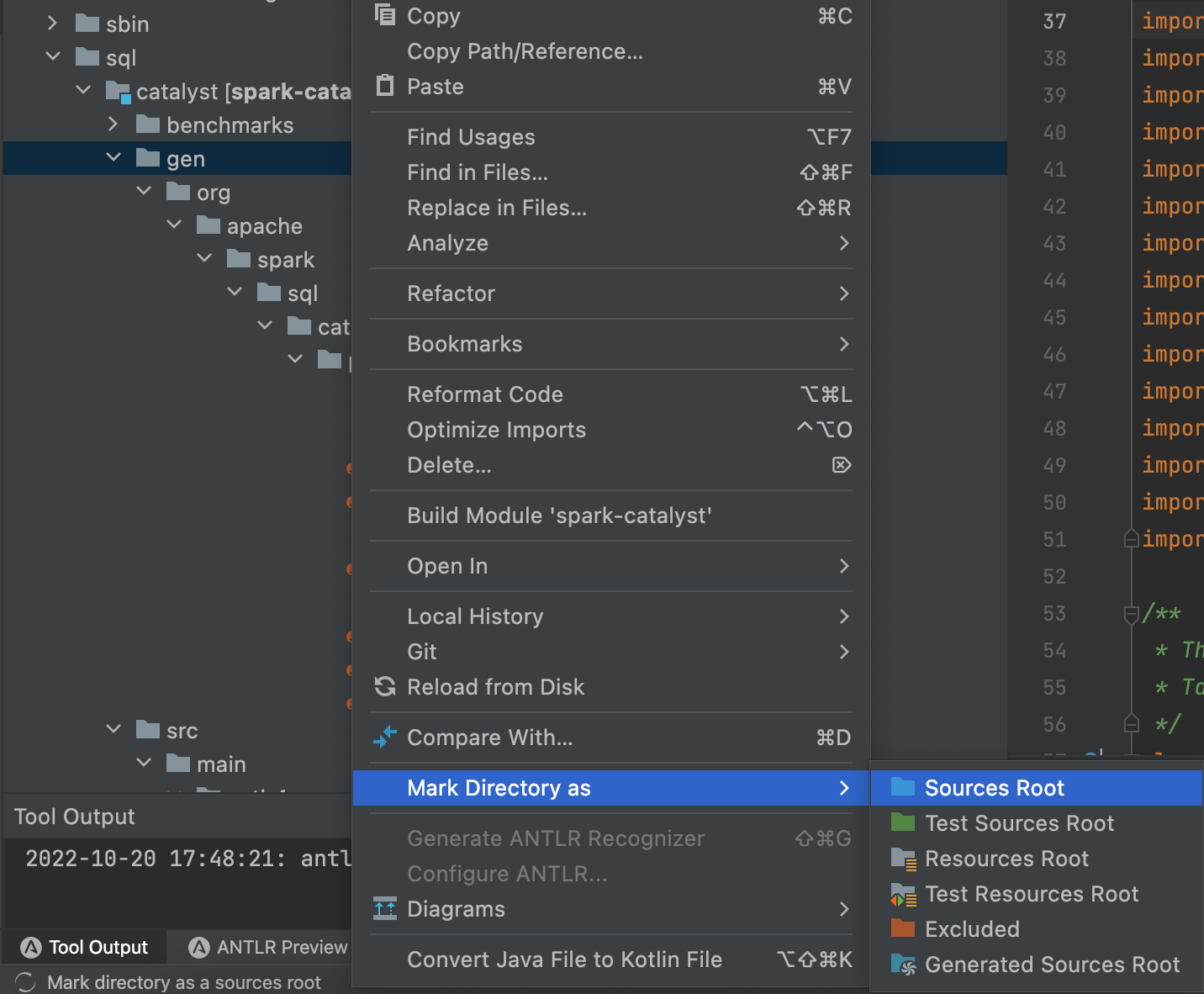
再次查看AstBuilder代码,此时红色错误已消失,代码已找到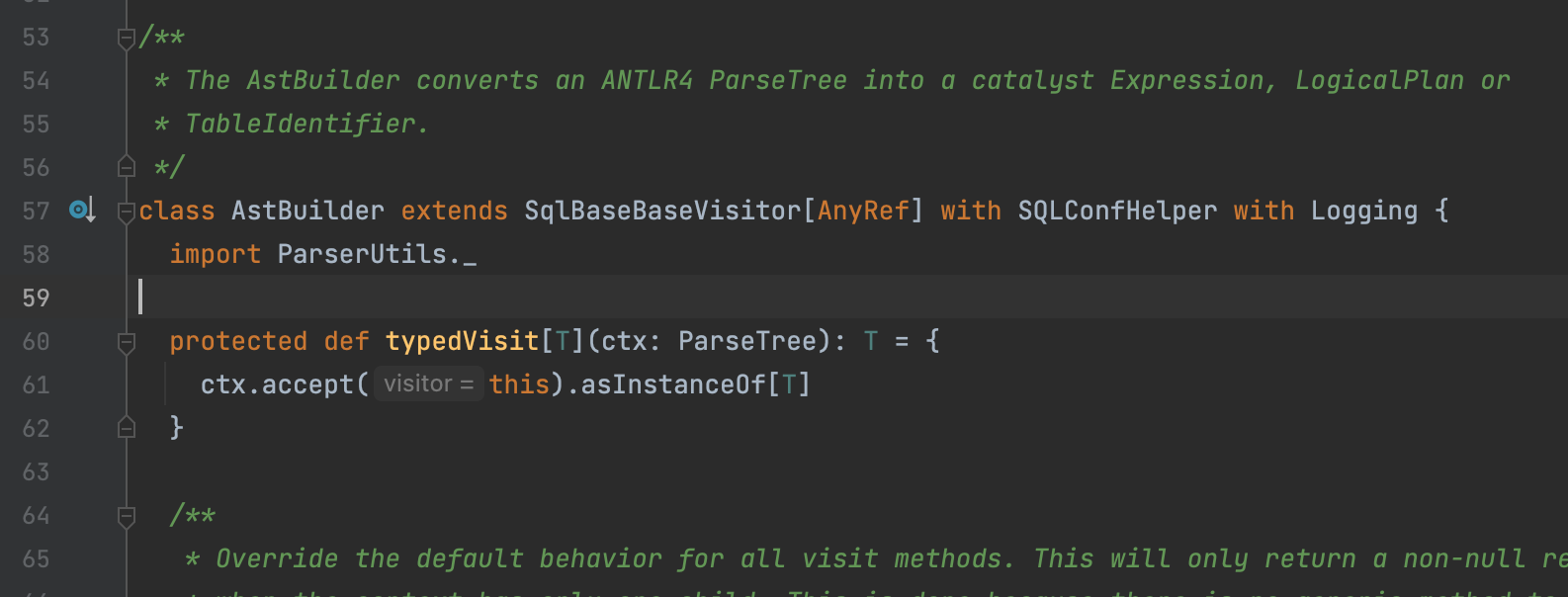
至此,相关问题已解决。
不知大家是否有这样一些场景:
手头有一些很重要的照片,充满回忆,绝对不能丢失,存到电脑里害怕有一天电脑坏掉导致照片丢失,对丢失数据的恐惧是整天困扰你。
手动把文件存到多台电脑又太麻烦。
数据同步就是解决这种烦恼的答案。本文提供了10个最佳软件选项,你可以从中选择以最小的麻烦创建文件和文件夹的备份。希望本文能帮助到你。
本人推荐Syncthing方案
最好的备份和文件同步软件下载:Syncthing ,它允许在两台或多台计算机之间实时同步文件。它涉及连续的文件同步。Syncthing 提供完全的隐私保护,让你安全地同步文件。你可以选择要存储数据的位置,或者是否要与第三方共享。你还可以决定你的数据在互联网上的传输方式。它使用 TLS 加密为你的文件提供私人存储以保密。
特征:
GoodSync由 Siber Systems 开发的 ,是一个帮助在两个目录之间创建备份和同步文件的程序。GoodSync 让你可以在多个计算设备上存储和保存相同版本的文件。GoodSync 确保当你在任何单个设备上修改文件时,更改也会在其他设备上同时进行。因此,从哪个设备访问文件并不重要。它还允许你在远程计算机或服务器与你的计算机之间同步文件。
GoodSync 的用途和好处
Goodsync 是一个非常流行的备份和文件同步程序,提供以下好处-
SyncToy 是 PowerToys 系列中的 Microsoft 产品。在使用 Microsoft Sync Framework 时,已使用 .NET 框架编写它。使用它时要遵循的方法是你必须创建一个左侧文件夹,即“源”文件夹。下一步是创建将作为目标的正确文件夹。
你可以选择任何文件夹作为你的源或目标文件夹,这使得产品非常用户友好。你可以自由选择 USB 闪存驱动器、网络驱动器或任何便携式硬盘驱动器上的任何文件夹。你不必只使用内部硬盘驱动器。
特征:
新的 SyncToy 2.1 带有一些改进的功能,如下所示:
FreeFileSync 与 Windows、macOS 和 Linux 兼容,是开源软件。你可以使用此软件创建和管理所有重要文件的备份副本。FreeFileSync 在同步文件时采用了一种聪明的方法。它能够发现源文件夹和目标文件夹之间的差异。这样,FreeFileSync 只传输最少的数据,而忽略目标文件夹中的相同数据。
特征:
有一些功能使 FreeFileSync 与 Goodsync 不同:

你可以使用 Duplicati 将文件存储在在线云服务上。作为备份客户端,Duplici 通过完全加密确保安全备份。备份经过加密和压缩并存储在云存储和远程文件服务器上。你的备份始终使用内置调度程序定期更新。Duplicati 也使用 AES-256 加密。
特征:

Rsync 涉及最少的数据复制,仅复制文件中已使用算法更改的那部分。它适用于远程同步,涉及远程和本地以及 Linux 和 Unix 系统上的文件的复制和同步。Rsync 今天被广泛用作一种已大大改进的复制命令。它作为备份和镜像软件非常有用。
特征:
作为一个命令行程序,Rclone 可让你在 Amazon S3、Dropbox、Google Cloud Storage 等各种平台之间同步文件和目录。Rclone 作为单个二进制文件出现,是一个 Go 程序。它是免费提供的开源软件。
特征:

PureSync 由 Jumping Bytes 推出。这是一个 Windows 程序,可帮助同步文件和文件夹,同时在后台执行自动备份。它也可以在网络卷、外部硬盘驱动器和数码相机上工作。当你将数码相机中的照片导入计算机时,PureSync 会派上用场。
特征:
官网
文件大小: 10.5 MB
系统支持: Windows
Allway Sync 的工作效率非常高,允许你在所有设备上同步文件的多个副本,无论是 PC、笔记本电脑还是任何可移动驱动器或更多设备。采用真正的双向同步,Always Sync 的算法可以检测你在文件中所做的最新更改,无论是在哪个设备上。通过将数据记录在本地数据库中来确保隐私。它可以免费供个人使用,但有限制。它具有主要功能,例如-
使用 odrive,你可以像使用本地存储的文件一样使用云文件。如果你要对任何文件进行任何更改,这些更改将在云端自动更新。换句话说,在本地文件中所做的更改会自动与云文件同步。
特征:
SyncBack 仅备份基于文件的数据。简而言之,它只备份你创建的文件。但是,你不能克隆包含系统文件的整个驱动器。SyncBack free 是一个 32 位程序,可以使用 2GB 的 RAM。
特征:
OpenDrive 为个人、企业和企业使用提供云存储、备份和同步功能。凭借其对各种操作系统的支持,你可以轻松访问、管理和共享你的数据,而无需担心。
特征:
文件大小: 11 MB
支持的系统: Windows、Mac、Linux、Android、Web、iOS
DirSync Pro是一款免费且功能强大的文件和文件夹同步实用程序。DirSync 支持一个或多个文件夹内容的递归同步。此应用程序的 UI 易于使用,同时为你提供大量选项和功能。DirSync Pro 是用 Java 编写的,这就是它快速且健壮的原因。
特征-
文件大小: 2.8 MB
支持的系统: Windows、Mac OS、Linux、DOS
日常生活中大家都离不开电脑
所以如何自动定时开关电脑大家一定用得上
自动开机需要在 BIOS 里面设置
开机的时候按住 F2 或者 DEL 进入主板设置
然后选择电源选项
假如需要每天都定时开机,就选择Every Day,
如果想要在每天 6:45 开机,
就通过数字键输入06:15:00,
最后,一般按F10 进行保存,重启电脑后生效。
一般的老旧主板就是这种样子的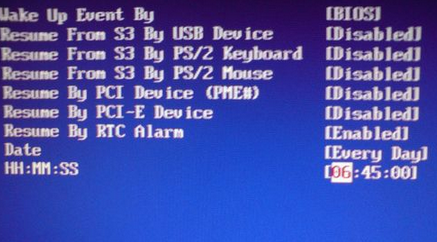
比较新的笔记本或者电脑主板就会有这样的图形化中文界面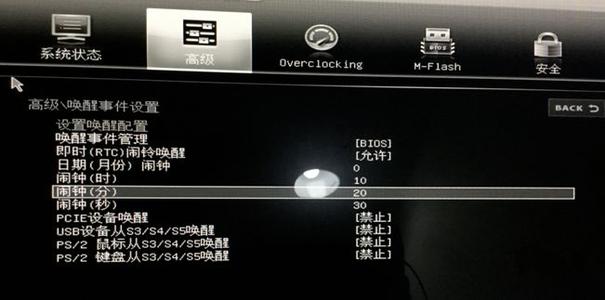
自动开机已经设置好了
这个可以提供计划任务来实现
控制面板上面搜索计划任务就可以看到
创建新的 触发器
根据需要 改为 设置 任务开始时间及每隔多久
如下图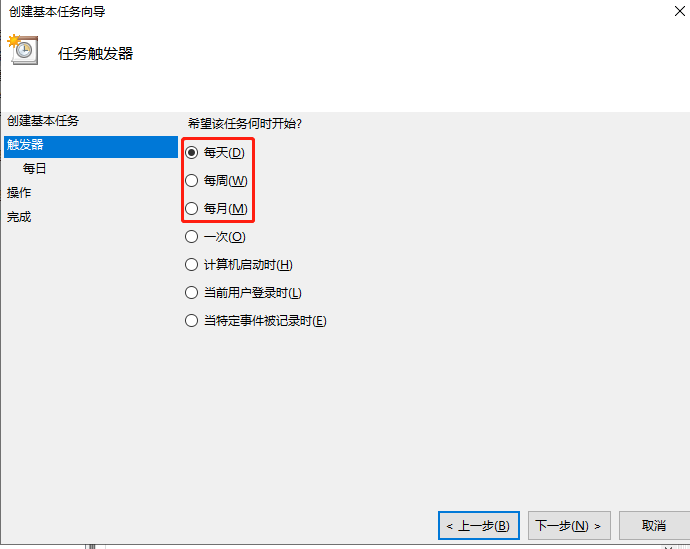
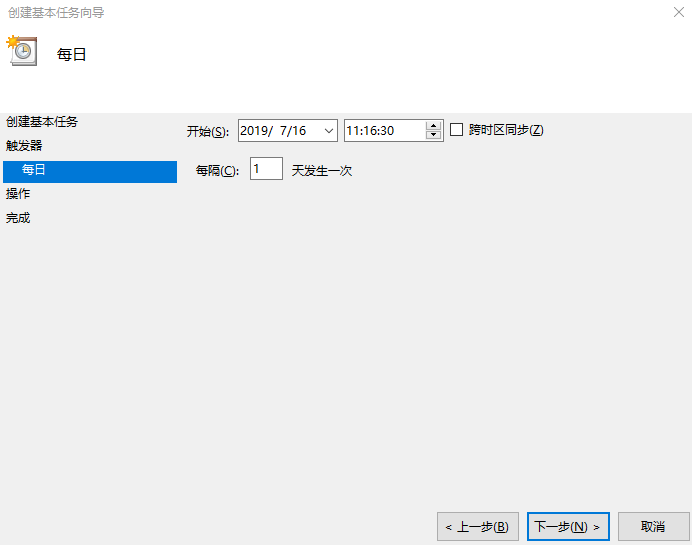
再把 启动程序 选择自动执行的带参数的关机命令
如下图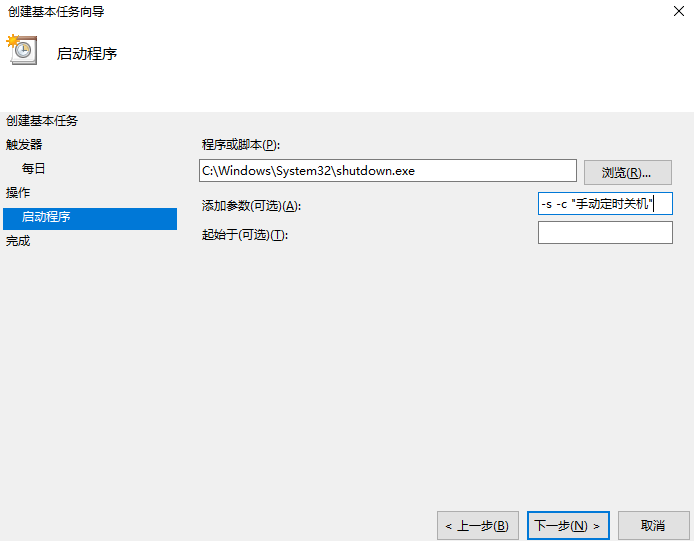
这样就实现了 windows 定时自动开机关机功能